一个合格的vue工程师必会的20道面试题
params和query的区别
用法:query要用path来引入,params要用name来引入,接收参数都是类似的,分别是 this.$route.query.name 和 this.$route.params.name 。
url地址显示:query更加类似于ajax中get传参,params则类似于post,说的再简单一点,前者在浏览器地址栏中显示参数,后者则不显示
注意:query刷新不会丢失query里面的数据 params刷新会丢失 params里面的数据。
为什么Vue采用异步渲染呢?
Vue 是组件级更新,如果不采用异步更新,那么每次更新数据都会对当前组件进行重新渲染,所以为了性能, Vue 会在本轮数据更新后,在异步更新视图。核心思想 nextTick 。
dep.notify() 通知 watcher进行更新, subs[i].update 依次调用 watcher 的 update , queueWatcher 将watcher 去重放入队列, nextTick( flushSchedulerQueue )在下一tick中刷新watcher队列(异步)。
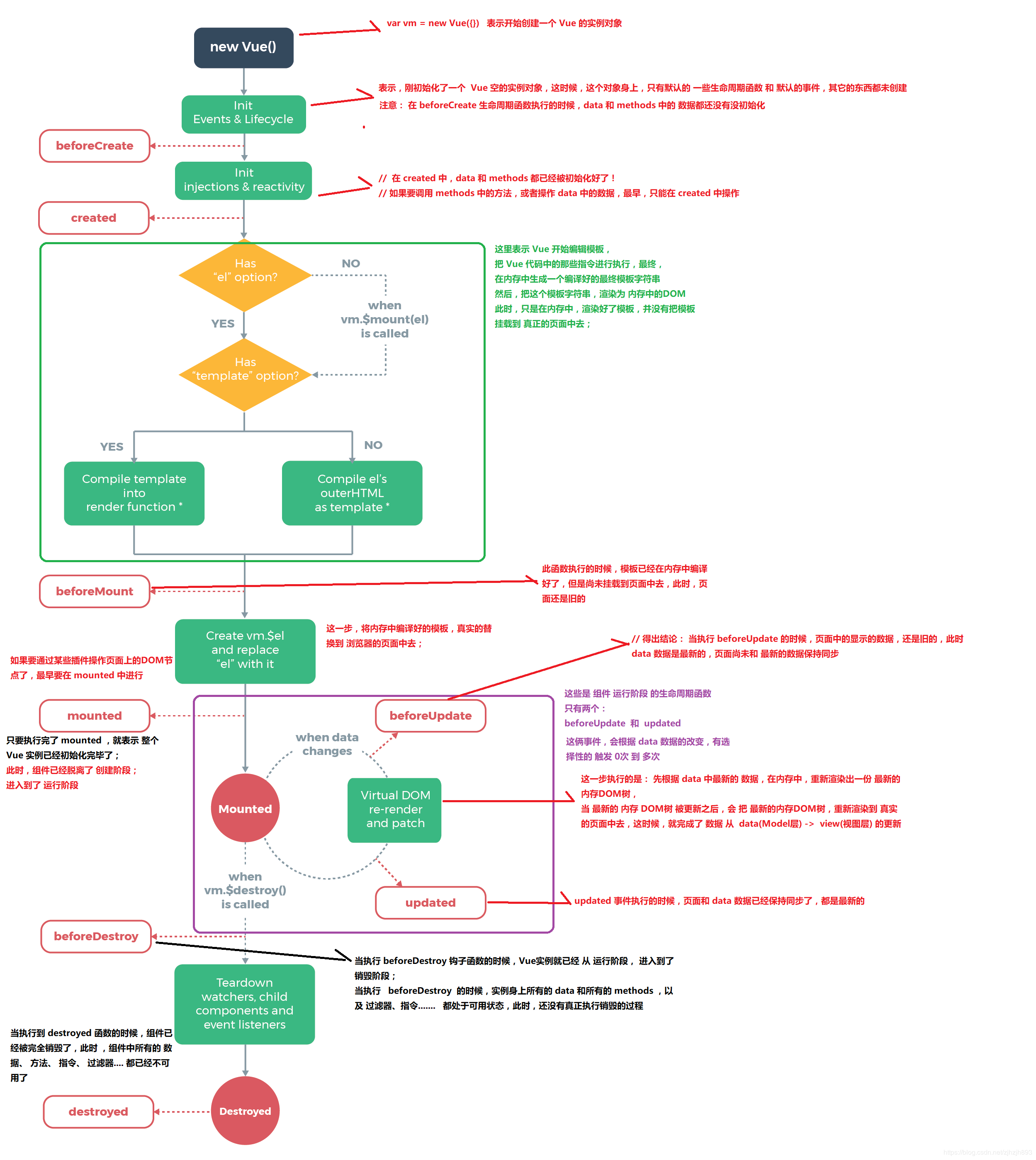
Vue的生命周期方法有哪些
Vue实例有一个完整的生命周期,也就是从开始创建、初始化数据、编译模版、挂载Dom -> 渲染、更新 -> 渲染、卸载等一系列过程,我们称这是Vue的生命周期Vue生命周期总共分为8个阶段创建前/后,载入前/后,更新前/后,销毁前/后
beforeCreate=>created=>beforeMount=>Mounted=>beforeUpdate=>updated=>beforeDestroy=>destroyed。keep-alive下:activateddeactivated
| 生命周期vue2 | 生命周期vue3 | 描述 |
|---|---|---|
beforeCreate |
beforeCreate |
在实例初始化之后,数据观测(data observer) 之前被调用。 |
created |
created |
实例已经创建完成之后被调用。在这一步,实例已完成以下的配置:数据观测(data observer),属性和方法的运算, watch/event 事件回调。这里没有$el |
beforeMount |
beforeMount |
在挂载开始之前被调用:相关的 render 函数首次被调用 |
mounted |
mounted |
el 被新创建的 vm.$el 替换,并挂载到实例上去之后调用该钩子 |
beforeUpdate |
beforeUpdate |
组件数据更新之前调用,发生在虚拟 DOM 打补丁之前 |
updated |
updated |
由于数据更改导致的虚拟 DOM 重新渲染和打补丁,在这之后会调用该钩子 |
beforeDestroy |
beforeUnmount |
实例销毁之前调用。在这一步,实例仍然完全可用 |
destroyed |
unmounted |
实例销毁后调用。调用后, Vue 实例指示的所有东西都会解绑定,所有的事件监听器会被移除,所有的子实例也会被销毁。 该钩子在服务器端渲染期间不被调用。 |
其他几个生命周期
| 生命周期vue2 | 生命周期vue3 | 描述 |
|---|---|---|
activated |
activated |
keep-alive专属,组件被激活时调用 |
deactivated |
deactivated |
keep-alive专属,组件被销毁时调用 |
errorCaptured |
errorCaptured |
捕获一个来自子孙组件的错误时被调用 |
| - | renderTracked |
调试钩子,响应式依赖被收集时调用 |
| - | renderTriggered |
调试钩子,响应式依赖被触发时调用 |
| - | serverPrefetch |
ssr only,组件实例在服务器上被渲染前调用 |
- 要掌握每个生命周期内部可以做什么事
beforeCreate初始化vue实例,进行数据观测。执行时组件实例还未创建,通常用于插件开发中执行一些初始化任务created组件初始化完毕,可以访问各种数据,获取接口数据等beforeMount此阶段vm.el虽已完成DOM初始化,但并未挂载在el选项上mounted实例已经挂载完成,可以进行一些DOM操作beforeUpdate更新前,可用于获取更新前各种状态。此时view层还未更新,可用于获取更新前各种状态。可以在这个钩子中进一步地更改状态,这不会触发附加的重渲染过程。updated完成view层的更新,更新后,所有状态已是最新。可以执行依赖于DOM的操作。然而在大多数情况下,你应该避免在此期间更改状态,因为这可能会导致更新无限循环。 该钩子在服务器端渲染期间不被调用。destroyed可以执行一些优化操作,清空定时器,解除绑定事件- vue3
beforeunmount:实例被销毁前调用,可用于一些定时器或订阅的取消 - vue3
unmounted:销毁一个实例。可清理它与其它实例的连接,解绑它的全部指令及事件监听器
<div id="app">{{name}}</div>
<script>
const vm = new Vue({
data(){
return {name:'poetries'}
},
el: '#app',
beforeCreate(){
// 数据观测(data observer) 和 event/watcher 事件配置之前被调用。
console.log('beforeCreate');
},
created(){
// 属性和方法的运算, watch/event 事件回调。这里没有$el
console.log('created')
},
beforeMount(){
// 相关的 render 函数首次被调用。
console.log('beforeMount')
},
mounted(){
// 被新创建的 vm.$el 替换
console.log('mounted')
},
beforeUpdate(){
// 数据更新时调用,发生在虚拟 DOM 重新渲染和打补丁之前。
console.log('beforeUpdate')
},
updated(){
// 由于数据更改导致的虚拟 DOM 重新渲染和打补丁,在这之后会调用该钩子。
console.log('updated')
},
beforeDestroy(){
// 实例销毁之前调用 实例仍然完全可用
console.log('beforeDestroy')
},
destroyed(){
// 所有东西都会解绑定,所有的事件监听器会被移除
console.log('destroyed')
}
});
setTimeout(() => {
vm.name = 'poetry';
setTimeout(() => {
vm.$destroy()
}, 1000);
}, 1000);
</script>
- 组合式API生命周期钩子
你可以通过在生命周期钩子前面加上 “on” 来访问组件的生命周期钩子。
下表包含如何在 setup() 内部调用生命周期钩子:
| 选项式 API | Hook inside setup |
|---|---|
beforeCreate |
不需要* |
created |
不需要* |
beforeMount |
onBeforeMount |
mounted |
onMounted |
beforeUpdate |
onBeforeUpdate |
updated |
onUpdated |
beforeUnmount |
onBeforeUnmount |
unmounted |
onUnmounted |
errorCaptured |
onErrorCaptured |
renderTracked |
onRenderTracked |
renderTriggered |
onRenderTriggered |
因为
setup是围绕beforeCreate和created生命周期钩子运行的,所以不需要显式地定义它们。换句话说,在这些钩子中编写的任何代码都应该直接在setup函数中编写
export default {
setup() {
// mounted
onMounted(() => {
console.log('Component is mounted!')
