

hadoop完全分布式安装(centos)
概述
一主两从(centos7)
10.10.0.100 master (namenode)
10.10.0.101 slave1 (datanode)
10.10.0.102 slave2 (datanode)
真机(win7)
10.10.0.1
一、安装vmware
1、设置网络
(1)、设置虚拟机链接方式为NAT方式
子网为:10.10.0.0,子网掩码为:255.255.255.0,网关为:10.10.0.254
(2)、真机VMnet8(真机和虚拟机NAT连接的专用网卡)网卡的ip地址为10.10.0.1,子网掩码为:255.255.255.0,网关为:10.10.0.254
2、新建虚拟机
安装centos7(纯净,以后实验备用)
问题:
ip addr查不到IP地址,重启网络服务时会出现“Failed to start LSB: Bring up/down”网络报错
解决:
禁用NetworkManager
(1)systemctl stop NetworkManager
(2)systemctl disable NetworkManager
重启之后,网络恢复正常
二、master节点的安装与设置
1、完整克隆出master
关闭防火墙
$>systemctl stop firewalld //临时关闭,或systemctl stop firewalld.service
$>systemctl status firewalld //查看防火墙状态,或firewall-cmd --state
$>systemctl disable firewalld //永久关闭
2、设置ip
$>vi /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO=static //静态IP
ONBOOT=yes //开机启动
IPADDR=10.10.0.100 //IP地址
GATEWAY=10.10.0.254 //网关
NETMASK=255.255.255.0 //子网掩码
DNS1=8.8.8.8 //上外网
#修改完成后,重启网络使用ip生效:
$>service network restart
$>ping 10.10.0.1 //测试与真机的联通性
3、修改DNS以便上外网
(1)设置不通过网络管理器管理DNS
$>vi /etc/NetworkManager/NetworkManager.conf
添加:dns=none
(2)新增DNS
$>vi /etc/resolv.conf
添加:nameserver=10.10.0.254 //和网关保持一致,就类似虚拟机master和真机同接一个路由器一样,这样就共享上外网了
$>ping www.qq.com //进行外网联通测试
配置yum源
(1)备份
cp /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
(2)下载
下载新的 http://mirrors.aliyun.com/repo/Centos-7.repo,并命名为CentOS-Base.repo
(3)清除缓存
yum clean all # 清除系统所有的yum缓存
yum makecache # 生成yum缓存
4、安装vim便于快速编辑文本
$>rpm -qa|grep vim //查找是否安装了vim
$>yum -y install vim* //安装vim,需要连接外网
5、修改主机名
$>vim /etc/hostname
master
6、修改hosts文件
$>vim /etc/hosts
10.10.0.100 master
10.10.0.101 slave1
10.10.0.102 slave2
三、安装辅助工具
1、安装文件上传、下载工具
说明:宿主机和虚拟机之间传递文件
rz、sz命令
安装:yum install -y lrzsz
rz是上传命令,linux中执行后,可打开文件对话框,选择宿主机中的文件上传到虚拟机。
sz是下载文件,sz <文件名>就可以将linux虚拟机中的文件发送到宿主机。
2、安装SSH工具
xshell(远程登录虚拟机更方便操作)
四、安装jdk
1、安装
下载jdk,并通过rz传入master虚拟机,解压即可。
(1)事先创建目录,命令:mkdir -p /home/hadoop/download ,说明:download专门放下载的安装包(jdk、hadoop、hbase等),安装于hadoop目录下。
(2)解压:tar -zxvf /home/hadoop/download/jdk-8u181-linux-x64.tar.gz -C /home/hadoop/
2、配置
$>vim /etc/profile(编辑配置文件)
添加:
export JAVA_HOME=/home/hadoop/jdk1.8.0_181
export CLASSPATH=$JAVA_HOME/lib:$CLASSPATH
export PATH=$PATH:$JAVA_HOME/bin
$>source /etc/profile //编译生效
五、安装hadoop
1、安装
解压命令:tar -zxvf /home/hadoop/download/hadoop-2.7.3.tar.gz -C /home/hadoop/
2、配置
(1)配置环境变量
$>vim /etc/profile
export JAVA_HOME=/home/hadoop/jdk1.8.0_181
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3
export CLASSPATH=$JAVA_HOME/lib:$CLASSPATH
export PATH=.:$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP/sbin
$>source /etc/profile
(2)编辑slaves文件
进入hadoop配置文件所在目录:cd /home/hadoop/hadoop-2.7.3/etc/hadoop/
$>vim slaves
slave1
slave2
说明:将datanode的主机名写入该文件,删除原来的localhost,让master仅作为namenode用
(3)编辑core-site.xml文件
vim core-site.xml


1 <configuration> 2 <property> 3 <name>fs.defaultFS</name> 4 <value>hdfs://master:9000</value> 5 </property> 6 7 <property> 8 <name>hadoop.tmp.dir</name> 9 <!-- 该临时目录主要存放secondaryNameNode的一些数据,如:fsimage、edit这样数据是为了恢复NameNode节点而准备的 --> 10 <value>/home/hadoop/hadoop-2.7.3/tmp</value> 11 </property> 12 </configuration>
说明:事先要创建tmp目录
(4)编辑hdfs-site.xml文件
vim hdfs-site.xml
1 <configuration> 2 <property> 3 <name>dfs.namenode.secondary.http-address</name> 4 <value>master:9001</value> 5 <!-- 通过web方式查看secondaryNameNode节点的状态 --> 6 </property> 7 8 <property> 9 <name>dfs.replication</name> 10 <!--DataNode的副本数--> 11 <value>2</value> 12 </property> 13 14 <property> 15 <name>dfs.namenode.name.dir</name> 16 <value>/home/hadoop/hadoop-2.7.3/hdfs/name</value> 17 </property> 18 19 <property> 20 <name>dfs.datanode.data.dir</name> 21 <value>/home/hadoop/hadoop-2.7.3/hdfs/data</value> 22 </property> 23 </configuration>
说明:需要创建hdfs目录,但不需要创建其下的name和data,格式化后会自动创建这两目录。
(5)编辑yarn-site.xml文件
如果修改后一定要复制到其它节点,其它配置文件也是如此。
vim yarn-site.xml
