scrapy爬取网站图片(静态加载)
1.创建一个scrapy项目
scrapy startgproject tupian
cd tupian
创建爬虫文件 scrapy genspider Image www.com(域名)后续需要更改
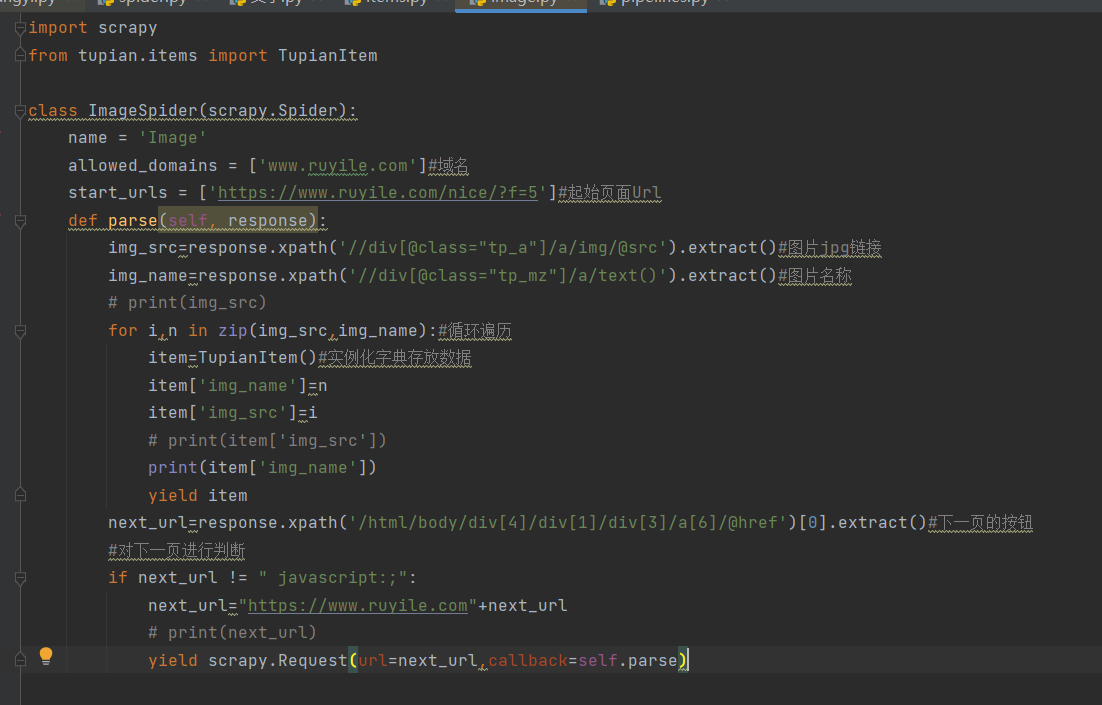
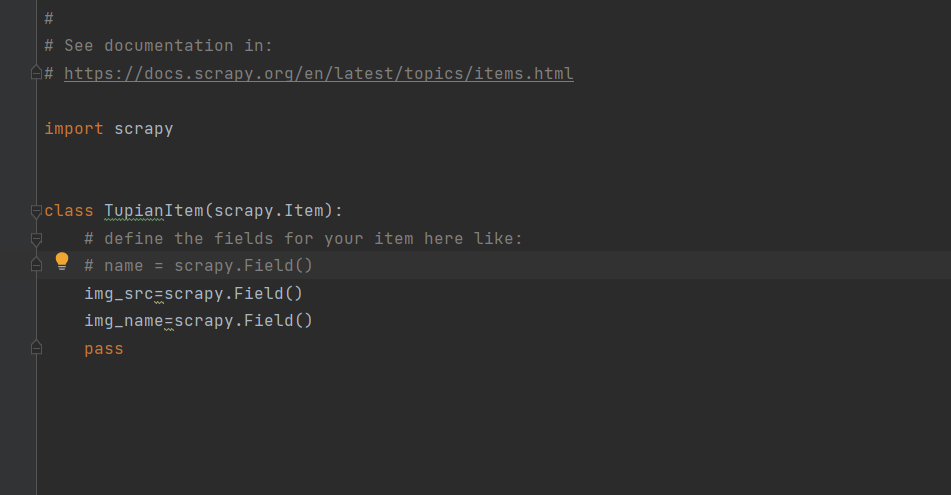
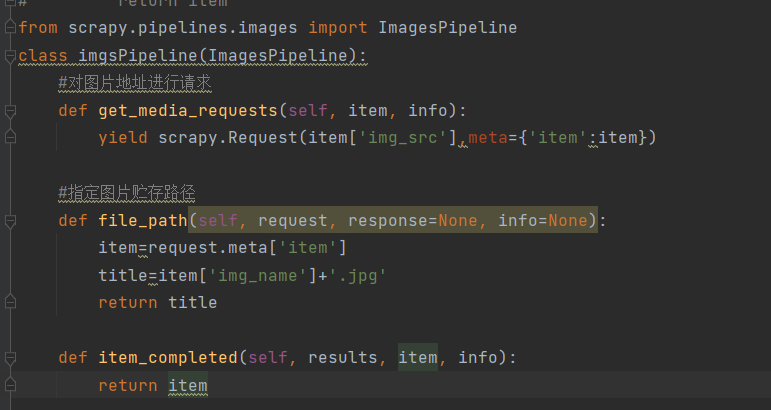
开通pip管道是需要注意,我们将之前的类注释了,所以我们需要将原来的pip管道的名称加以修改
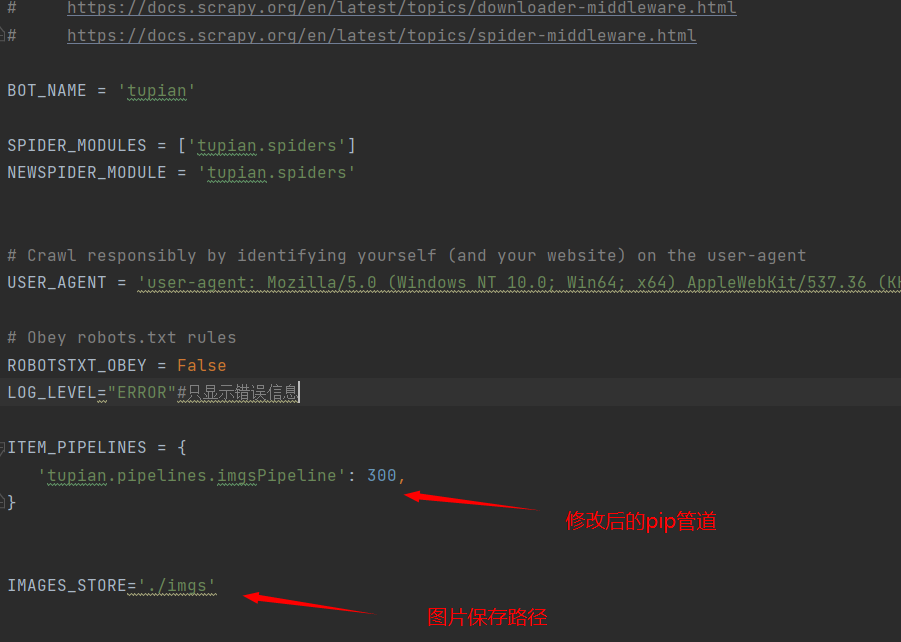
在终端运行就可以获取数据,
运行后会出现错误是因为将所有的数据都爬取下来了,可以在后面弄个判断。
到这里就没了,拜拜!!
scrapy startgproject tupian
cd tupian
创建爬虫文件 scrapy genspider Image www.com(域名)后续需要更改
开通pip管道是需要注意,我们将之前的类注释了,所以我们需要将原来的pip管道的名称加以修改
在终端运行就可以获取数据,
运行后会出现错误是因为将所有的数据都爬取下来了,可以在后面弄个判断。
到这里就没了,拜拜!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号