
常用10种算法(一)
一、二分查找算法(非递归)
1,递归版二分查找算法
2,非递归二分查找算法介绍
源码:二分查找(非递归)
-
二分查找法只适用于从有序的数列中进行查找(比如数字和字母等),将数列排序后再进行查找
-
二分查找法的运行时间为对数时间 O(㏒₂n) ,即查找到需要的目标位置最多只需要㏒₂n步
3,代码实现
public static int search(int[] arr, int val) { int left = 0; int right = arr.length - 1; while (left <= right) { int mid = (left + right) / 2; if (arr[mid] == val) { return mid; } else if (arr[mid] > val) { right = mid - 1; } else { left = mid + 1; } } return -1; }
二、分治算法
源码:汉诺塔
1,分治算法介绍
分治法是一种很重要的算法。字面上的解释是“分而治之”,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题……直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。
分治算法求解的经典问题:二分搜索、大整数乘法、归并排序、快排、汉诺塔等
2,分治算法基本步骤
分治法在每一层递归上都有三个步骤:
- 分解:将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题
- 解决:若子问题规模较小而容易被解决则直接解,否则递归地解各个子问题
- 合并:将各个子问题的解合并为原问题的解。
3,汉诺塔
a)介绍
如下图所示,从左到右有A、B、C三根柱子,其中A柱子上面有从小叠到大的n个圆盘,现要求将A柱子上的圆盘移到C柱子上去,期间只有一个原则:一次只能移到一个盘子且大盘子不能在小盘子上面,求移动的步骤和移动的次数
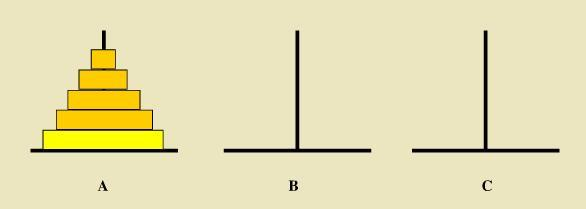
b)思路
- 如果只有一个盘时,A -> C
- 如果有n(大于1)个盘时
- 把n-1个盘 A -> B (借助C)
- 把第n个盘 A -> C
- 把n-1个盘 B -> C (借助A)
c)代码实现
/** * 移动盘子 * @param num 一共有多少个盘子 * @param a 开始的柱子 * @param b 辅助的柱子 * @param c 目标柱子 */ public static void hanoitower(int num, char a, char b, char c) { if (num == 1) { System.out.println("第1个盘为: " + a + " -> " + c); } else { hanoitower(num - 1, a, c, b); System.out.println("第" + num + "个盘为: " + a + " -> " + c); hanoitower(num - 1, b, a, c); } }
三、动态规划
源码:背包问题
1,介绍
-
动态规划(Dynamic Programming)算法的核心思想是:将大问题划分为小问题进行解决,从而一步步获取最优解的处理算法
-
动态规划算法与分治算法类似,其基本思想也是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解。
-
与分治法不同的是,适合于用动态规划求解的问题,经分解得到子问题往往不是互相独立的。 ( 即下一个子阶段的求解是建立在上一个子阶段的解的基础上,进行进一步的求解 )
-
动态规划可以通过填表的方式来逐步推进,得到最优解
2,背包问题
背包问题主要是指一个给定容量的背包、若干具有一定价值和重量的物品,如何选择物品放入背包使物品的价值最大。其中又分 01 背包和完全背包(完全背包指的是:每种物品都有无限件可用)
3,案例
背包问题:有一个背包,容量为 4 磅 , 现有如下物品