1 <configuration> 2 <property> 3 <name>yarn.nodemanager.aux-services</name> 4 <value>mapreduce_shuffle</value> 5 </property> 6 7 <property> 8 <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> 9 <value>org.apache.hadoop.mapred.ShuffleHandler</value> 10 </property> 11 12 <property> 13 <name>dfs.resourcemanager.hostname</name> 14 <value>master</value> 15 </property> 16 17 <property> 18 <name>yarn.resourcemanager.address</name> 19 <value>master:8032</value> 20 </property> 21 22 <property> 23 <name>yarn.resourcemanager.scheduler.address</name> 24 <value>master:8030</value> 25 </property> 26 27 <property> 28 <name>yarn.resourcemanager.resource-tracker.address</name> 29 <value>master:8031</value> 30 </property> 31 </configuration>
(6)编辑mapred-site.xml文件
重命名:mv mapred-site.xml.template mapred-site.xml
编辑:vim mapred-site.xml
1 <configuration> 2 <property> 3 <name>mapreduce.framework.name</name> 4 <value>yarn</value> 5 <final>true</final> 6 </property> 7 8 <property> 9 <name>mapreduce.jobhistory.address</name> 10 <value>master:10020</value> 11 </property> 12 13 <property> 14 <name>mapreduce.jobhistory.webapp.address</name> 15 <value>master:19888</value> 16 </property> 17 </configuration>
(7)编辑hadoop-env.sh
vim hadoop-env.sh
export JAVA_HOME=/home/hadoop/jdk1.8.0_181
(8)编辑yarn-env.sh
vim yarn-env.sh
export JAVA_HOME=/home/hadoop/jdk1.8.0_181
六、完整克隆master为slave1、slave2
1、修改slave1的ip
$>vim /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR=10.10.0.101(IP地址)
2、修改slave1的主机名
$>vim /etc/hostname
slave1
3、修改slave2的ip
$>vim /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR=10.10.0.102(IP地址)
4、修改slave2的主机名
$>vim /etc/hostname
slave2
七、集群ssh免密登录
以master为例
1、生成密钥
$>ssh-keygen -P ""
在/root/.ssh目录下可以看到有authorized_keys、id_rsa、id_rsa.pub三个文件
2、复制公钥
将master的公钥id_rsa.pub复制到master、slave1、slave2的authorized_keys
(1)ssh-copy-id master //登录测试:ssh master//退出:exit
(2)ssh-copy-id slave1
(3)ssh-copy-id slave2
slave1和slave2重复上述步骤2
八、启动hadoop
第一次启动需要格式化:hdfs namenode -format
启动:start-all.sh(相当于start-hdfs.sh和start-yarn.sh)
查看master进程:jps
Jps、NameNode、SecondaryNameNode、ResourceManager
查看slave1进程:jps
Jps、DataNode、NodeManager
真机浏览器访问hadoop
http://10.10.0.100:50070 //50070是namenode默认的端口号
查看节点的情况:http://10.10.0.100:8088 //8088是ResourceManager默认的端口号
运行wordcount:
1、在hdfs上新建目录
hdfs dfs -mkdir -p /input/wordcount(输入目录)
hdfs dfs -mkdir -p /output/wordcount(输出目录)
2、新建2个文本文件txt1、txt2并传入hdfs,作为运行所需要的数据
hdfs dfs -put /tmp/txt* /input/wordcount
3、运行hadoop自带的wordcount程序
hadoop jar /home/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input/wordcount /output/wordcount
4、观察结果:hdfs dfs -ls output/wordcount
zookeeper
1、安装
进入download目录:cd /home/hadoop/download/
解压:tar -zxvf zookeeper-3.4.9 -C ..(..为父目录即hadoop)
2、配置
(1)配置环境变量
export ZOOKEEPER_HOME=/home/hadoop/zookeeper-3.4.9
export PATH=$PATH:$ZOOKEEPER_HOME/bin(在末尾加zookeeper的bin路径)
(2)配置zoo.cfg
先创建文件夹:
$>mkdir -p /home/hadoop/zookeeper-3.4.9/data
$>mkdir -p /home/hadoop/zookeeper-3.4.9/log
复制zoo_sample.cfg:
$>cd /home/hadoop/zookeeper-3.4.9/conf
$>cp zoo_sample.cfg zoo.cfg
$>vim zoo.cfg
dataDir=/home/hadoop/zookeeper-3.4.9/data
dataLogDir=/home/hadoop/zookeeper-3.4.9/log
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
(3)创建myid文件
在dataDir对应的目录下创建myid并输入内容:
$>cd /home/hadoop/zookeeper-3.4.9/data
$>echo '1' >myid
(4)复制zookeeper-3.4.9到slave1、slave2
scp -r /home/hadoop/zookeeper-3.4.9 slave1:/home/hadoop/
修改slave1的data目录下myid为2
vim /home/hadoop/zookeeper-3.4.9/data/myid
2
scp -r /home/hadoop/zookeeper-3.4.9 slave2:/home/hadoop/
修改slave2的data目录下myid为3
vim /home/hadoop/zookeeper-3.4.9/data/myid
3
3、启动
在三台机器上分别启动zkServer
$>/home/hadoop/zookeeper-3.4.9/bin/zkServer.sh start
查看进程:jps
2225 NameNode
3889 Jps
2564 ResourceManager
3048 QuorumPeerMain(增加)
2413 SecondaryNameNode
查看状态:zkServer.sh status
hbase
1、安装
进入download目录:cd /home/hadoop/download/
解压:tar -zxvf hbase-1.2.3 -C ..(..为父目录即hadoop)
2、配置
(1)配置环境变量
$>vim /etc/profile
export HBASE_HOME=/home/hadoop/hbase-1.2.3
末尾添加bin到path:
:$HBASE_HOME/bin
