Python爬取字幕文件保姆级笔记
需要用到的包有:
- requests 发起GET请求
- bs4.BeautifulSoup 解析网页
- fake_useragent.UserAgent 随机用户代理
搜先找到字幕库的搜索页面,地址是 http://www.zimuku.la/search?q=,十分好找。界面如下:
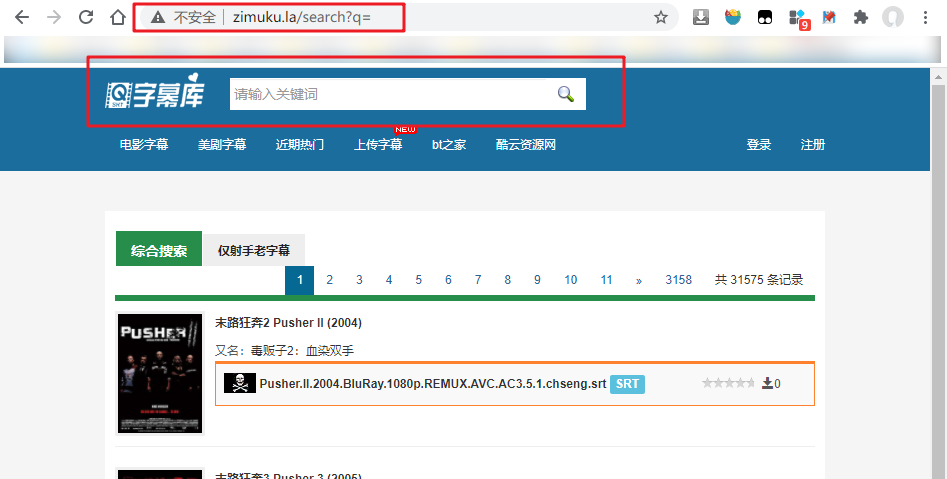
以《小鬼当家2》为例搜索字幕资源:
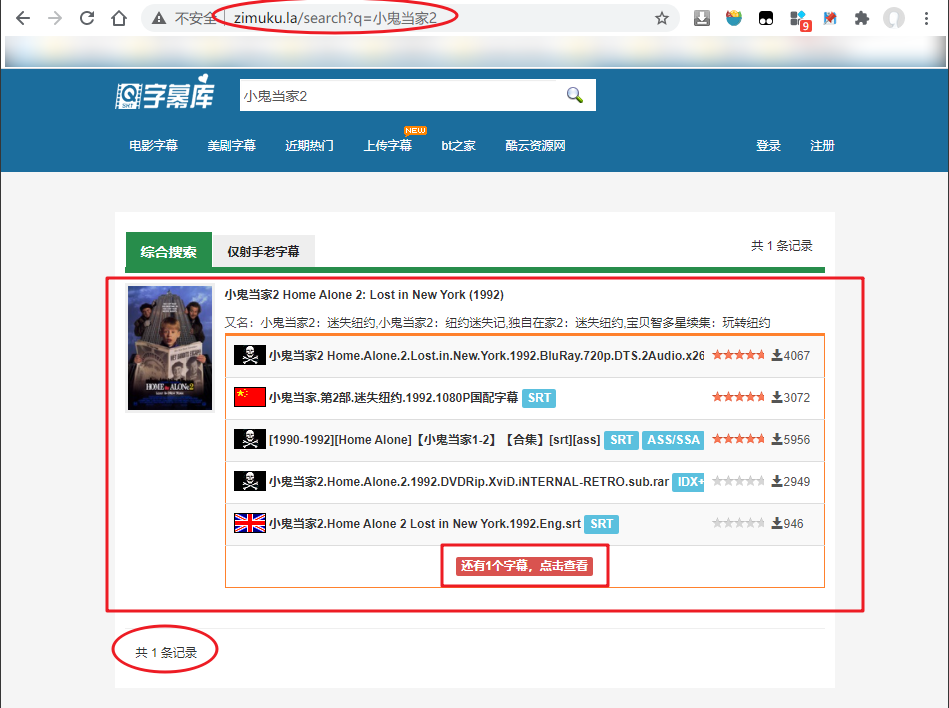
需要注意的地方有:
- 搜索结果的URL格式是
http://www.zimuku.la/search?q=电影名称 - 这个页面并没有显示所有资源,因为还有 “点击查看” 字样
尝试点击 “还有1个字幕,点击查看” 字样,跳转到新的页面:http://www.zimuku.la/subs/32745.html
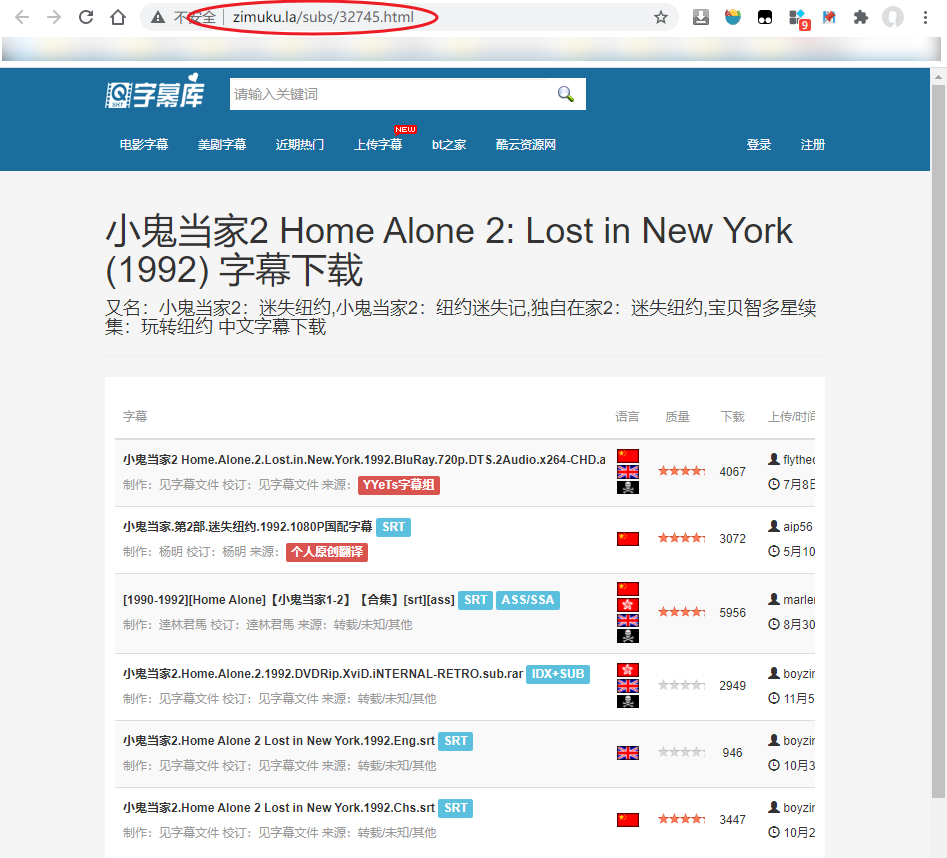
这个页面需要一个类似于ID的东西,目前我们不知道。而且,我们不能保证是不是每次搜索都需要额外的跳转展开资源列表。所以,我们还是从前一个页面入手。
F12 检查元素,可以发现,资源列表的位置:
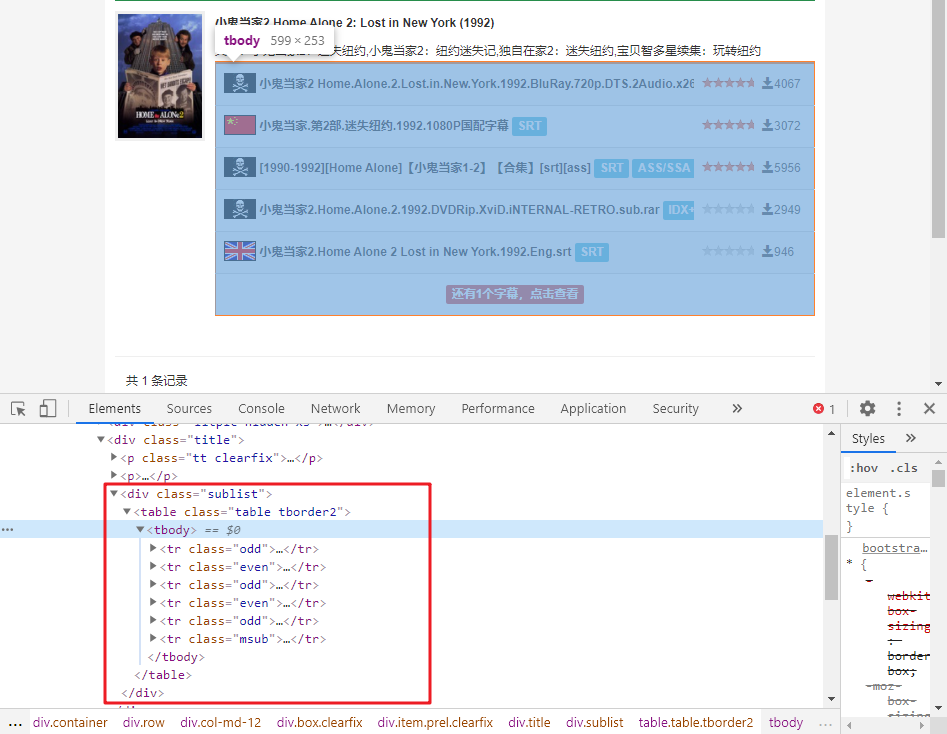
它位于 div[class="sublist"] 标签内的表格中,我们使用 BeautifulSoup 定位到这个表格:
html = BeautifulSoup(reponse.text, 'lxml')
sublist = html.select_one('div[class="sublist"]')
sublist = sublist.select('tr')
sublist 是 tr 标签的列表,它分别对应着图中的资源条目。观察 tr 标签的 class 属性,前五个 tr 标签都是 odd 或者 even,它们表示 tr 标签所在位置的奇偶性。第六个 tr 标签的 class 值为 msub,这似乎不同寻常。事实上,它表示的是 more subtitles。
