解决爬中文打印出乱码得问题
如下图,爬取标题,标题为中文内容,打印出乱码
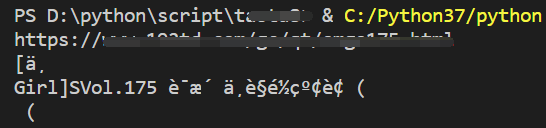
解决方法,需要对请求后得返回数据重新编码
response = requests.get(url=url2) response.encoding = 'utf-8' #处理编码得步骤 print(url2) wb_data = response.text # 将页面转换成文档树 html = etree.HTML(wb_data) b = html.xpath('//div[@class = "picmainer"]/h1/text()') b=(b[0]) print(b)
response.encoding = 'utf-8'
![]()

内容正常显示了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号