$>source /etc/profile
(2)配置hbase-env.sh
进入配置目录:cd /home/hadoop/hbase-1.2.3/conf
$>vim hbase-env.sh
export JAVA_HOME=/home/hadoop/jdk1.8.0_181
export HBASE_MANAGES_ZK=false
(3)配置hbase-site.xml
vim hbase.site.xml
1 <configuration> 2 <property> 3 <name>hbase.rootdir</name> 4 <value>hdfs://master:9000/hbase</value> 5 </property> 6 7 <property> 8 <name>hbase.cluster.distributed</name> 9 <value>true</value> 10 </property> 11 12 <property> 13 <name>hbase.zookeeper.quorum</name> 14 <value>master,slave1,slave2</value> 15 </property> 16 17 <property> 18 <name>hbase.zookeeper.property.dataDir</name> 19 <value>/home/hadoop/zookeeper-3.4.9</value> 20 </property> 21 </configuration>
(4)配置regionservers
$>vim regionservers
slave1
slave2
说明:regionservers文件中列出了你希望运行的HRegionServer
(5)复制hbase-1.2.3到slave1、slave2
$>scp -r /home/hadoop/hbase-1.2.3 slave1:/home/hadoop
$>scp -r /home/hadoop/hbase-1.2.3 slave2:/home/hadoop
3、启动
启动之前先要启动hadoop集群
启动zookeeper(zkServer.sh start),注意:三台都要启动
(1)启动hbase
$>/home/hadoop/hbase-1.2.3/bin/start-hbase.sh
查看master进程:jps
2225 NameNode
2564 ResourceManager
4245 Jps
4070 HMaster(启动hbase增加的)
3048 QuorumPeerMain(启动zookeeper增加的)
2413 SecondaryNameNode
查看slave进程:jps
2057 DataNode
2749 HRegionServer(启动hbase增加的)
2367 QuorumPeerMain(启动zookeeper增加的)
2895 Jps
在浏览器中输入http://master:16010就可以在界面上看到hbase的配置了
(2)启动hbase shell
hbase shell
注:退出hbase shell:exit
关闭hbase:stop-hbase.sh
4、Java访问Hbase
新建Maven项目
1、pom.xml
1 <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common --> 2 <dependency> 3 <groupId>org.apache.hadoop</groupId> 4 <artifactId>hadoop-common</artifactId> 5 <version>2.7.3</version> 6 </dependency> 7 <!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client --> 8 <dependency> 9 <groupId>org.apache.hbase</groupId> 10 <artifactId>hbase-client</artifactId> 11 <version>1.2.3</version> 12 </dependency>
2、MyConnection.java(数据类连接类)
1 package com.zyz; 2 3 import org.apache.hadoop.hbase.HBaseConfiguration; 4 import org.apache.hadoop.hbase.client.Connection; 5 import org.apache.hadoop.hbase.client.ConnectionFactory; 6 7 public class MyConnection { 8 9 public static Connection getConnection() throws Exception { 10 org.apache.hadoop.conf.Configuration configuration = null; 11 org.apache.hadoop.hbase.client.Connection connection = null; 12 configuration = HBaseConfiguration.create(); 13 configuration.set("hbase.zookeeper.quorum", "10.10.0.100");//zookeeper主机 14 configuration.set("hbase.zookeeper.property.clientPort", "2181");// zookeeper端口 15 connection = ConnectionFactory.createConnection(configuration); 16 return connection; 17 } 18 }
3、Test2.java(查询)
1 package com.zyz; 2 3 import org.apache.hadoop.hbase.KeyValue; 4 import org.apache.hadoop.hbase.TableName; 5 import org.apache.hadoop.hbase.client.Connection; 6 import org.apache.hadoop.hbase.client.Result; 7 import org.apache.hadoop.hbase.client.ResultScanner; 8 import org.apache.hadoop.hbase.client.Scan; 9 import org.apache.hadoop.hbase.client.Table; 10 11 /** 12 * 查询hbase中的表 13 * @author zyz 14 * 15 */ 16 public class Test2 { 17 18 @SuppressWarnings("deprecation") 19 public static void main(String[] args) { 20 try { 21 Connection connection = MyConnection.getConnection(); 22 Table table = connection.getTable(TableName.valueOf("student1"));//获得hbase中表student1 23 ResultScanner rs = table.getScanner(new Scan());//全表扫描 24 for (Result result : rs) {//遍历,result为每一行数据 25 for (KeyValue kv : result.raw()) {//处理每一行,输出每一列 26 System.out.print(new String(kv.getRow()) + " ");//行键 27 System.out.print(new String(kv.getFamily()) + ":");//列族 28 System.out.print(new String(kv.getQualifier()) + " = ");//列 29 System.out.print(new String(kv.getValue()));//值 30 System.out.print(" timestamp = " + kv.getTimestamp() + "\n");//时间戳 31 } 32 } 33 rs.close(); 34 table.close(); 35 connection.close(); 36 } catch (Exception e) { 37 e.printStackTrace(); 38 } 39 40 41 } 42 43 }
4、Test3.java(插入)