查看 tr[class=“msub”] 这个标签我们可以发现它提供了一个链接指向了列举所有资源条目那个页面。所以我们的策略是:
- 如果结果页中没有 tr[class=“msub”] 标签,直接解析结果页的资源条目;
- 如果结果页中有 tr[class=“msub”] 标签,拿到它里面的URL,解析这个URL对应页面的条目。
解析资源条目的代码如下:
title = "小鬼当家2"
url = "http://www.zimuku.la/search?q={}".format(title)
response = get_with_ntries(url, session=session)
html = BeautifulSoup(response.text, "lxml")
sublist = html.select_one('div[class="sublist"]')
sublist = sublist.select('tr')
msub = [_ for _ in sublist if "msub" in _.get("class")]
if len(msub) > 0:
url = "http://www.zimuku.la" + trs[-1].a.get("href")
response = get_with_ntries(msubUrl, session=session)
html = BeautifulSoup(response.text, "lxml")
tbody = html.select_one('table[id="subtb"]').tbody
sublist = tbody.select('tr')
到这里为止,我们将资源条目保存在了 sublist 中,每个条目对应一个 tr 标签,它的 class 值为 odd 或者 even。
接下来,从资源条目中解析出需要的具体信息:
subData = []
for idx,oSub in enumerate(sublist):
oFirstTd = oSub.select_one('td[class="first"]')
# 字幕文件名
subTitle = oFirstTd.b.text
