
mysql回表优化的两种场景
理解回表优化前,先简单了解mysql的两种索引
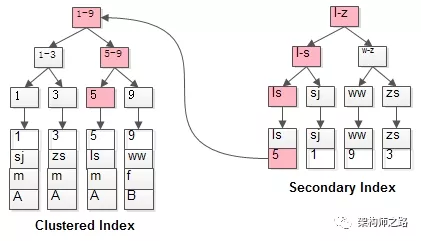
1.聚集索引 :mysql除了存储表的每一条数据,还要至少为一个表维护一个聚集索引,这个聚集索引通常就是表的主键。如下图,mysql的数据以聚集索引的顺序存储在磁盘中。

2.普通索引 : 每一个表中只可以有一个聚集索引,但是可以有多个普通索引。聚集索引的叶子节点存储的是单条记录的所有数据,普通索引的叶子节点存储索引列的数据和主键索引的值。

3.通过普通索引查询整条数据的流程:先通过普通索引树查询到叶子节点存储的主键,再通过主键索引查询到具体的记录。
4.1回表查询的两种优化:覆盖索引
普通索引的叶子节点是包含索引列数据的,当我们需要查询的数据都在索引列中,此时mysql根据普通索引就可以查询到我们需要的数据,此时就不需要再去走聚合索引查询行记录。
create index tb_username_name_qq on tb_user(username,name,qq); #创建索引
extra : using index condition 表示 查找使用了索引,但是需要回表查询数据

using index ; using where:查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据

4.2 子查询优化回表
如果我们需要的数据包含大量字段,此时就不适合使用覆盖索引,此时我们可以对查询语句做一定改变,调整mysql对语句的执行策略。
//每查询到一个主键,做一次回表查询
explain select * from tb_user where username like '"username999999%';

// 可以看到子查询里面的语句extra中是使用到了覆盖索引, null的话也是用到了索引,具体什么情况还没找到资料,有知道的可以评论区聊一聊
explain select * from tb_user where id in (select id from tb_user where username like '"username999999%' );


 浙公网安备 33010602011771号
浙公网安备 33010602011771号