1 package com.zyz; 2 3 import org.apache.hadoop.hbase.TableName; 4 import org.apache.hadoop.hbase.client.Connection; 5 import org.apache.hadoop.hbase.client.Put; 6 import org.apache.hadoop.hbase.client.Table; 7 import org.apache.hadoop.hbase.util.Bytes; 8 9 /** 10 * 向hbase表中插入一行数据 11 * @author zyz 12 * 13 */ 14 public class Test3 { 15 16 @SuppressWarnings("deprecation") 17 public static void main(String[] args) { 18 try { 19 Connection connection=MyConnection.getConnection(); 20 Table table=connection.getTable(TableName.valueOf("student1")); 21 //构造待插入的行 22 Put put1=new Put(Bytes.toBytes("James"));//根据rowkey构造一行 23 put1.add(Bytes.toBytes("name"),Bytes.toBytes("fname"),Bytes.toBytes("LeBron"));//向行中添加值(列族,列,值) 24 put1.add(Bytes.toBytes("name"),Bytes.toBytes("lname"),Bytes.toBytes("James")); 25 put1.add(Bytes.toBytes("contact"),Bytes.toBytes("email"),Bytes.toBytes("James@gmail.com")); 26 27 table.put(put1);//向表中添加一行 28 table.close(); 29 connection.close(); 30 System.out.println("over..."); 31 } catch (Exception e) { 32 e.printStackTrace(); 33 } 34 35 } 36 37 }
hive
1、安装
tar -zxvf /home/hadoop/download/apache-hive-2.1.0-bin.tar.gz ..
2、配置
(1)配置环境变量:vim /etc/profile
export $HIVE_HOME=/home/hadoop/apache-hive-2.1.0-bin
添加path::$HIVE_HOME/bin
重新编译:source /etc/profile
测试:hive --version
(2)修改hive-site.xml(在conf目录下)
1 <property> 2 <name>javax.jdo.option.ConnectionURL</name> 3 <value>jdbc:mysql://10.10.0.1:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value> 4 </property> 5 <property> 6 <name>javax.jdo.option.ConnectionDriverName</name> 7 <value>com.mysql.jdbc.Driver</value> 8 </property> 9 <property> 10 <name>javax.jdo.option.ConnectionUserName</name> 11 <value>root</value> 12 </property> 13 <property> 14 <name>javax.jdo.option.ConnectionPassword</name> 15 <value>root</value> 16 </property>
说明:
本配置主要是将数据库的元信息保存在关系型数据库mysql中,默认是保存在derby数据库。
真机(win7)上安装mysql服务,用户名:root 密码:root ,最好在真机的mysql数据库上创建hive数据库,保存hive中创建的所有数据库的元信息,如果不创建的话,配置为自动创建。
下载mysql驱动mysql-connector-java-5.1.44.jar到hive目录下的子目录lib中。
(3)初始化mysql元数据
schematool -dbType mysql -initSchema
本地安装mysql
首先下载mysql的rpm文件,下载地址:https://dev.mysql.com/downloads/repo/yum/
rpm -Uvh mysql57-community-release-el7-11.noarch.rpm #添加mysql仓库
yum install -y mysql-community-server --nogpgcheck #安装mysql,跳过公钥检查
service mysqld start #启动mysql服务或systemctl start mysqld.service
grep 'temporary password' /var/log/mysqld.log #获得mysql初始密码
mysql -uroot -peejVY2MLgS+e #使用初始密码登录
mysql>set global validate_password_length=0; #密码最小长度策略
mysql>set global validate_password_policy=0; #密码强度检查等级策略,0/LOW、1/MEDIUM、2/STRONG
mysql> set password for 'root'@'localhost' = password('root'); #修改本地root密码
mysql>GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root123' WITH GRANT OPTION; #开启mysql的root用户远程连接服务
mysql>flush privileges;
/sbin/iptables -I INPUT -p tcp --dport 3306 -j ACCEPT #开启mysql端口服务
service network restart
3、启动
(1)先启动hdfs
$HADOOP_HOME/sbin/start-all.sh
(2)启动hive
hive
4、使用hiveserver2连接hive
(1)下载并复制jdbc的连接jar包
如:mysql-connector-java-5.1.47.jar,将其复制$HIVE_HOME/lib中
(2)修改core-site.xml
hive2新加了权限,需修改hadoop的配置文件
[$HADOOP_HOME/etc/hadoop/core-site.xml]
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
#说明:root是操作hadoop的用户
主要原因是hadoop引入了一个安全伪装机制,使得hadoop 不允许上层系统直接将实际用户传递到hadoop层,而是将实际用户传递给一个超级代理,由此代理在hadoop上执行操作,避免任意客户端随意操作hadoop
(3)启动hiveserver2
(a)启动
$>$HIVE_HOME/bin/hiveserver2 & //在后台运行
$>jobs //查看作业
$>netstat -ano | grep 10000 //hiveserver2的端口为10000
说明:若要停止hiveserver2,可使用命令:hiveserver2 stop。若还不行,则杀死进程:kill -9 <pid>
(b)使用beeline连接hiveserver2
$>beeline -u jdbc:hive2://localhost:10000/mydb -n root -proot
说明:$HIVE_HOME/lib下需要hive-jdbc-2.1.0-standalone.jar
(c)使用java连接hive
URL:jdbc:hive2://10.10.0.100:10000/mydb
user:root
password:root
5、Java访问hive