})
}
}
setup和created谁先执行?
beforeCreate:组件被创建出来,组件的methods和data还没初始化好setup:在beforeCreate和created之间执行created:组件被创建出来,组件的methods和data已经初始化好了
由于在执行
setup的时候,created还没有创建好,所以在setup函数内我们是无法使用data和methods的。所以vue为了让我们避免错误的使用,直接将setup函数内的this执行指向undefined
import { ref } from "vue"
export default {
// setup函数是组合api的入口函数,注意在组合api中定义的变量或者方法,要在template响应式需要return{}出去
setup(){
let count = ref(1)
function myFn(){
count.value +=1
}
return {count,myFn}
},
}
- 其他问题
-
什么是vue生命周期? Vue 实例从创建到销毁的过程,就是生命周期。从开始创建、初始化数据、编译模板、挂载Dom→渲染、更新→渲染、销毁等一系列过程,称之为
Vue的生命周期。 -
vue生命周期的作用是什么? 它的生命周期中有多个事件钩子,让我们在控制整个Vue实例的过程时更容易形成好的逻辑。
-
vue生命周期总共有几个阶段? 它可以总共分为
8个阶段:创建前/后、载入前/后、更新前/后、销毁前/销毁后。 -
第一次页面加载会触发哪几个钩子? 会触发下面这几个
beforeCreate、created、beforeMount、mounted。 -
你的接口请求一般放在哪个生命周期中? 接口请求一般放在
mounted中,但需要注意的是服务端渲染时不支持mounted,需要放到created中 -
DOM 渲染在哪个周期中就已经完成? 在
mounted中,- 注意
mounted不会承诺所有的子组件也都一起被挂载。如果你希望等到整个视图都渲染完毕,可以用vm.$nextTick替换掉mounted
mounted: function () { this.$nextTick(function () { // Code that will run only after the // entire view has been rendered }) } - 注意
### Vue 中 computed 和 watch 有什么区别?
**计算属性 computed**:
(1)**支持缓存**,只有依赖数据发生变化时,才会重新进行计算函数;
(2)计算属性内**不支持异步操作**;
(3)计算属性的函数中**都有一个 get**(默认具有,获取计算属性)**和 set**(手动添加,设置计算属性)方法;
(4)计算属性是自动监听依赖值的变化,从而动态返回内容。
**侦听属性 watch**:
(1)**不支持缓存**,只要数据发生变化,就会执行侦听函数;
(2)侦听属性内**支持异步操作**;
(3)侦听属性的值**可以是一个对象,接收 handler 回调,deep,immediate 三个属性**;
(3)监听是一个过程,在监听的值变化时,可以触发一个回调,并**做一些其他事情**。
参考:[前端vue面试题详细解答](https://kc7474.com/archives/1333?url=vue)
### Vue template 到 render 的过程
vue的模版编译过程主要如下:**template -> ast -> render函数**
vue 在模版编译版本的码中会执行 compileToFunctions 将template转化为render函数:
```javascript
// 将模板编译为render函数const { render, staticRenderFns } = compileToFunctions(template,options//省略}, this)
CompileToFunctions中的主要逻辑如下∶ (1)调用parse方法将template转化为ast(抽象语法树)
constast = parse(template.trim(), options)
- parse的目标:把tamplate转换为AST树,它是一种用 JavaScript对象的形式来描述整个模板。
- 解析过程:利用正则表达式顺序解析模板,当解析到开始标签、闭合标签、文本的时候都会分别执行对应的 回调函数,来达到构造AST树的目的。
AST元素节点总共三种类型:type为1表示普通元素、2为表达式、3为纯文本
(2)对静态节点做优化
optimize(ast,options)
这个过程主要分析出哪些是静态节点,给其打一个标记,为后续更新渲染可以直接跳过静态节点做优化
深度遍历AST,查看每个子树的节点元素是否为静态节点或者静态节点根。如果为静态节点,他们生成的DOM永远不会改变,这对运行时模板更新起到了极大的优化作用。
(3)生成代码
const code = generate(ast, options)
generate将ast抽象语法树编译成 render字符串并将静态部分放到 staticRenderFns 中,最后通过 new Function(`` render``) 生成render函数。
action 与 mutation 的区别
mutation是同步更新,$watch严格模式下会报错action是异步操作,可以获取数据后调用mutation提交最终数据
assets和static的区别
相同点: assets 和 static 两个都是存放静态资源文件。项目中所需要的资源文件图片,字体图标,样式文件等都可以放在这两个文件下,这是相同点
不相同点:assets 中存放的静态资源文件在项目打包时,也就是运行 npm run build 时会将 assets 中放置的静态资源文件进行打包上传,所谓打包简单点可以理解为压缩体积,代码格式化。而压缩后的静态资源文件最终也都会放置在 static 文件中跟着 index.html 一同上传至服务器。static 中放置的静态资源文件就不会要走打包压缩格式化等流程,而是直接进入打包好的目录,直接上传至服务器。因为避免了压缩直接进行上传,在打包时会提高一定的效率,但是 static 中的资源文件由于没有进行压缩等操作,所以文件的体积也就相对于 assets 中打包后的文件提交较大点。在服务器中就会占据更大的空间。
建议: 将项目中 template需要的样式文件js文件等都可以放置在 assets 中,走打包这一流程。减少体积。而项目中引入的第三方的资源文件如iconfoont.css 等文件可以放置在 static 中,因为这些引入的第三方文件已经经过处理,不再需要处理,直接上传。
双向数据绑定的原理
Vue.js 是采用数据劫持结合发布者-订阅者模式的方式,通过Object.defineProperty()来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。主要分为以下几个步骤:
- 需要observe的数据对象进行递归遍历,包括子属性对象的属性,都加上setter和getter这样的话,给这个对象的某个值赋值,就会触发setter,那么就能监听到了数据变化
- compile解析模板指令,将模板中的变量替换成数据,然后初始化渲染页面视图,并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者,一旦数据有变动,收到通知,更新视图
- Watcher订阅者是Observer和Compile之间通信的桥梁,主要做的事情是: ①在自身实例化时往属性订阅器(dep)里面添加自己 ②自身必须有一个update()方法 ③待属性变动dep.notice()通知时,能调用自身的update()方法,并触发Compile中绑定的回调,则功成身退。
- MVVM作为数据绑定的入口,整合Observer、Compile和Watcher三者,通过Observer来监听自己的model数据变化,通过Compile来解析编译模板指令,最终利用Watcher搭起Observer和Compile之间的通信桥梁,达到数据变化 -> 视图更新;视图交互变化(input) -> 数据model变更的双向绑定效果。
Computed 和 Methods 的区别
可以将同一函数定义为一个 method 或者一个计算属性。对于最终的结果,两种方式是相同的
不同点:
- computed: 计算属性是基于它们的依赖进行缓存的,只有在它的相关依赖发生改变时才会重新求值;
- method 调用总会执行该函数。
什么是 mixin ?
