python与正则表达式
正则表达式是什么?可以理解为文本的一种抽象特征,通过特定的符号规则,来对应特定的文本。这里我们实践的是python中的正则表达式。
python中使用正则表达式很简单,包括下面4个简单步骤:
- 引入正则表达式模块,import re;
- 用re.compile()函数创建一个Regex对象;
- 向Regex对象的search()方法传入想要查找的字符串,它返回一个match对象;
- 调用match对象的group()方法,返回实际匹配的字符串。
实操代码如下:
import re
phoneNUmRegex = re.compile(r"\d\d\d-\d\d\d-\d\d\d\d")
mo = phoneNUmRegex.search("my number is 415-555-4242.")
print("phone number found:"+mo.group())
通过上面的代码,你可能明白了正则的难点在哪:compile中的规则定义。python中的正则有哪些可用的规则呢?
进阶
利用括号分组
一个简单的问题,当电话号码中有区号时,如何分离区号和电话号码?在正则表达式中添加括号即可。依旧是上面的代码,改动如下:
import re
phoneNUmRegex = re.compile(r"(\d\d\d)-(\d\d\d-\d\d\d\d)") # 添加括号
mo = phoneNUmRegex.search("my number is 415-555-4242.")
print("zone des found :"+mo.group(1))
print("phone number found:"+mo.group(2))
用管道匹配多个分组
人生面临太多选择,有些人坚定一个方向,一头扎进去;也有些人总是去试试这个,试试那个。当你在正则中想要多个选择时,如何匹配?管道可以帮你解决这个问题,我们来看如下代码:
import re
fruitRegex = re.compile(r"apple|banana") # 管道
f1= fruitRegex.search("apple and orange")
f2 = fruitRegex.search("banana and orange")
print("i like :"+f1.group())
print("i like :"+f2.group())
? or * or + or {}
学习正则时,最容易混淆的是这几个符号,现说明如下:
| 符号 | 说明 |
|---|---|
| ? | 可选匹配,零次或一次,即至多出现一次 |
| * | 零次或多次 |
| + | 一次或多次,即至少出现一次 |
| {} | 特定次数 |
当然你可以用下面的代码实操一下:
import re
chooseRegex = re.compile(r"ba(na)+")
f1= chooseRegex.search("banana")
print("i like "+f1.group())
贪心和非贪心匹配
Python的正则表达式默认是“贪心”的,表示在有二义的情况下,它们会尽可能匹配最长的字符串。下面看一段代码:
"""
import re
greedyHaRegex =re.compile(r"(Ha){3,5}")
mo1 = greedyHaRegex.search("HaHaHaHaHa")
print(mo1.group())
greedyHaRegex1 =re.compile(r"(Ha){3,5}?")
mo2 = greedyHaRegex1.search("HaHaHaHaHa")
print(mo2.group())
两段逻辑的输出如下:
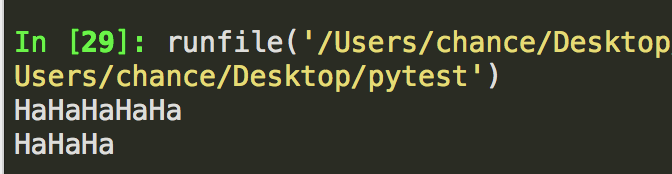
r"(Ha){3,5}" 表示匹配3次或5次,python默认输出5次,当加了问号:r"(Ha){3,5}?",则输出3次。
问号在正则表达式中有两种含义:声明非贪心匹配或表示可选的分组,这两种含义完全无关。
findall() 方法
Regex对象除了search方法外,还有一个findall() 方法。findall() 方法的返回结果有两种情况:
- 如果调用在一个没有分组的正则表达式上,该方法返回一个匹配字符串的列表;
- 如果调用在一个有分组的正则表达式上,返回一个元组列表。
字符分类
列举常用的字符分类的缩写代码如下:
| 缩写字符分类 | 表示 |
|---|---|
| \d | 0-9的任何数 |
| \D | 除0-9的数字以外的任何字符 |
| \w | 任何字母、数字或下划线字符 |
| \W | 除字母、数字和下划线的任何字符 |
| \s | 空格、制表符或者换行符(可以认为匹配“空白”字符) |
| \S | 除空格、制表符和换行符以外的任何字符 |
用方括号定义自己的字符分类
缩写的字符分类太宽泛,你可能需要自己的字符分类,方括号能帮你解决这个问题。想一想如何匹配所有的元音字符?代码如下:
import re
vowelRegex =re.compile(r"[aeiouAEIOU]")
mo1 =vowelRegex.findall("i like banana")
print(mo1)
定位开始(^)和结尾($)
| 符号 | 说明 |
|---|---|
| ^ | 表明匹配必须发生在被查找文件开始处 |
| $ | 表明匹配必须在这个正则表达式的模式结束 |
你可以用下面的代码逻辑实操一下:
import re
begin_end_hello =re.compile("^Hello")
mo1 = begin_end_hello.search("Hello wordl")
print(mo1==None)
通配符(.)
通配符可以匹配除了换行符之外的所有字符,一种特殊的用法:用点-星匹配所有的字符(换行符除外)。那么问题来了,如果我想匹配所有的字符包括换行符,怎么办?这需要在compile方法中填入第二个参数。
compile方法的第二个参数
| 参数 | 说明 |
|---|---|
| re.DOTALL | 可以让句点字符匹配所有字符,包括换行符 |
| re.I | 让正则表达式不区分大小写 |
当然,compile方法的第二个参数可选项远远不止这些,可以去API中查看。
替换字符串(sub)
生活中常有这样的应用场景,在word中全文替换某个单词,你是如何解决的呢?word中提供了批量替换的操作,正则表达式中也有相应的功能,例如:替换某个句子中的人名。实操代码如下:
import re
nameRegex=re.compile("Jerry\w?")
mo1 = nameRegex.sub("Tonny","Tom is a mouse and Jerry is a cat.But Tom can not catch Jerry,and is defeated by Jerry every day.")
print(mo1)
写在最后
这篇文章不是正则的全部,更丰富的功能还需要你自己去挖掘,后续或有更新…

 浙公网安备 33010602011771号
浙公网安备 33010602011771号