1 <!-- https://mvnrepository.com/artifact/org.apache.hive/hive-jdbc --> 2 <dependency> 3 <groupId>org.apache.hive</groupId> 4 <artifactId>hive-jdbc</artifactId> 5 <version>2.1.0</version> 6 </dependency> 7 8 <!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java --> 9 <dependency> 10 <groupId>mysql</groupId> 11 <artifactId>mysql-connector-java</artifactId> 12 <version>5.1.44</version> 13 </dependency>
2、DB.java
1 package com.zyz; 2 3 import java.sql.Connection; 4 import java.sql.DriverManager; 5 6 public class DB { 7 public static Connection getConnection() { 8 Connection connection=null; 9 try { 10 Class.forName("org.apache.hive.jdbc.HiveDriver"); 11 connection=DriverManager.getConnection("jdbc:hive2://10.10.0.100:10000/db2", "root", "root"); 12 System.out.println("数据库连接成功..."); 13 } catch (Exception e) { 14 System.out.println("数据库连接错误..."); 15 e.printStackTrace(); 16 } 17 return connection; 18 } 19 }
3、Test1.java(查询)
1 package com.zyz; 2 3 import java.sql.Connection; 4 import java.sql.ResultSet; 5 import java.sql.SQLException; 6 import java.sql.Statement; 7 8 9 public class Test1 { 10 11 public static void main(String[] args) { 12 try { 13 Connection connection=DB.getConnection(); 14 Statement st=connection.createStatement(); 15 String sql="select * from player"; 16 ResultSet rs=st.executeQuery(sql); 17 while (rs.next()) { 18 System.out.println(rs.getInt("id")+"\t"+rs.getString("name")+"\t"+rs.getString("club")); 19 } 20 21 rs.close(); 22 st.close(); 23 connection.close(); 24 } catch (SQLException e) { 25 e.printStackTrace(); 26 } 27 } 28 29 }
4、Test2.java(插入)
1 package com.zyz; 2 3 import java.sql.Connection; 4 import java.sql.SQLException; 5 import java.sql.Statement; 6 7 public class Test2 { 8 public static void main(String[] args) { 9 try { 10 Connection connection=DB.getConnection(); 11 Statement st=connection.createStatement(); 12 String sql="insert into player values(601,'林书豪','后卫',195.0,'北京')"; 13 st.executeUpdate(sql); 14 st.close(); 15 connection.close(); 16 System.out.println("over..."); 17 } catch (SQLException e) { 18 e.printStackTrace(); 19 } 20 } 21 }
Sqoop
1、安装
$>tar -zvxf sqoop-1.4.7.bin-hadoop-2.6.0.tar.gz -C ..
2、配置
$>vim /etc/profile
export SQOOP_HOME=/home/hadoop/sqoop-1.4.7.bin-hadoop-2.6.0
export PATH=$PATH:$SQOOP_HOME/bin
$>source /etc/profile
3、使用
$>sqoop help //获得sqoop工具的列表
usage: sqoop COMMAND [ARGS] Available commands: codegen Generate code to interact with database records create-hive-table Import a table definition into Hive eval Evaluate a SQL statement and display the results export Export an HDFS directory to a database table help List available commands import Import a table from a database to HDFS import-all-tables Import tables from a database to HDFS list-databases List available databases on a server list-tables List available tables in a database version Display version information See 'sqoop help COMMAND' for information on a specific command.
$>sqoop help <command> //获得指定工具的帮助
(1)mysql导入到hdfs
sqoop import \ //反斜杠表示换行继续写
--connect jdbc:mysql://10.10.0.1:3306/news \ //mysql数据库的地址
--username root \ //登录mysql的用户名
--password root \ //登录mysql的密码
--table role \ //mysql的表
--query "select * from member where role=2 AND \$CONDITIONS" \ //可以指定复杂的查询,本参数query和table参数2选1,使用query参数时,必须指定target-dir参数
--target-dir /sqoop \ //指定hdfs目录,如果没有该参数,则当前用户的主目录下,即/user/root
--fields-terminated-by '\t' \ //指定字段的分隔符,sqoop默认的是“,”
--num-mappers 1 //mapper的任务数,如果不指定,默认的任务是4,相应的在hdfs上的数据文件就是4
(2)mysql导入hive
sqoop import \ //反斜杠表示换行继续写
--connect jdbc:mysql://10.10.0.1:3306/news \ //mysql数据库的地址
--username root \ //登录mysql的用户名
--password root \ //登录mysql的密码
--table role \ //mysql的表
--hive-table mydb.role \ //hive中的表,mydb是hive中的数据库,需事先创建,role是hive中的表,不需要事先创建,但必须指定--create-hive-table参数
--delete-target-dir \ //如果事先导入过了,有相应的表目录,则删除它。
--create-hive-table \ //如果没有指定的hive表,则自动创建
--hive-import //表示导入到hive
--num-mappers 1 //mapper的任务数,如果不指定,默认的任务是4,相应的在hdfs上的数据文件就是4
说明:
如果出现“ERROR hive.HiveConfig: Could not load org.apache.hadoop.hive.conf.HiveConf. Make sure HIVE_CONF_DIR is set correctly.”