- Mixin 使我们能够为 Vue 组件编写可插拔和可重用的功能。
- 如果希望在多个组件之间重用一组组件选项,例如生命周期 hook、 方法等,则可以将其编写为 mixin,并在组件中简单的引用它。
- 然后将 mixin 的内容合并到组件中。如果你要在 mixin 中定义生命周期 hook,那么它在执行时将优化于组件自已的 hook。
理解Vue运行机制全局概览
全局概览
首先我们来看一下笔者画的内部流程图。
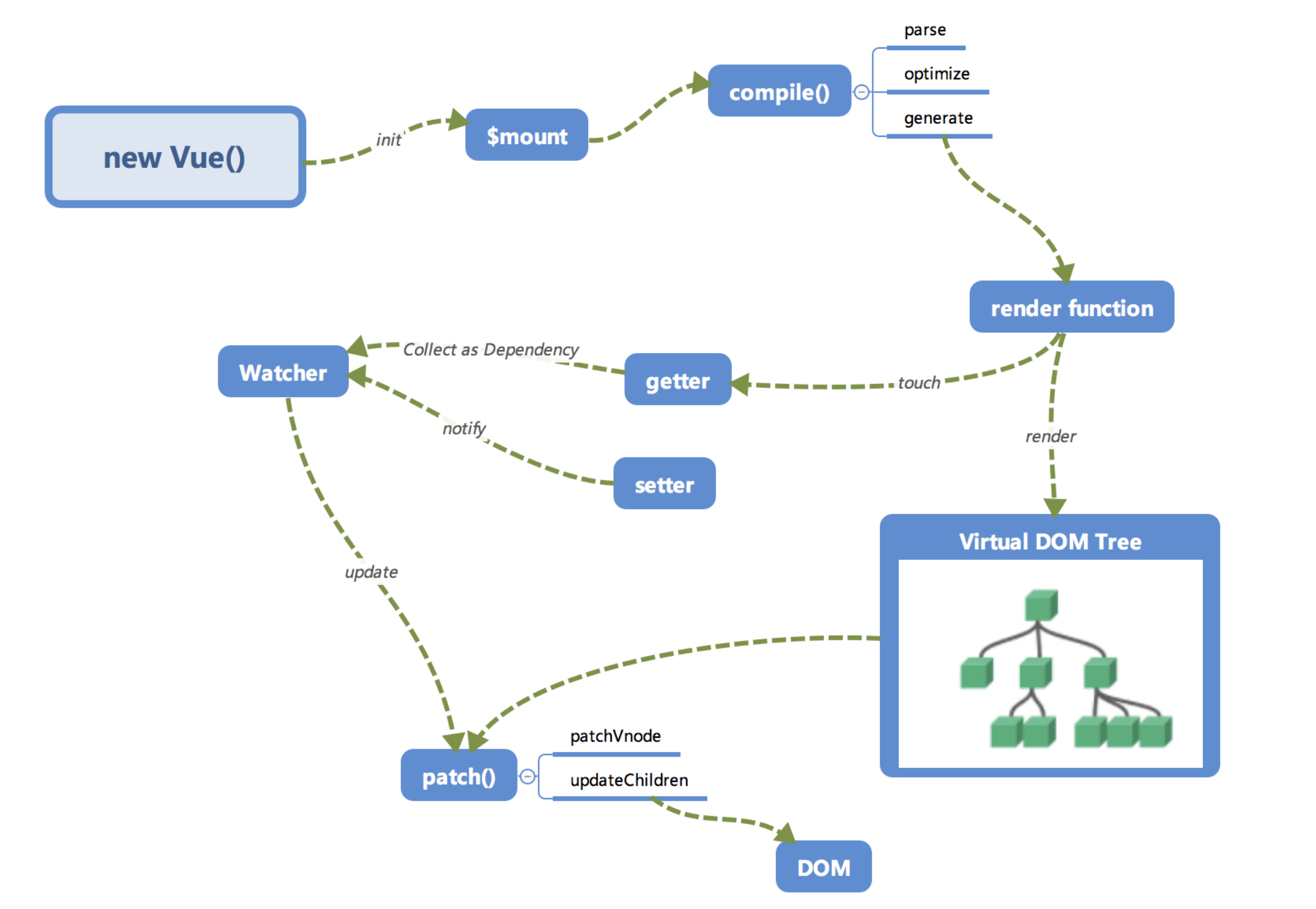
大家第一次看到这个图一定是一头雾水的,没有关系,我们来逐个讲一下这些模块的作用以及调用关系。相信讲完之后大家对Vue.js内部运行机制会有一个大概的认识。
初始化及挂载
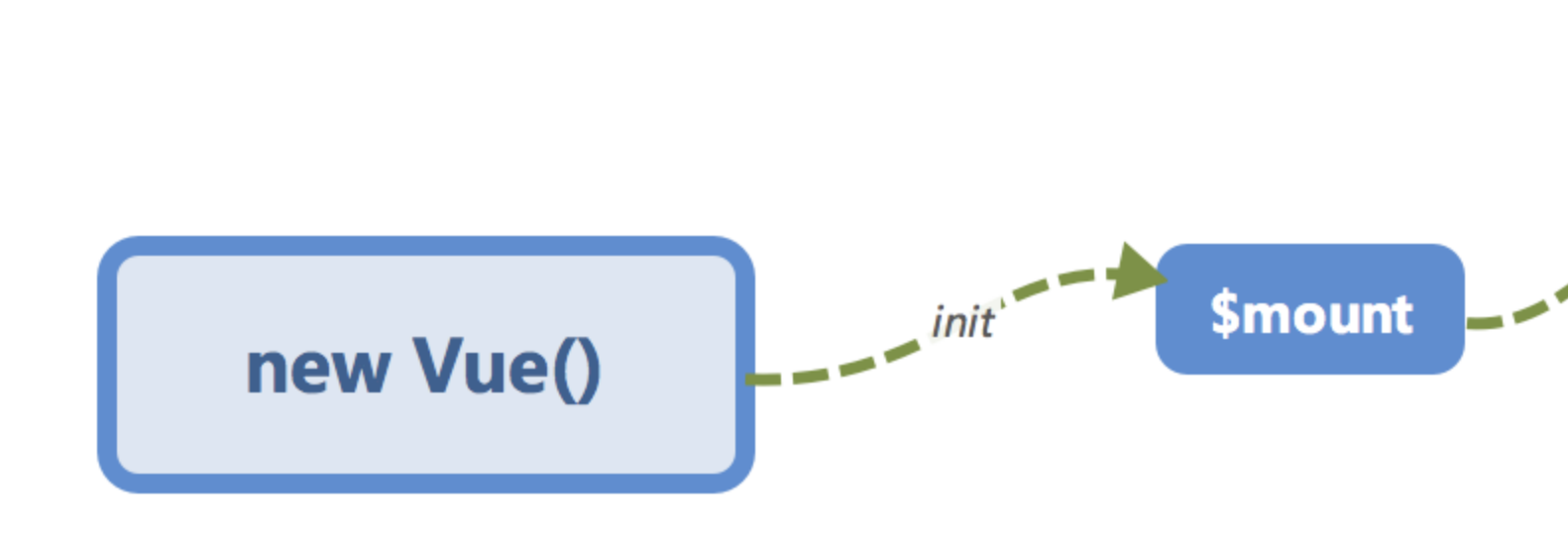
在
new Vue()之后。 Vue 会调用_init函数进行初始化,也就是这里的init过程,它会初始化生命周期、事件、 props、 methods、 data、 computed 与 watch 等。其中最重要的是通过Object.defineProperty设置setter与getter函数,用来实现「 响应式 」以及「 依赖收集 」,后面会详细讲到,这里只要有一个印象即可。
初始化之后调用
$mount会挂载组件,如果是运行时编译,即不存在 render function 但是存在 template 的情况,需要进行「 编译 」步骤。
编译
compile编译可以分成 parse、optimize 与 generate 三个阶段,最终需要得到 render function。
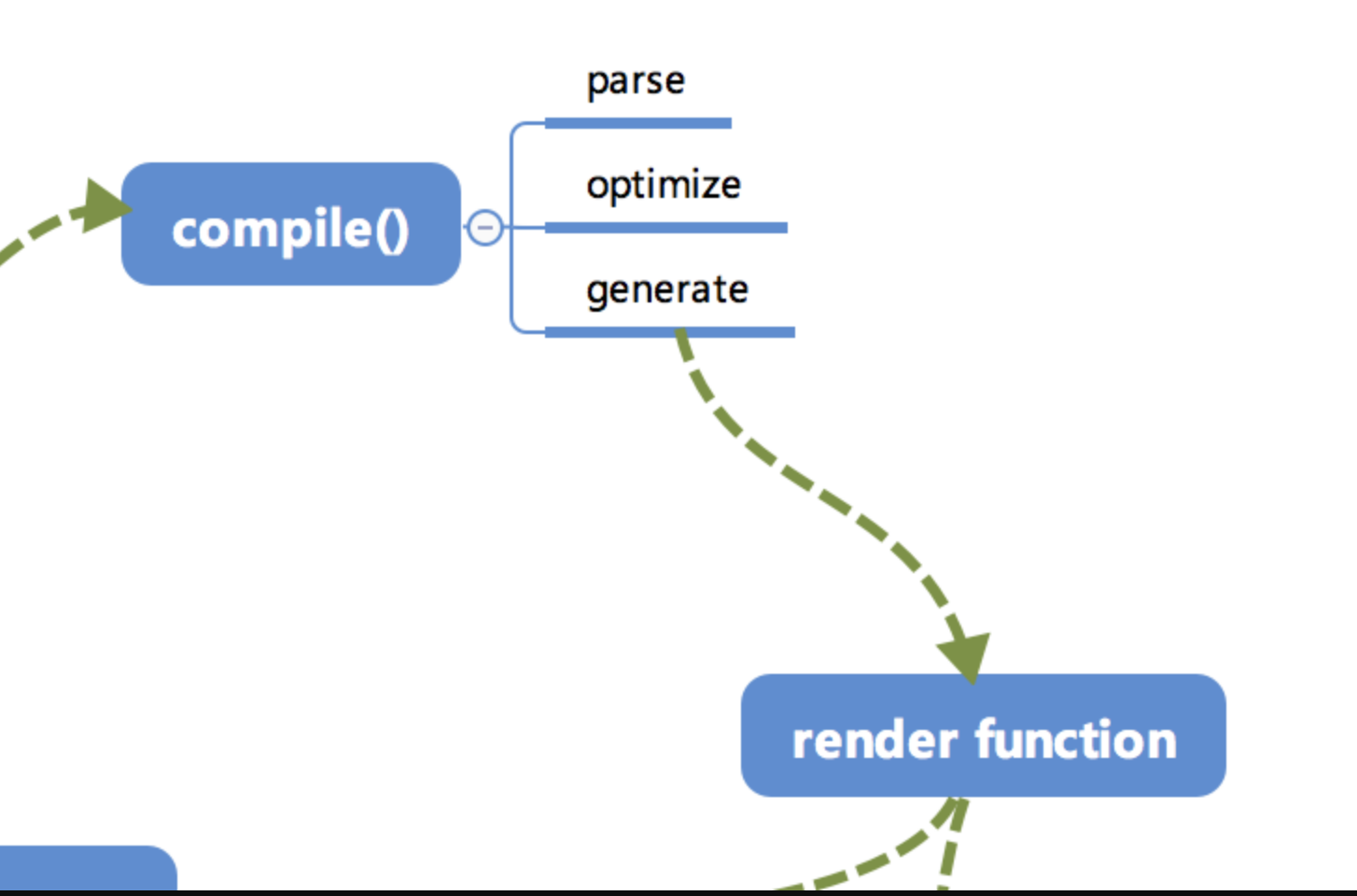
1. parse
parse 会用正则等方式解析 template 模板中的指令、class、style等数据,形成AST。
2. optimize
optimize的主要作用是标记 static 静态节点,这是 Vue 在编译过程中的一处优化,后面当update更新界面时,会有一个patch的过程, diff 算法会直接跳过静态节点,从而减少了比较的过程,优化了patch的性能。