- 要求达到的目标为装入的背包的总价值最大,并且重量不超出
-
要求装入的物品不能重复
4,案例分析与求解
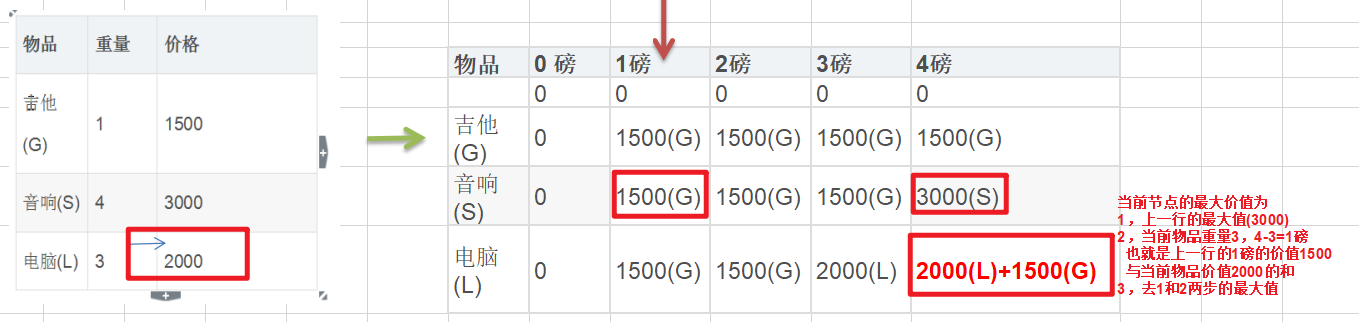
代码实现
/** * 求解01背包问题 * * @param v 商品的价值 * @param w 商品的重量(体积) * @param c 商品的最大容量 */ public static void knapsackDim(int[] v, int[] w, int c) { //初始化二维数组,行表示商品的体积w 列表示容量从0->c int size = w.length; int[][] dp = new int[size + 1][c + 1]; for (int i = 1; i <= size; i++) { for (int j = 0; j <= c; j++) { //当前商品的体积 大于 容量j 时 直接取上一行的数据 dp[i][j] = dp[i - 1][j]; if (w[i-1] <= j) { //①dp[i - 1][j - w[i - 1]]为上一行的当前可用体积-当前商品体积 得到减去当前商品重量之后的最大价值 + v[i-1] //②dp[i][j]实则为上一行的数据 与①直接比较大小 dp[i][j] = Math.max(dp[i][j], v[i - 1] + dp[i - 1][j - w[i - 1]]); } } } }
优化为一维数组
/** * 背包问题优化 使用一维数组 * * @param v 商品的价值 * @param w 商品的重量(体积) * @param c 商品的最大容量 */ public static void knapsackSingle(int[] v, int[] w, int c) { int[] dp = new int[c + 1]; //第一次初始化dp for (int i = 0; i < c + 1; i++) { dp[i] = w[0] > i ? 0 : v[0]; } for (int i = 1; i < w.length; i++) { //防止前面数据被覆盖,从后往前进行遍历 for (int j = c; j >=0; j--) { if (w[i] <= j) { dp[j] = Math.max(dp[j], v[i] + dp[j - w[i]]); } } } }
四、KMP算法
1,暴力匹配算法
源码:暴力匹配
a)思路
如果用暴力匹配的思路,并假设现在 str1 匹配到 i 位置,子串 str2 匹配到 j 位置,则有: 1) 如果当前字符匹配成功(即 str1[i] == str2[j]),则 i++,j++,继续匹配下一个字符 2) 如果失配(即 str1[i]! = str2[j]),令 i = i - (j - 1),j = 0。相当于每次匹配失败时,i 回溯,j 被置为 0。 3) 用暴力方法解决的话就会有大量的回溯,每次只移动一位,若是不匹配,移动到下一位接着判断,浪费了大量 的时间。
b)代码实现
/** * 暴力匹配 * @param str1 原始字符串 * @param str2 匹配字符串 */ public static int violenceMatch(String str1,String str2) { //表示字符串str2的匹配的索引位置 int j; for (int i = 0; i < str1.length();) { j = 0; while (i < str1.length() && j < str2.length() && str1.charAt(i) == str2.charAt(j)) { i++; j++; } //将j匹配到最后一个字符 if (j==str2.length()) { return i-j; } i = i - j + 1; } return -1; }
2,KMP算法
源码:KMP算法
a)思路
-
寻找最长前缀后缀“ABCDABD”
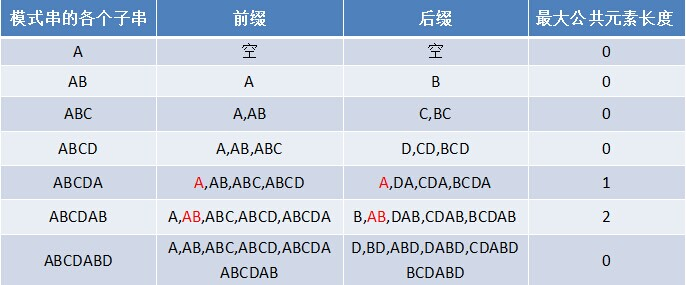
- 获取next数组