方法1:
$>vim /etc/profile
加入 export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/*
$>source /etc/profile
方法2:
将hive 里面的lib下的hive-exec-**.jar 放到sqoop 的lib //亲测通过
(3)mysql导入hbase
sqoop import \
--connect jdbc:mysql://10.10.0.1:3306/empire3 \
--username root \
--password root \
--table hero \ //mysql中的表,id为主键
--hbase-table zyz:hero \ //hbase中的表
--column-family info \
--hbase-row-key id
(4)hive导出到mysql
sqoop-export
--connect jdbc:mysql://10.10.0.1:3306/study
--username root
--password root
--table player1
--export-dir /hive/warehouse/mydb.db/player
--input-fields-terminated-by '\t' //主要看数据的实际字段分隔符,hive默认的是'\001'。
说明:事先在mysql中建立表以接收hive中的数据。
scala
1、安装
scala是基于java之上,大量地使用java类库和变量,所以先要安装jdk(>1.5)
$>tar -zxvf /home/hadoop/download/scala-2.11.0.tgz ..
2、配置
$>vim /etc/profile
export $SCALA_HOME=/home/hadoop/scala-2.11.0
添加path::$SCALA_HOME/bin
3、启动
$>scala
scala> #进入scala REPL(交互式解释器)
#科普一下,REPL(Read->Eval->Print->Loop,即读取->求值->打印->循环)
scala>:help #帮助
scala>:quit #退出命令行
4、编写Scala程序
(1)编辑
$>vim Hello.scala
[Hello.scala]
object Hello{
def main(args:Array[String]):Unit={
print("hello,world") #语句末尾不要加";"
}
}
(2)编译
格式:scalac <源文件>
$>scalac Hello.scala #Hello.scala是源文件,编译后生成Hello.class
(3)运行
格式:scala <类名>
$>scala Hello #在ubuntu的命令行中会出错,'No such file or class on classpath'
$>scala -classpath . Hello #指定类路径为当前目录
spark
1、安装
tar -zxvf /home/hadoop/download/spark-2.3.0-bin-hadoop2.7.tgz -C ..
2、配置
(1)配置环境变量
vim /etc/profile
export SPARK_HOME=/home/hadoop/spark-2.3.0-bin-hadoop2.7
添加path::$SPARK_HOME/bin
source /etc/profile
(2)配置spark-env.sh
($SPARK_HOME/conf)
将spark-env.sh.template重命名为spark-env.sh
vim spark-env.sh
export JAVA_HOME=/home/hadoop/jdk1.8.0_181
export SCALA_HOME=/home/hadoop/scala-2.11.0
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.7.3/etc/hadoop
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=1024M
(3)修改slaves
vim slaves
master
slave1
slave2
(4)将配置好的spark目录复制到其他节点
scp -r $SPARK_HOME slave1:/home/hadoop/
scp -r $SPARK_HOME slave2:/home/hadoop/
3、启动spark
(1)启动hadoop
$HADOOP_HOME/sbin/start-all.sh
(2)启动spark
$SPARK_HOME/sbin/start-all.sh
(3)web查看
master:8080
4、编写运行spark程序
(1)下载sbt-launch.jar放入安装目录(/home/hadoop/sbt)
(2)创建shell脚本文件用于启动sbt打包程序
文件名:/home/hadoop/sbt/sbt
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar /home/hadoop/sbt/bin/sbt-launch.jar "$@"
chmod -R 777 /home/hadoop/sbt/sbt(使该文件件可执行)
(3)创建spark应用程序
/root/sparkApp/src/main/scala/Hello.scala
1 import org.apache.spark.SparkContext 2 import org.apache.spark.SparkContext._ 3 import org.apache.spark.SparkConf 4 5 object Hello{ 6 def main(args:Array[String]){ 7 val logFile="file:///tmp/txt1" 8 val conf=new SparkConf().setAppName("my spark app") 9 val sc=new SparkContext(conf) 10 val logData=sc.textFile(logFile,2).cache() 11 val numA=logData.filter(line=>line.contains("a")).count() 12 val numB=logData.filter(line=>line.contains("b")).count() 13 println("a:%s,b:%s".format(numA,numB)) 14 } 15 }
//统计txt1中文本中a,b出现的次数
(4)创建应用程序信息文件(~/sparkApp/hello.sbt)
name:="My Spark Project"