3. generate
generate是将 AST 转化成render function字符串的过程,得到结果是render的字符串以及 staticRenderFns 字符串。
- 在经历过
parse、optimize与generate这三个阶段以后,组件中就会存在渲染VNode所需的render function了。
响应式
接下来也就是 Vue.js 响应式核心部分。
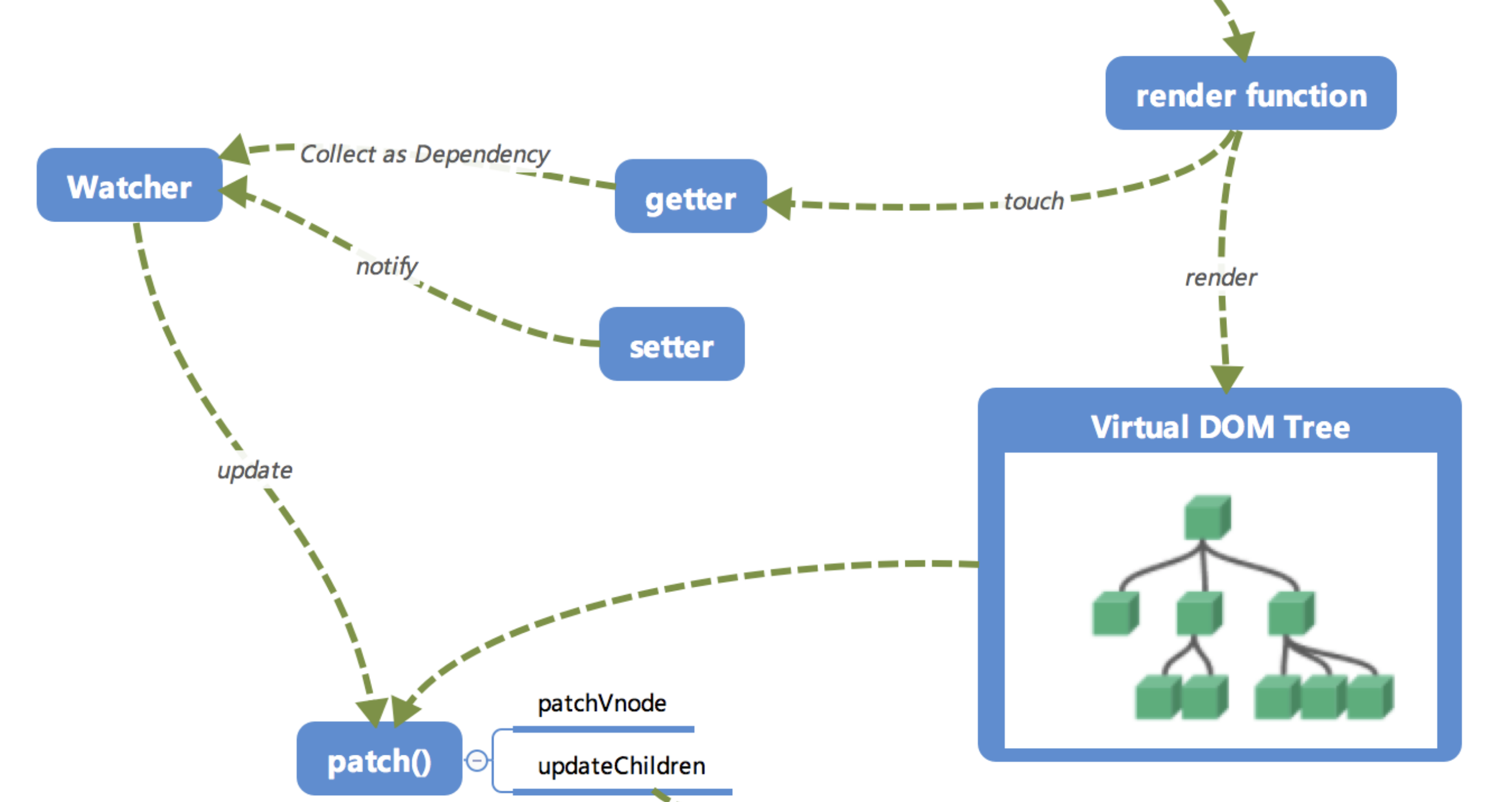
这里的
getter跟setter已经在之前介绍过了,在init的时候通过Object.defineProperty进行了绑定,它使得当被设置的对象被读取的时候会执行getter函数,而在当被赋值的时候会执行setter函数。
- 当
render function被渲染的时候,因为会读取所需对象的值,所以会触发getter函数进行「 依赖收集 」,「 依赖收集 」的目的是将观察者Watcher对象存放到当前闭包中的订阅者Dep的subs中。形成如下所示的这样一个关系。
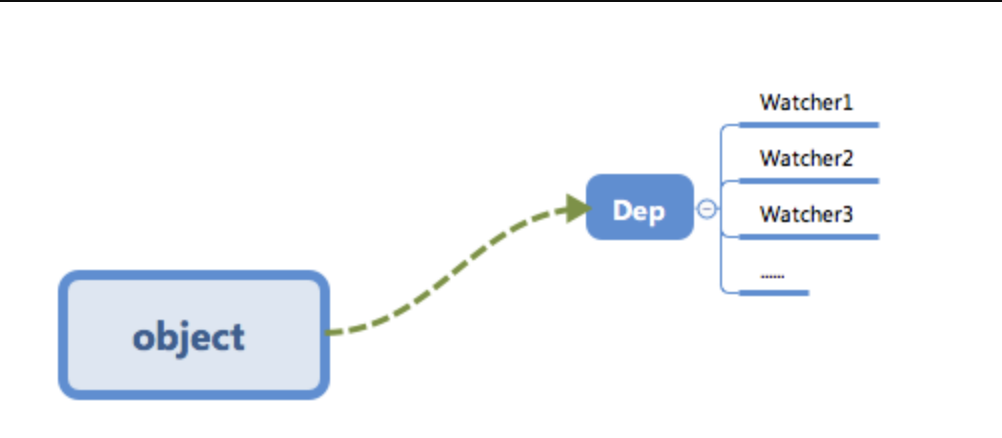
在修改对象的值的时候,会触发对应的
setter,setter通知之前「 依赖收集 」得到的 Dep 中的每一个 Watcher,告诉它们自己的值改变了,需要重新渲染视图。这时候这些 Watcher 就会开始调用update来更新视图,当然这中间还有一个patch的过程以及使用队列来异步更新的策略,这个我们后面再讲。
Virtual DOM
我们知道,
render function会被转化成VNode节点。Virtual DOM其实就是一棵以 JavaScript 对象( VNode 节点)作为基础的树,用对象属性来描述节点,实际上它只是一层对真实 DOM 的抽象。最终可以通过一系列操作使这棵树映射到真实环境上。由于 Virtual DOM 是以 JavaScript 对象为基础而不依赖真实平台环境,所以使它具有了跨平台的能力,比如说浏览器平台、Weex、Node 等。
比如说下面这样一个例子:
{
tag: 'div', /*说明这是一个div标签*/