-
- 将next 数组相当于“最大长度值” 整体向右移动一位,然后初始值赋为-1
- 若p[k] == p[j],则next[j + 1 ] = next [j] + 1 = k + 1;
- 若p[k ] ≠ p[j],如果此时p[ next[k] ] == p[j ],则next[ j + 1 ] = next[k] + 1,否则继续递归前缀索引k = next[k],而后重复此过程。
- 解释为: 如下图所示,假定给定模式串ABCDABCE,且已知next [j] = k(相当于“p0 pk-1” = “pj-k pj-1” = AB,可以看出k为2),现要求next [j + 1]等于多少?因为pk = pj = C,所以next[j + 1] = next[j] + 1 = k + 1(可以看出next[j + 1] = 3)。代表字符E前的模式串中,有长度k+1 的相同前缀后缀。
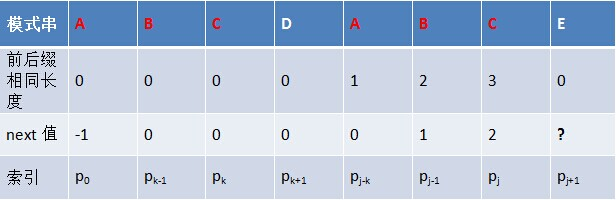
- 但如果pk != pj 呢?说明“p0 pk-1 pk” ≠ “pj-k pj-1 pj”。换言之,当pk != pj后,字符E前有多大长度的相同前缀后缀呢?很明显,因为C不同于D,所以ABC 跟 ABD不相同,即字符E前的模式串没有长度为k+1的相同前缀后缀,也就不能再简单的令:next[j + 1] = next[j] + 1 。所以,咱们只能去寻找长度更短一点的相同前缀后缀。
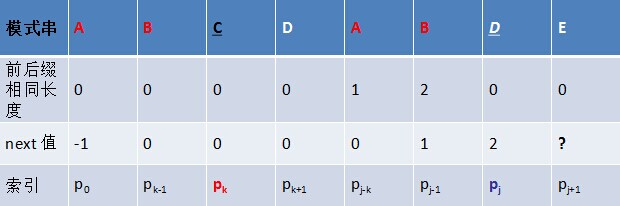
-
/** * 求出一个字符数组的next数组 * * @param p 字符数组 * @return next数组 */ public static int[] getNextArray(char[] p) { int[] next = new int[p.length]; next[0] = -1; int k = -1; int j = 0; while (j < p.length - 1) { //p[k]表示前缀 p[j]表示后缀 if (k == -1 || p[j] == p[k]) { // k++; // j++; next[++j] = ++k; } else { k = next[k]; } } return next; }
-
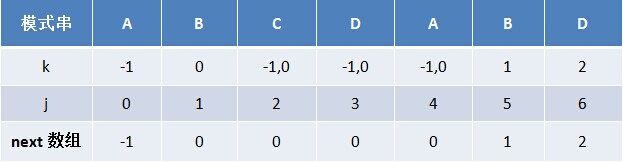
- 基于next数组开始进行匹配
- P[0]跟S[0]匹配失败。所以执行“如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]”,所以j = -1,故转而执行“如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++”,得到i = 1,j = 0,即P[0]继续跟S[1]匹配。
- P[0]跟S[1]又失配,j再次等于-1,i、j继续自增,从而P[0]跟S[2]匹配。
- 直到P[0]跟S[4]匹配成功,开始执行此条指令的后半段:“如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++”。

- P[1]跟S[5]匹配成功,P[2]跟S[6]也匹配成功, ...,直到当匹配到P[6]处的字符D时失配(即S[10] != P[6]),由于P[6]处的D对应的next 值为2,所以下一步用P[2]处的字符C继续跟S[10]匹配,相当于向右移动:j - next[j] = 6 - 2 =4 位。

- 向右移动4位后,P[2]处的C再次失配,由于C对应的next值为0,所以下一步用P[0]处的字符继续跟S[10]匹配,相当于向右移动:j - next[j] = 2 - 0 = 2 位。