version:="1.0"
scalaVersion:="2.11.0"
libraryDependencies+="org.apache.spark" %% "spark-core" % "1.6.0"
用于声明应用程序信息及与spark的依赖关系
(5)在应用程序的根目录下打包spark程序
cd ~/sparkApp
/home/hadoop/sbt/sbt package
(6)使用spark-submit提交到spark上运行
spark-submit --class "Hello" /root/sparkApp/target/scala-2.11/my-spark-project_2.11-1.0.jar
结果:a:2,b:0
客户端编写scala程序提交spark运行
1、编写主程序
WordCount.scala
package com.zyz import org.apache.spark.{SparkConf, SparkContext} /** * spark离线分析 */ object WordCount { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("WordCount").setMaster("spark://master:7077") val context = new SparkContext(conf) context.setLogLevel("WARN") val fileRDD = context.textFile("hdfs://temp/goods.log") val goodsRDD = fileRDD.flatMap(_.split(" ")) val k1v1 = goodsRDD.map((_,1)) val k2v2 = k1v1.reduceByKey(_+_) val k3v3 = k2v2.collect() k3v3.foreach(println) } }
2、打成jar包,上传master节点,并提交spark运行(spark需要先启动)
$>spark-submit --master spark://master:7077 --name WordCount --class com.zyz.WordCount SparkWordCount.jar hdfs://master:8020/temp/goods.log
standalone(独立部署)模式
概念:
standalone:仅启动spark进程,不依赖其他环境
配置:
conf/slaves
master
slave1
slave2
conf/spark-env.sh
export JAVA_HOME=/home/hadoop/jdk1.8.0_181
SPARK_MASTER_HOST=master
SPARK_MASTER_PORT=7077
启动:
sbin/start-all.sh
测试:
spark自带的例子:
$>spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 examples/jars/spark-examples_2.11-2.3.0.jar
# 在spark主目录中运行
yarn(混合)模式
测试:
# 无需启动spark
# 启动hadoop
$>spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster examples/jars/spark-examples_2.11-2.3.0.jar
Flume
1、安装
略
注意:flume的版本应与jdk的版本匹配。
2、配置
(1)配置环境变量
/etc/profile
export FLUME_HOME=/home/hadoop/apache-flume-1.8.0-bin
export PATH=$PATH:$FLUME_HOME/bin
(2)配置jdk路径
$FLUME-HOME/conf/flume-env.sh
export JAVA_HOME=/home/hadoop/jdk1.8.0_181 #加jdk路径
说明:3台节点都要安装、配置
3、应用案例
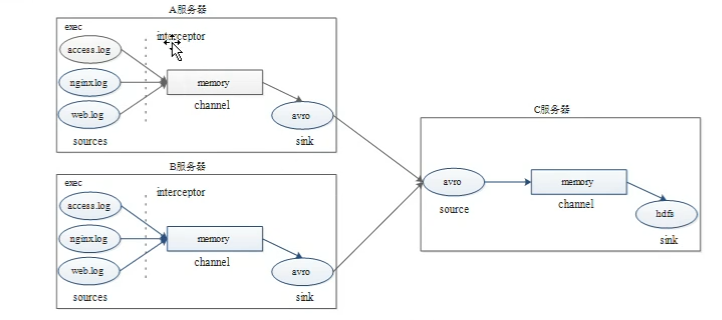
A服务器:slave1,B服务器:slave2,C服务器:master
分别从A服务器、B服务器采集3种类型的日志文件到C服务器的hdfs上。
(1)配置文件
C服务器配置:
$FLUME-HOME/conf/avro-hdfs_logCollection.conf
1 # 配置agent组件 2 a1.sources=r1 3 a1.sinks=k1 4 a1.channels=c1 5 6 # 配置sources组件 7 a1.sources.r1.type=avro 8 a1.sources.r1.bind=master 9 a1.sources.r1.port=41414 10 11 # 配置拦截器 12 a1.sources.r1.interceptors=i1 13 a1.sources.r1.interceptors.i1.type=timestamp 14 15 # 配置channel 16 a1.channels.c1.type=memory 17 a1.channels.c1.capacity=20000 18 a1.channels.c1.transactionCapacity=10000 19 20 # 配置sink 21 a1.sinks.k1.type=hdfs 22 a1.sinks.k1.hdfs.path=hdfs://master:9000/sources/logs/%{type}/%Y%m%d 23 a1.sinks.k1.hdfs.filePrefix=events 24 a1.sinks.k1.hdfs.fileType=DataStream 25 a1.sinks.k1.hdfs.writeFormat=Text 26 # 生成的文件不按条数生成 27 a1.sinks.k1.hdfs.rollCount=0 28 # 生成的文件不按时间生成 29 a1.sinks.k1.hdfs.rollInterval=0 30 # 生成的文件按大小生成 31 a1.sinks.k1.hdfs.rollSize=10485760 32 # 批量写入hdfs的个数 33 a1.sinks.k1.hdfs.batchSize=20 34 # flume操作hdfs的线程数 35 a1.sinks.k1.hdfs.threadsPoolSize=10 36 # 操作hdfs的超时时间 37 a1.sinks.k1.hdfs.callTimeout=3000 38 39 # 将source、sink与channel进行关联绑定 40 a1.sources.r1.channels=c1 41 a1.sinks.k1.channel=c1 42 43