children: [ /*存放该标签的子节点*/
{
tag: 'a', /*说明这是一个a标签*/
text: 'click me' /*标签的内容*/
}
]
}
渲染后可以得到
<div>
<a>click me</a>
</div>
这只是一个简单的例子,实际上的节点有更多的属性来标志节点,比如 isStatic (代表是否为静态节点)、 isComment (代表是否为注释节点)等。
更新视图
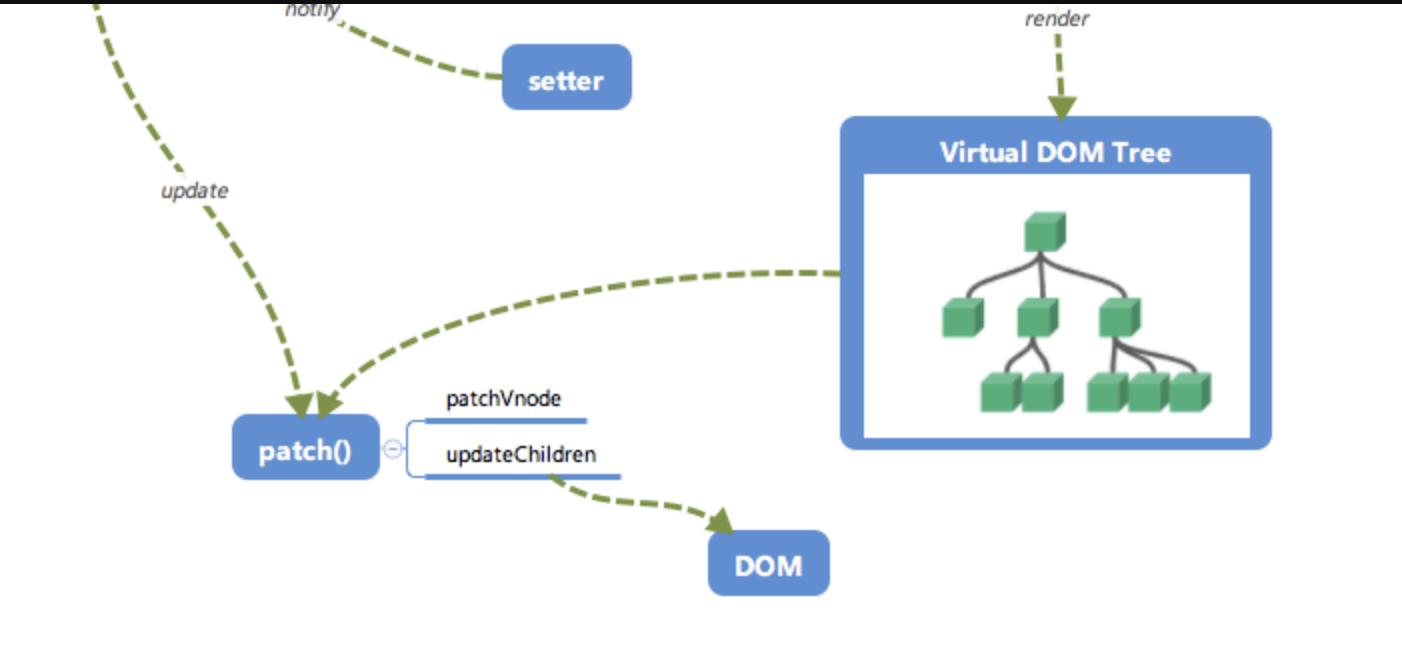
- 前面我们说到,在修改一个对象值的时候,会通过
setter -> Watcher -> update的流程来修改对应的视图,那么最终是如何更新视图的呢? - 当数据变化后,执行 render function 就可以得到一个新的 VNode 节点,我们如果想要得到新的视图,最简单粗暴的方法就是直接解析这个新的
VNode节点,然后用innerHTML直接全部渲染到真实DOM中。但是其实我们只对其中的一小块内容进行了修改,这样做似乎有些「 浪费 」。 - 那么我们为什么不能只修改那些「改变了的地方」呢?这个时候就要介绍我们的「
patch」了。我们会将新的VNode与旧的VNode一起传入patch进行比较,经过 diff 算法得出它们的「 差异 」。最后我们只需要将这些「 差异 」的对应 DOM 进行修改即可。
再看全局
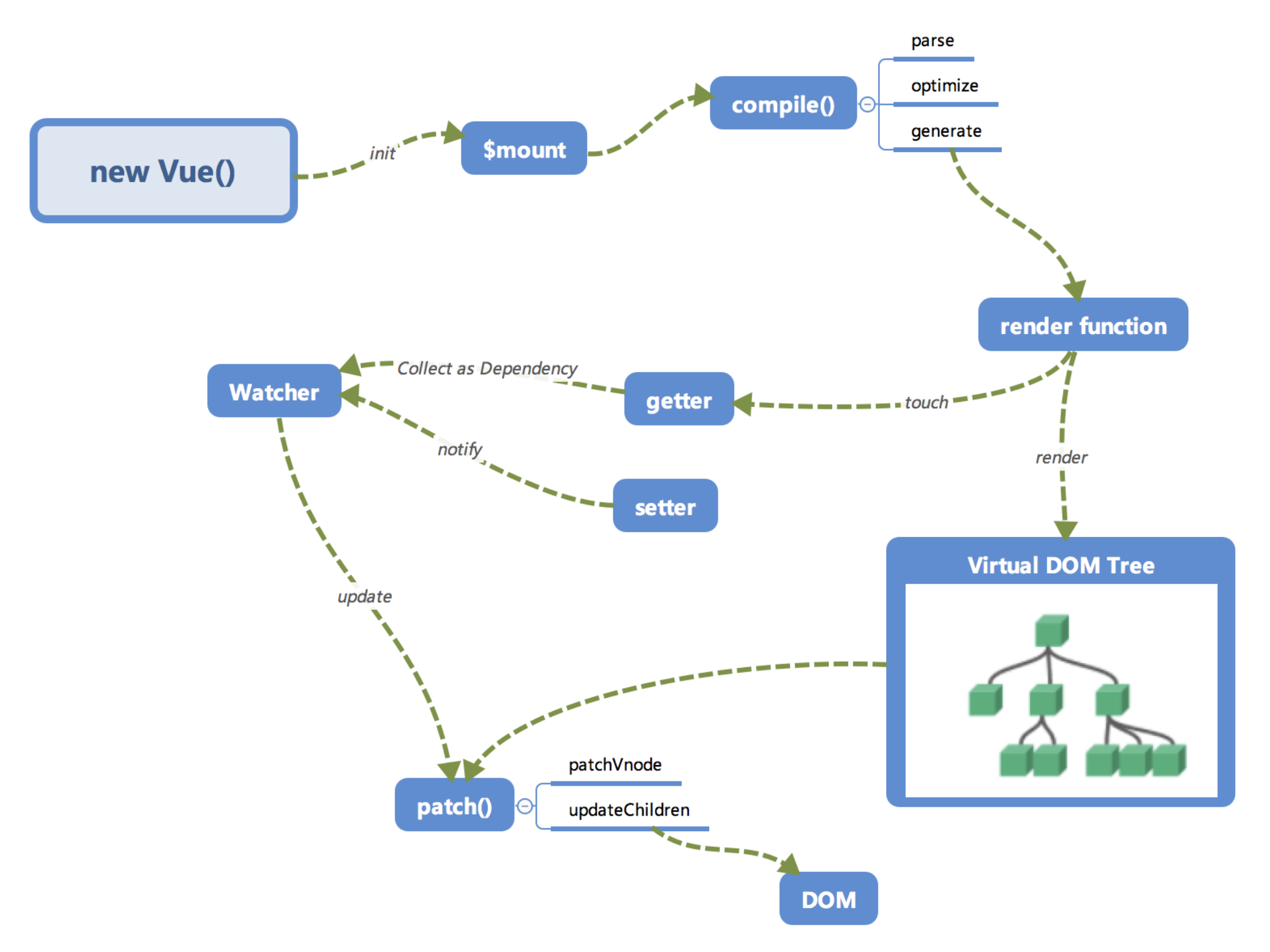
回过头再来看看这张图,是不是大脑中已经有一个大概的脉络了呢?
keep-alive 中的生命周期哪些
keep-alive是 Vue 提供的一个内置组件,用来对组件进行缓存——在组件切换过程中将状态保留在内存中,防止重复渲染DOM。
如果为一个组件包裹了 keep-alive,那么它会多出两个生命周期:deactivated、activated。同时,beforeDestroy 和 destroyed 就不会再被触发了,因为组件不会被真正销毁。
当组件被换掉时,会被缓存到内存中、触发 deactivated 生命周期;当组件被切回来时,再去缓存里找这个组件、触发 activated钩子函数。
