JUC学习8 JMM Volatile
JMM
什么是JMM
JMM: Java内存模型 不存在的东西 概念 约定
关于JMM的一些同步的约定
1.线程解锁前,必须把共享变量立刻刷回主存
2.线程加锁前,必须读取主存中的最新值到工作内存中
3.加锁和解锁是同一把锁
线程 工作内存,主内存
8种操作
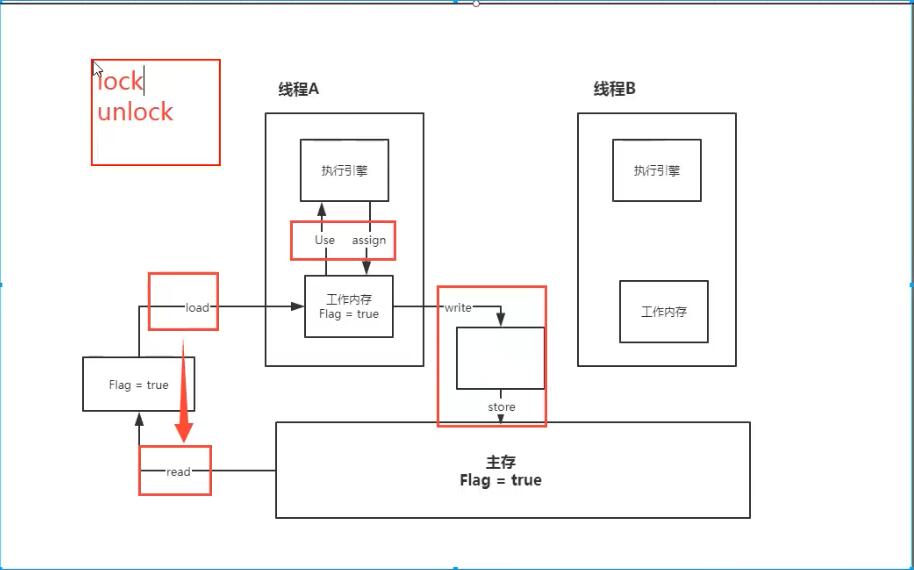
内存交互操作有8种,虚拟机实现必须保证每一个操作都是原子的,不可在分的(对于double和long类型的变量来说,load、store、read和write操作在某些平台上允许例外)
- lock (锁定):作用于主内存的变量,把一个变量标识为线程独占状态
- unlock (解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定
- read (读取):作用于主内存变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用
- load (载入):作用于工作内存的变量,它把read操作从主存中变量放入工作内存中
- use (使用):作用于工作内存中的变量,它把工作内存中的变量传输给执行引擎,每当虚拟机遇到一个需要使用到变量的值,就会使用到这个指令
- assign (赋值):作用于工作内存中的变量,它把一个从执行引擎中接受到的值放入工作内存的变量副本中
- store (存储):作用于主内存中的变量,它把一个从工作内存中一个变量的值传送到主内存中,以便后续的write使用
- write (写入):作用于主内存中的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中
JMM对这八种指令的使用,制定了如下规则:
- 不允许read和load、store和write操作之一单独出现。即使用了read必须load,使用了store必须write
- 不允许线程丢弃他最近的assign操作,即工作变量的数据改变了之后,必须告知主存
- 不允许一个线程将没有assign的数据从工作内存同步回主内存
- 一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是怼变量实施use、store操作之前,必须经过assign和load操作
- 一个变量同一时间只有一个线程能对其进行lock。多次lock后,必须执行相同次数的unlock才能解锁
- 如果对一个变量进行lock操作,会清空所有工作内存中此变量的值,在执行引擎使用这个变量前,必须重新load或assign操作初始化变量的值
- 如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量
- 对一个变量进行unlock操作之前,必须把此变量同步回主内存
Volatile
Volatile 是Java虚拟机提供的轻量级的同步机制
保证可见性
public class VolatileTest {
// 不加 volatile 程序就会死循环
// 加 volatile 保证可见性
static volatile int num = 0;
public static void main(String[] args) {
new Thread(() -> { // 线程1对主内存的变化是不知道的
while (num == 0) {
}
}).start();
try {
TimeUnit.SECONDS.sleep(2);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(num);
num = 1;
System.out.println(num);
}
}
不保证原子性
原子性: 不可分割
线程A再执行任务的时候不能被打扰也不能被分割 要么同时成功要么同时失败
如果不加lock或synchroized 怎样保证原子性
使用原子类解决原子性问题
public class VolatileTest2 {
// volatile 不保证原子性
// static volatile int num = 0;
static volatile AtomicInteger num = new AtomicInteger();
static void add() {
// num++;// 不是一个原子性操作
num.getAndIncrement();// 执行+1操作
}
public static void main(String[] args) {
for (int i = 1; i <= 20; i++) {
new Thread(() -> { // 线程1对主内存的变化是不知道的
for (int i1 = 0; i1 < 1000; i1++) {
add();
}
}).start();
}
while (Thread.activeCount() > 2) {
Thread.yield();
}
System.out.println(Thread.currentThread().getName() + "=======" + num);
}
}
这些类的底层都直接和操作系统挂钩 在内存中修改值 unsafe类是一个很特殊的存在
禁止指令重拍
狂神版讲解:
什么是指令重排: 计算机并不是按照你写的那样去执行的
源代码 -> 编译器优化重拍 -> 指令并行也可能重排 -> 内存系统也会重排 -> 执行
处理器在进行指令重排的时候 会考虑数据之间的依赖性
可能造成影响的结果 a,b,x,y = 0;
| 线程A | 线程B |
|---|---|
| x=a | y=b |
| b=1 | a=2 |
正常结果 x=0 y=0 但是可能由于指令重排 变为
| 线程A | 线程B |
|---|---|
| b=1 | a=2 |
| x=a | y=b |
指令重排导致的诡异结果 x=2 y=1
博客大佬讲解
java代码是否一定按顺序执行?