-
移动两位之后,A 跟空格不匹配,模式串后移1 位。
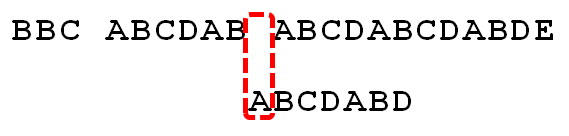
- P[6]处的D再次失配,因为P[6]对应的next值为2,故下一步用P[2]字符C继续跟文本串匹配,相当于模式串向右移动 j - next[j] = 6 - 2 = 4 位。

-
匹配成功,过程结束。

-
匹配过程一模一样。也从侧面佐证了,next 数组确实是只要将各个最大前缀后缀的公共元素的长度值右移一位,且把初值赋为-1 即可。
-
/** * 对主串s和模式串t进行KMP模式匹配 * * @param s 主串 * @param t 模式串 * @return 若匹配成功,返回t在s中的位置(第一个相同字符对应的位置),若匹配失败,返回-1 */ public static int kmpMatch(String s, String t) { char[] s_arr = s.toCharArray(); char[] t_arr = t.toCharArray(); int[] next = getNextArray(t_arr); int i = 0, j = 0; while (i < s_arr.length && j < t_arr.length) { if (j == -1 || s_arr[i] == t_arr[j]) { i++; j++; } else j = next[j]; } if (j == t_arr.length) return i - j; else return -1; }
五、贪心算法
1,应用场景
假设存在下面需要付费的广播台,以及广播台信号可以覆盖的地区。 如何选择最少的广播台,让所有的地区都可以接收到信号。

2,贪心算法介绍
-
贪婪算法(贪心算法)是指在对问题进行求解时,在每一步选择中都采取最好或者最优(即最有利)的选择,从而希望能够导致结果是最好或者最优的算法
- 贪婪算法所得到的结果不一定是最优的结果(有时候会是最优解),但是都是相对近似(接近)最优解的结果
3,问题求解
a)思路分析
- 使用穷举法实现,列出每个可能的广播台的集合,这被称为幂集。假设总的有 n 个广播台,则广播台的组合总共有2ⁿ -1
-
使用贪婪算法,效率高
- 遍历所有的广播电台,找到一个覆盖了最多未覆盖的地区的电台(采用retainAll方法,将当前集合与选择集合的交集赋值给当前集合)
- 将这个电台加入到集合中,去除该电台覆盖的地区
- 重复以上,直至覆盖所有的地区
b)代码实现
public static void main(String[] args) { Map<String, Set<String>> map = new HashMap<>(); Set<String> set1 = new HashSet<>(); set1.add("北京"); set1.add("上海"); set1.add("天津"); Set<String> set2 = new HashSet<>(); set2.add("广州"); set2.add("北京"); set2.add("深圳"); Set<String> set3 = new HashSet<>(); set3.add("成都"); set3.add("上海"); set3.add("杭州"); Set<String> set4 = new HashSet<>(); set4.add("上海"); set4.add("天津"); Set<String> set5 = new HashSet<>(); set5.add("杭州"); set5.add("大连"); map.put("K1", set1); map.put("K2", set2); map.put("K3", set3); map.put("K4", set4); map.put("K5", set5); Set<String> allAreas = new HashSet<>(); allAreas.addAll(set1); allAreas.addAll(set2); allAreas.addAll(set3); allAreas.addAll(set4); allAreas.addAll(set5); //存储选择的key List<String> selects = new ArrayList<>(); //定义此时最大的key String maxKey; //临时存储的set集合 Set<String> tempSet = new HashSet<>(); //如果allArea不为空则一直删除 while (allAreas.size() != 0) { //清空临时set tempSet.clear(); // maxSize = 0; maxKey = null; for (Map.Entry<String, Set<String>> entry : map.entrySet()) { tempSet = entry.getValue(); tempSet.retainAll(allAreas); if (tempSet.size() > 0 && (maxKey == null || tempSet.size() > map.get(maxKey).size())) { maxKey = entry.getKey(); } } if (maxKey != null) { tempSet = map.get(maxKey); selects.add(maxKey); allAreas.removeAll(tempSet); //此时可以将对应的key去除,这样能在遍历map的时候提高效率 map.remove(maxKey); } } System.out.println(selects); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号