v-model 可以被用在自定义组件上吗?如果可以,如何使用?
可以。v-model 实际上是一个语法糖,如:
<input v-model="searchText">
实际上相当于:
<input
v-bind:value="searchText"
v-on:input="searchText = $event.target.value"
>
用在自定义组件上也是同理:
<custom-input v-model="searchText">
相当于:
<custom-input
v-bind:value="searchText"
v-on:input="searchText = $event"
></custom-input>
显然,custom-input 与父组件的交互如下:
- 父组件将
searchText变量传入custom-input 组件,使用的 prop 名为value; - custom-input 组件向父组件传出名为
input的事件,父组件将接收到的值赋值给searchText;
所以,custom-input 组件的实现应该类似于这样:
Vue.component('custom-input', {
props: ['value'],
template: ` <input v-bind:value="value" v-on:input="$emit('input', $event.target.value)" > `
})
子组件可以直接改变父组件的数据吗?
子组件不可以直接改变父组件的数据。这样做主要是为了维护父子组件的单向数据流。每次父级组件发生更新时,子组件中所有的 prop 都将会刷新为最新的值。如果这样做了,Vue 会在浏览器的控制台中发出警告。
Vue提倡单向数据流,即父级 props 的更新会流向子组件,但是反过来则不行。这是为了防止意外的改变父组件状态,使得应用的数据流变得难以理解,导致数据流混乱。如果破坏了单向数据流,当应用复杂时,debug 的成本会非常高。
只能通过 $emit 派发一个自定义事件,父组件接收到后,由父组件修改。
使用 Object.defineProperty() 来进行数据劫持有什么缺点?