这个问题听起来有点蠢,串行的代码确实会按代码语意正确的执行,但是编译器对于代码本身的优化却并不一定会按实际的代码一步一步的执行。
比如:
r1=a;
r2=r1.x;
r3=r1.x;
编译器则可能会进行优化,将r3=r1.x这条指令替换成r3=r2,这就是指令的重排
编译器为什么要做指令的重排呢?
地球人都知道,当然是出于性能上的考虑,而指令重排能提升多少性能?
首先指令的执行可以分为这几步:
- 取指 IF
- 译码和取寄存器操作数 ID
- 执行或者有效地址计算 EX (ALU逻辑计算单元)
- 存储器访问 MEM
- 写回 WB (寄存器)
详见:https://blog.csdn.net/fuhanghang/article/details/83421254
而一段代码并不是由单条指令就可以执行完毕的,而是通过流水线来执行多条指令。
流水线技术是一种将指令分解为多步,并让不同指令的各步操作重叠,从而实现几条指令并行处理。
指令1 IF ID EX MEN WB
指令2 IF ID EX MEN WB
指令的每一步都由不同的硬件完成,假设每一步耗时1ms,执行完一条指令需耗时5ms,
每条指令都按顺序执行,那两条指令则需10ms。
但是通过流水线在指令1刚执行完IF,执行IF的硬件立马就开始执行指令2的IF,这样指令2只需要等1ms,两个指令执行完只需要6ms,效率是不是提升巨大!
先记住几个指令:
MIPS汇编指令集---https://www.cnblogs.com/yanghong-hnu/p/5635245.html
LW(加载数据到寄存器的指令)
ADD(两个定点寄存器的内容相加)
SUB(相减)
SW(把数据从寄存器存储到存储器)
现在来看一下代码 A=B+C 是怎么执行的
现有R1,R2,R3三个寄存器,
LW R1,B IF ID EX MEN WB(加载B到R1中)
LW R2,C IF ID EX MEN WB(加载C到R2中)
ADD R3,R2,R1 IF ID × EX MEN WB(R1,R2相加放到R3)
SW A,R3 IF ID x EX MEN WB(把R3 的值保存到变量A)
在ADD指令执行中有个x,表示中断、停顿,ADD为什么要在这里停顿一下呢?因为这时C还没加载到R2中,只能等待,而这个等待使得后边的所有指令都会停顿一下。
这个停顿可以避免吗?
当然是可以的,通过指令重排就可以实现,再看一下下面的例子:
要执行
A=B+C;
D=E-F;
通过将D=E-F执行的指令顺序提前,从而消除因等待加载完毕的时间。
LW Rb,B IF ID EX MEN WB
LW Rc,C IF ID EX MEN WB
LW Re,E IF ID EX MEN WB
ADD Ra,Rb,Rc IF ID EX MEN WB
LW Rf,F IF ID EX MEN WB
SW A,Ra IF ID EX MEN WB
SUB Rd,Re,Rf IF ID EX MEN WB
SW D,Rd IF ID EX MEN WB
地址 : https://www.cnblogs.com/xdecode/p/8948277.html
ps: 道理我懂了 具体实现有点看不懂 等待后续研究
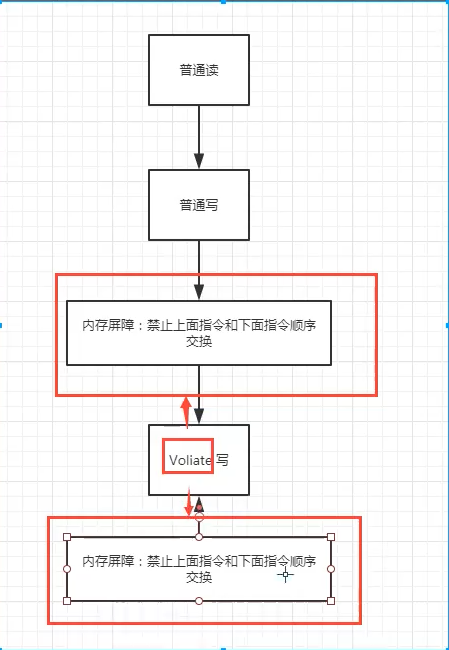
volatile 可以避免指令重排:
内存屏障 CPU指令 作用:
保证特定的操作的执行顺序
可以保证某些变量的内存可见性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号