A服务器和B服务器配置:
$FLUME-HOME/conf/exec-avro_logCollection.conf
1 # 配置agenet组件 2 # 用3个source采集不同的日志类型数据 3 a1.sources=r1 r2 r3 4 a1.sinks=k1 5 a1.channels=c1 6 7 # 配置第1个source 8 a1.sources.r1.type=exec 9 a1.sources.r1.command=tail -F /root/logs/access.log 10 a1.sources.r1.interceptors=i1 11 a1.sources.r1.interceptors.i1.type=static 12 a1.sources.r1.interceptors.i1.key=type 13 a1.sources.r1.interceptors.i1.value=access 14 15 # 配置第2个source 16 a1.sources.r2.type=exec 17 a1.sources.r2.command=tail -F /root/logs/nginx.log 18 a1.sources.r2.interceptors=i2 19 a1.sources.r2.interceptors.i2.type=static 20 a1.sources.r2.interceptors.i2.key=type 21 a1.sources.r2.interceptors.i2.value=nginx 22 23 # 配置第3个source 24 a1.sources.r3.type=exec 25 a1.sources.r3.command=tail -F /root/logs/web.log 26 a1.sources.r3.interceptors=i3 27 a1.sources.r3.interceptors.i3.type=static 28 a1.sources.r3.interceptors.i3.key=type 29 a1.sources.r3.interceptors.i3.value=web 30 31 # 配置channel 32 a1.channels.c1.type=memory 33 a1.channels.c1.capacity=2000000 34 a1.channels.c1.transactionCapacity=100000 35 36 # 配置sink 37 a1.sinks.k1.type=avro 38 a1.sinks.k1.hostname=master 39 a1.sinks.k1.port=41414 40 41 # source、sink分别和channel进行绑定 42 a1.sources.r1.channels=c1 43 a1.sources.r2.channels=c1 44 a1.sources.r3.channels=c1 45 a1.sinks.k1.channel=c1
(2)启动flume
在C服务器启动flume
flume-ng agent -c conf/ -f conf/avro-hdfs_logCollection.conf --name a1 -Dflume.root.logger=INFO,console #在flume的主目录下执行
在A服务器和B服务器分别启动flume
flume-ng agent -c conf/ -f conf/exec-avro_logCollection.conf --name a1 -Dflume.root.logger=INFO,console #在flume的主目录下执行
(3)模拟测试
在A服务器、B服务器分别开3个终端,每个终端分别运行脚本,生成日志文件
$>while true;do echo "access,michael" >> /root/logs/access.log;sleep 1;done
$>while true;do echo "nginx,michael" >> /root/logs/nginx.log;sleep 1;done
$>while true;do echo "web,michael" >> /root/logs/web.log;sleep 1;done
(4)结果
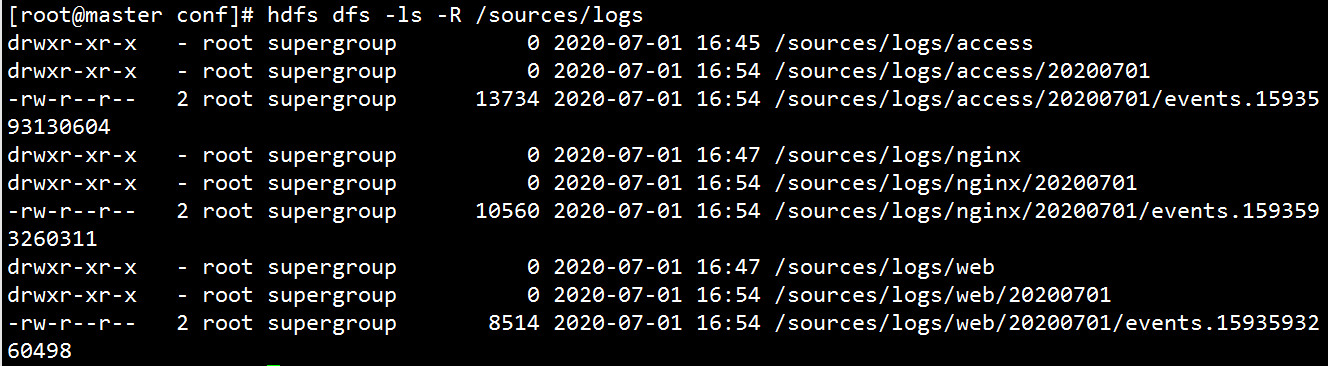
Kafka
一、安装
二、配置
1.环境变量
[/etc/profile]
KAFKA_HOME
PATH
2.配置文件
[$KAFKA_HOME/config/server.properties]
master节点:
broker.id=1 #与zookeeper的 data目录下的myid一致
listeners=PLAINTEXT:// master:9092 #监听本地的IP和端口号
zookeeper.connect=master:2181,slave1:2181,slave2:2181 #zk的集群地址
说明:安装配置好后,将kafka主目录和/etc/profile文件复制到slave1、slave2对应的位置,其中配置文件的broker.id和listener属性要作相应修改。
三、启动
1、启动zk集群
zkServer.sh start
zkServer.sh status #查看启动状态
2、启动kafka集群
/bin/kafka-server-start.sh -daemon config/server.properties #位于kafka主目录执行
四、创建一个topic
1、在某一台服务器上创建topic
$>kafka-topics.sh --create --zookeeper master:2181 --replication-factor 1 --partitions 1 --topic test # 创建topic时候 会向zk进行连接 1表示在单机上存储创建
2、往指定的broker发送消息
$>kafka-console-producer.sh --broker-list slave1:9092 --topic test
3、启动consumer进行消费
$>kafka-console-consumer.sh --bootstrap-server slave1:9092 --topic test --from-beginning
创建topic,存放在3个broker
$>kafka-topics.sh --create --zookeeper master:2181 --replication-factor 1 --partitions 3 --topic my_test_topic
查看日志目录/tmp/kafka_logs是否有主题数据my_test_topic#

 浙公网安备 33010602011771号
浙公网安备 33010602011771号