在对一些属性进行操作时,使用这种方法无法拦截,比如通过下标方式修改数组数据或者给对象新增属性,这都不能触发组件的重新渲染,因为 Object.defineProperty 不能拦截到这些操作。更精确的来说,对于数组而言,大部分操作都是拦截不到的,只是 Vue 内部通过重写函数的方式解决了这个问题。
在 Vue3.0 中已经不使用这种方式了,而是通过使用 Proxy 对对象进行代理,从而实现数据劫持。使用Proxy 的好处是它可以完美的监听到任何方式的数据改变,唯一的缺点是兼容性的问题,因为 Proxy 是 ES6 的语法。
Vue2.x 响应式数据原理
整体思路是数据劫持+观察者模式
对象内部通过 defineReactive 方法,使用 Object.defineProperty 来劫持各个属性的 setter、getter(只会劫持已经存在的属性),数组则是通过重写数组7个方法来实现。当页面使用对应属性时,每个属性都拥有自己的 dep 属性,存放他所依赖的 watcher(依赖收集),当属性变化后会通知自己对应的 watcher 去更新(派发更新)
Object.defineProperty基本使用
function observer(value) { // proxy reflect
if (typeof value === 'object' && typeof value !== null)
for (let key in value) {
defineReactive(value, key, value[key]);
}
}
function defineReactive(obj, key, value) {
observer(value);
Object.defineProperty(obj, key, {
get() { // 收集对应的key 在哪个方法(组件)中被使用
return value;
},
set(newValue) {
if (newValue !== value) {
observer(newValue);
value = newValue; // 让key对应的方法(组件重新渲染)重新执行
}
}
})
}
let obj1 = { school: { name: 'poetry', age: 20 } };
observer(obj1);
console.log(obj1)
源码分析
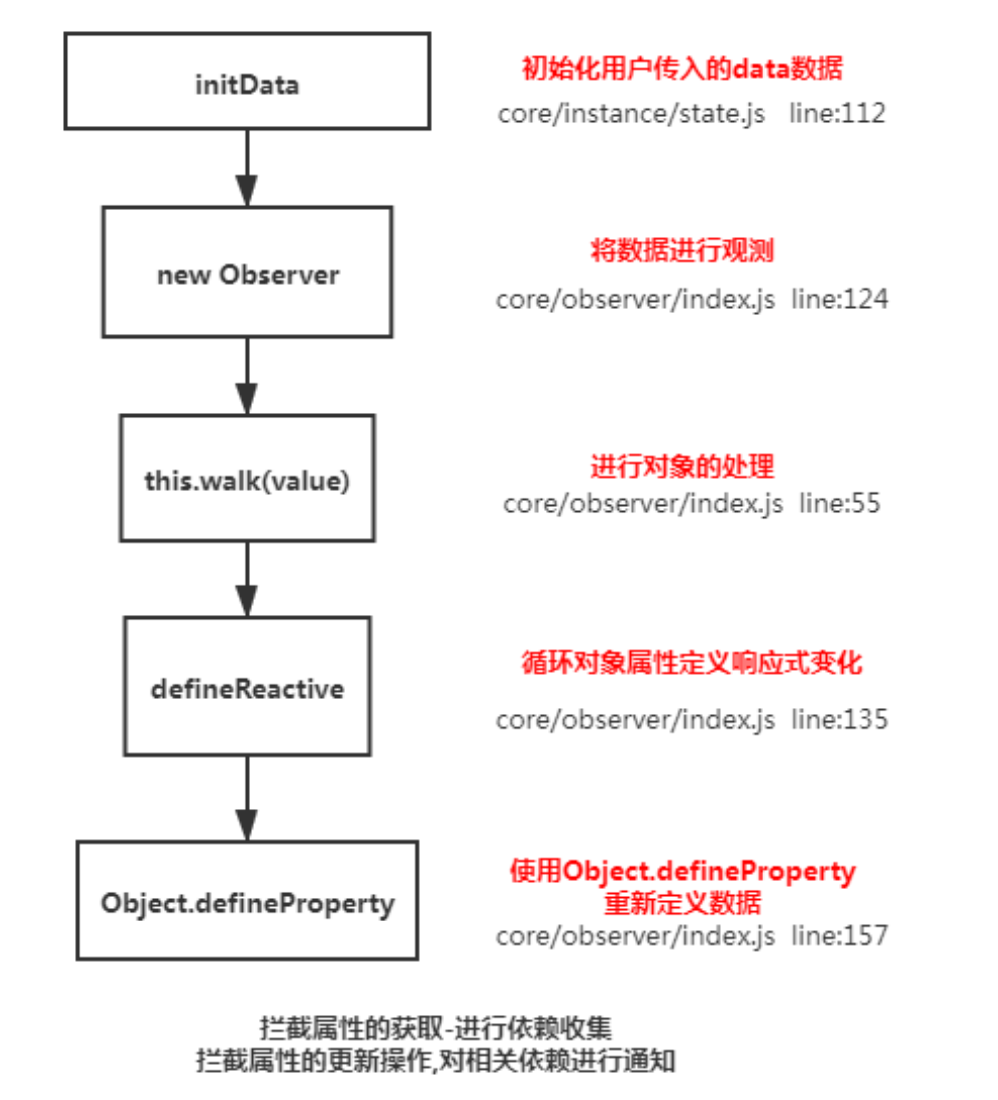
class Observer {
// 观测值
constructor(value) {
this.walk(value);
}
walk(data) {
// 对象上的所有属性依次进行观测
let keys = Object.keys(data);
for (let i = 0; i < keys.length; i++) {
let key = keys[i];
let value = data[key];
defineReactive(data, key, value);
}
}
}
// Object.defineProperty数据劫持核心 兼容性在ie9以及以上
function defineReactive(data, key, value) {
observe(value); // 递归关键
// --如果value还是一个对象会继续走一遍odefineReactive 层层遍历一直到value不是对象才停止
// 思考?如果Vue数据嵌套层级过深 >>性能会受影响
Object.defineProperty(data, key, {
get() {
console.log("获取值");
//需要做依赖收集过程 这里代码没写出来
return value;
},
set(newValue) {
if (newValue === value) return;
console.log("设置值");
//需要做派发更新过程 这里代码没写出来
value = newValue;
},
});
}
export function observe(value) {
// 如果传过来的是对象或者数组 进行属性劫持
if (
Object.prototype.toString.call(value) === "[object Object]" ||
Array.isArray(value)
) {
return new Observer(value);
}
}
说一说你对vue响应式理解回答范例
- 所谓数据响应式就是能够使数据变化可以被检测并对这种变化做出响应的机制
MVVM框架中要解决的一个核心问题是连接数据层和视图层,通过数据驱动应用,数据变化,视图更新,要做到这点的就需要对数据做响应式处理,这样一旦数据发生变化就可以立即做出更新处理- 以
vue为例说明,通过数据响应式加上虚拟DOM和patch算法,开发人员只需要操作数据,关心业务,完全不用接触繁琐的DOM操作,从而大大提升开发效率,降低开发难度 vue2中的数据响应式会根据数据类型来做不同处理,如果是 对象则采用Object.defineProperty()的方式定义数据拦截,当数据被访问或发生变化时,我们感知并作出响应;如果是数组则通过覆盖数组对象原型的7个变更方法 ,使这些方法可以额外的做更新通知,从而作出响应。这种机制很好的解决了数据响应化的问题,但在实际使用中也存在一些缺点:比如初始化时的递归遍历会造成性能损失;新增或删除属性时需要用户使用Vue.set/delete这样特殊的api才能生效;对于es6中新产生的Map、Set这些数据结构不支持等问题- 为了解决这些问题,
vue3重新编写了这一部分的实现:利用ES6的Proxy代理要响应化的数据,它有很多好处,编程体验是一致的,不需要使用特殊api,初始化性能和内存消耗都得到了大幅改善;另外由于响应化的实现代码抽取为独立的reactivity包,使得我们可以更灵活的使用它,第三方的扩展开发起来更加灵活了
Vue 的父子组件生命周期钩子函数执行顺序
- 渲染顺序 :先父后子,完成顺序:先子后父
- 更新顺序 :父更新导致子更新,子更新完成后父
- 销毁顺序 :先父后子,完成顺序:先子后父
加载渲染过程
父 beforeCreate->父 created->父 beforeMount->子 beforeCreate->子 created->子 beforeMount->子 mounted->父 mounted。子组件先挂载,然后到父组件
子组件更新过程
父 beforeUpdate->子 beforeUpdate->子 updated->父 updated
父组件更新过程
父 beforeUpdate->父 updated
销毁过程
父 beforeDestroy->子 beforeDestroy->子 destroyed->父 destroyed
之所以会这样是因为
Vue创建过程是一个递归过程,先创建父组件,有子组件就会创建子组件,因此创建时先有父组件再有子组件;子组件首次创建时会添加mounted钩子到队列,等到patch结束再执行它们,可见子组件的mounted钩子是先进入到队列中的,因此等到patch结束执行这些钩子时也先执行。
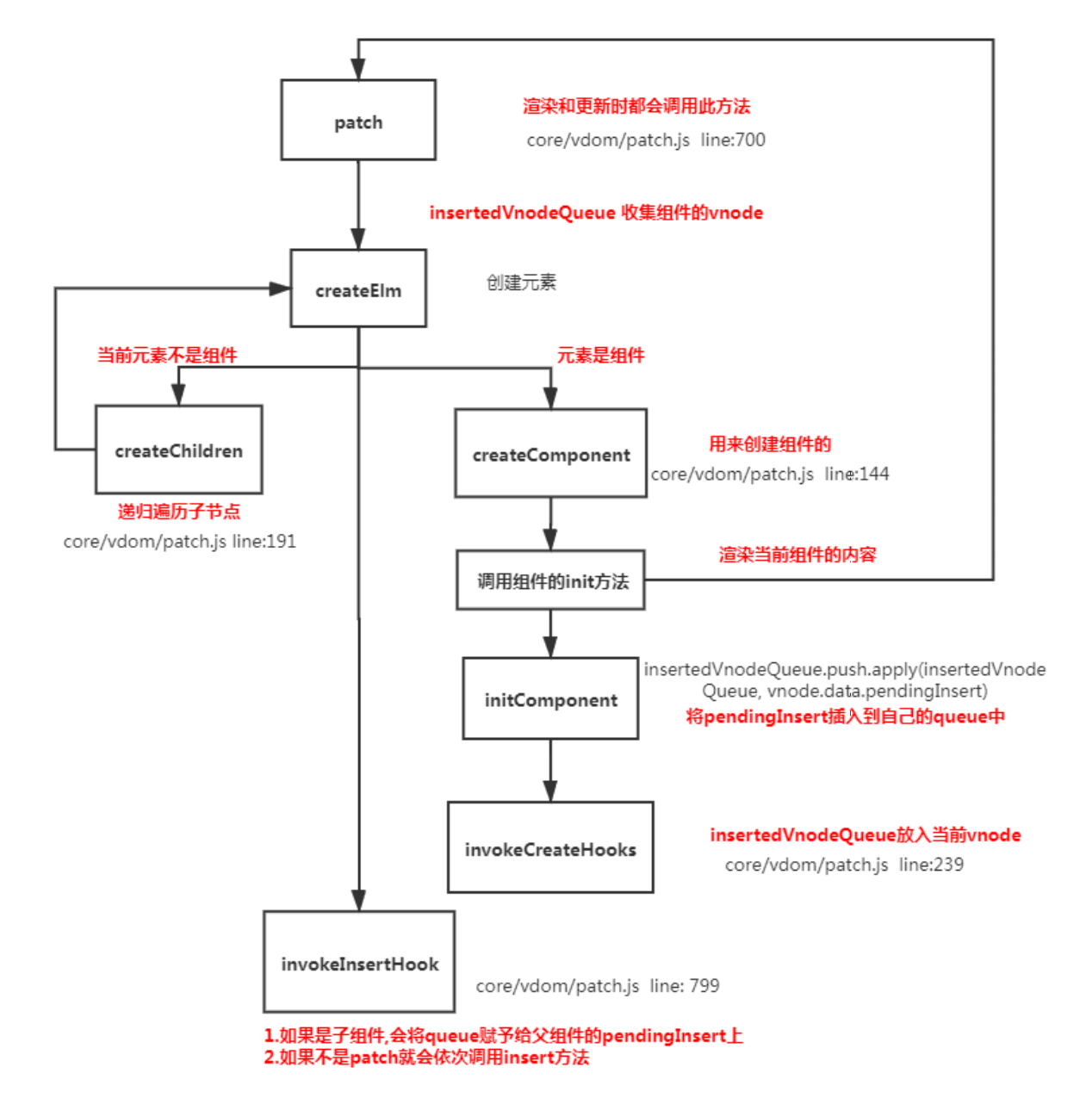
function patch (oldVnode, vnode, hydrating, removeOnly) {
if (isUndef(vnode)) {
if (isDef(oldVnode)) invokeDestroyHook(oldVnode) return
}
let isInitialPatch = false
const insertedVnodeQueue = [] // 定义收集所有组件的insert hook方法的数组 // somthing ...
createElm(
vnode,
insertedVnodeQueue, oldElm._leaveCb ? null : parentElm,
nodeOps.nextSibling(oldElm)
)// somthing...
// 最终会依次调用收集的insert hook
invokeInsertHook(vnode, insertedVnodeQueue, isInitialPatch);
return vnode.elm
}
function createElm ( vnode, insertedVnodeQueue, parentElm, refElm, nested, ownerArray, index ) {
