爬取图片信息
1.图片的加载信息只有两种,(个人认为,目前只遇到过两种)
- 同步加载
- 异步加载
2.(1)同步加载,在你返回的数据中可以清晰的看到,你所需要的数据全部都在你所打印的response中,也就是说,可以找到想想要的数据。那么只需要一个简单的模板就可以爬取你想要的数据信息,以及图片信息。
(2)异步加载的话,就是可能无法在你返回的数据当中找到你想要的的数据,所以,我们就是需要从其他包中抓取。XHR就可以查看是否有我们想要的数据包。或者找不到任何有关数据时,我们可以通过,关键字搜索来进行抓包。
3.翻页请求。
1.翻页请求的方式,目前好像也只有两种(个人认为哈)要么是通过按钮的方式,来获取下一页的响应内容,那么在这里我们只需要,不断的变更url的参数请求,就可以不断的获取下一页的请求数据。
另一种,就是没有翻页的按钮,就是不断的通过的下拉不断的进行刷新,那么这一种,就是异步加载的方式,刷新按钮的,没有任何的变化。那么我们应该如何如何获取,包中的数据。
2.在不断的刷新的过程,都会有一个新的数据包产生
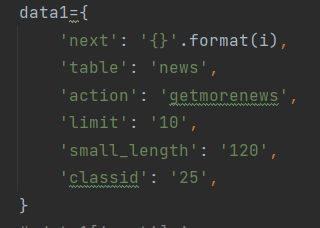
从这里我们可以看到,next就是代表页数,只要不断的变更,翻页请求就能得到响应。
4.下面是简单的模板爬取方式。
#t同步加载
import requests
import os
from lxml import etree
headers = {
#可修改
}
def get():
response = requests.request("GET", url, headers=headers)
response.encoding = response.apparent_encoding
# print(response.text)
html_data = response.text
return html_data
def parse(data):
xml = etree.HTML(data)
name = xml.xpath('//div[@class="title"]/span/a/text()')#可修改
img_src = xml.xpath('//img[@class="lazy"]/@data-original')#可修改
# print(img_src)
for n, i in zip(name, img_src):
print(n)
print(i)
print('===' * 10)
save(n, i)
def save(n, i):
img_data = requests.get(i).content#获取图片二进制数据
if not os.path.exists(''):
os.makedirs('')
with open('(保存文件夹名称)/{}.jpg'.format(n), 'wb') as f:
f.write(img_data)
if __name__ == '__main__':
for i in range(1, 3):
url = "".format(i)
print('正在下载第{}页'.format(i))
print('当前url为:', url)
html_data = get()
parse(html_data)
’
#异步加载
import requests
from bs4 import BeautifulSoup
import time
import os
from lxml import etree
payload = "next=1&table=news&action=getmorenews&limit=10&small_length=120&classid=25"#可修改
headers = {
#可修改
}
def get_data():
response=requests.post(url,headers=headers,data=data1,json=payload)
html_data=response.text
return html_data
# print(html_data)
def parse_data(data):
xml=etree.HTML(data)
img=xml.xpath('//ul[@class="pic-list after"]//a/img/@src')
name=xml.xpath('//ul[@class="pic-list after"]//a/span/text()')
for i,n in zip(img,name):
print(i)
print(n)
print('=='*10)
save_data(i,n)
def save_data(i,n):
with open('a.txt','a',encoding='utf-8')as f:
f.write(i+'\n')
f.write(n+'\n')
img_data=requests.post(i).content
if not os.path.exists('a'):
os.makedirs('a')
with open('a/{}.jpg'.format(n),'wb')as f:
f.write(img_data)
if __name__=='__main__':
url = 'https://www.umei.cc/e/action/get_img_a.php'
for i in range(1,11):
print('==正在打印参数为{}的页面=='.format(i))
data1={#每个页面的请求数据
'next': '{}'.format(i),
'table': 'news',
'action': 'getmorenews',
'limit': '10',
'small_length': '120',
'classid': '25',
}
# data1['next']=i
html_data=get_data()
parse_data(html_data)
#如果想要爬取其他页面信息的话,这个小小的模板的可能适用。。
小白新尝,不喜勿喷。。老司机,就不要讲话啦。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号