// createChildren 会递归创建儿子组件
createChildren(vnode, children, insertedVnodeQueue) // something...
}
// 将组件的vnode插入到数组中
function invokeCreateHooks (vnode, insertedVnodeQueue) {
for (let i = 0; i < cbs.create.length; ++i) {
cbs.create[i](emptyNode, vnode)
}
i = vnode.data.hook // Reuse variable
if (isDef(i)) {
if (isDef(i.create)) i.create(emptyNode, vnode)
if (isDef(i.insert)) insertedVnodeQueue.push(vnode)
}
}
// insert方法中会依次调用mounted方法
insert (vnode: MountedComponentVNode) {
const { context, componentInstance } = vnode
if (!componentInstance._isMounted) {
componentInstance._isMounted = true
callHook(componentInstance, 'mounted')
}
}
function invokeInsertHook (vnode, queue, initial) {
// delay insert hooks for component root nodes, invoke them after the // element is really inserted
if (isTrue(initial) && isDef(vnode.parent)) {
vnode.parent.data.pendingInsert = queue
} else {
for (let i = 0; i < queue.length; ++i) {
queue[i].data.hook.insert(queue[i]); // 调用insert方法
}
}
}
Vue.prototype.$destroy = function () {
callHook(vm, 'beforeDestroy')
// invoke destroy hooks on current rendered tree
vm.__patch__(vm._vnode, null) // 先销毁儿子
// fire destroyed hook
callHook(vm, 'destroyed')
}
Vue中封装的数组方法有哪些,其如何实现页面更新
在Vue中,对响应式处理利用的是Object.defineProperty对数据进行拦截,而这个方法并不能监听到数组内部变化,数组长度变化,数组的截取变化等,所以需要对这些操作进行hack,让Vue能监听到其中的变化。 那Vue是如何实现让这些数组方法实现元素的实时更新的呢,下面是Vue中对这些方法的封装:
// 缓存数组原型
const arrayProto = Array.prototype;
// 实现 arrayMethods.__proto__ === Array.prototype
export const arrayMethods = Object.create(arrayProto);
// 需要进行功能拓展的方法
const methodsToPatch = [
"push",
"pop",
"shift",
"unshift",
"splice",
"sort",
"reverse"
];
/** * Intercept mutating methods and emit events */
methodsToPatch.forEach(function(method) {
// 缓存原生数组方法
const original = arrayProto[method];
def(arrayMethods, method, function mutator(...args) {
// 执行并缓存原生数组功能
const result = original.apply(this, args);
// 响应式处理
const ob = this.__ob__;
let inserted;
switch (method) {
// push、unshift会新增索引,所以要手动observer
case "push":
case "unshift":
inserted = args;
break;
// splice方法,如果传入了第三个参数,也会有索引加入,也要手动observer。
case "splice":
inserted = args.slice(2);
break;
}
//
if (inserted) ob.observeArray(inserted);// 获取插入的值,并设置响应式监听
// notify change
ob.dep.notify();// 通知依赖更新
// 返回原生数组方法的执行结果
return result;
});
});
简单来说就是,重写了数组中的那些原生方法,首先获取到这个数组的__ob__,也就是它的Observer对象,如果有新的值,就调用observeArray继续对新的值观察变化(也就是通过target__proto__ == arrayMethods来改变了数组实例的型),然后手动调用notify,通知渲染watcher,执行update。
v-model 是如何实现的,语法糖实际是什么?
(1)作用在表单元素上 动态绑定了 input 的 value 指向了 messgae 变量,并且在触发 input 事件的时候去动态把 message设置为目标值:
<input v-model="sth" />
// 等同于
<input v-bind:value="message" v-on:input="message=$event.target.value"
>
//$event 指代当前触发的事件对象;//$event.target 指代当前触发的事件对象的dom;//$event.target.value 就是当前dom的value值;//在@input方法中,value => sth;//在:value中,sth => value;
(2)作用在组件上 在自定义组件中,v-model 默认会利用名为 value 的 prop和名为 input 的事件
本质是一个父子组件通信的语法糖,通过prop和$.emit实现。 因此父组件 v-model 语法糖本质上可以修改为:
<child :value="message" @input="function(e){message = e}"></child>
在组件的实现中,可以通过 v-model属性来配置子组件接收的prop名称,以及派发的事件名称。
例子:
// 父组件
<aa-input v-model="aa"></aa-input>
// 等价于
<aa-input v-bind:value="aa" v-on:input="aa=$event.target.value"></aa-input>
// 子组件:
<input v-bind:value="aa" v-on:input="onmessage"></aa-input>
props:{value:aa,}
methods:{
onmessage(e){
$emit('input',e.target.value)
}
}
默认情况下,一个组件上的v-model 会把 value 用作 prop且把 input 用作 event。但是一些输入类型比如单选框和复选框按钮可能想使用 value prop 来达到不同的目的。使用 model 选项可以回避这些情况产生的冲突。js 监听input 输入框输入数据改变,用oninput,数据改变以后就会立刻出发这个事件。通过input事件把数据$emit 出去,在父组件接受。父组件设置v-model的值为input $emit过来的值。
delete和Vue.delete删除数组的区别
delete只是被删除的元素变成了empty/undefined其他的元素的键值还是不变。Vue.delete直接删除了数组 改变了数组的键值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号