# 字幕文件详情页面
subDetailURL = "http://www.zimuku.la" + oFirstTd.a.get("href")
# 字幕类型列表
subTypes = [_.text for _ in oFirstTd.select('span[class="label label-info"]')]
oLangTd = oSub.select_one('td[class="tac lang"]')
# 字幕语言类型
subLangs = [_.get("alt") for _ in oLangTd.select("img")]
subData.append({
"title": subTitle,
"url": subDetailURL,
"types": subTypes,
"langs": subLangs
})
到这里,我们将每个资源条目的具体信息保存到了 subData 中,如下:
[{'title': '小鬼当家2 Home.Alone.2.Lost.in.New.York.1992.BluRay.720p.DTS.2Audio.x264-CHD.ass',
'url': 'http://www.zimuku.la/detail/120516.html',
'types': ['ASS/SSA'],
'langs': ['简体中文', 'English', '双语']},
{'title': '小鬼当家.第2部.迷失纽约.1992.1080P国配字幕',
'url': 'http://www.zimuku.la/detail/88262.html',
'types': ['SRT'],
'langs': ['简体中文']},
{'title': '[1990-1992][Home Alone]【小鬼当家1-2】【合集】[srt][ass]',
'url': 'http://www.zimuku.la/detail/75276.html',
'types': ['SRT', 'ASS/SSA'],
'langs': ['简体中文', '繁體中文', 'English', '双语']},
{'title': '小鬼当家2.Home.Alone.2.1992.DVDRip.XviD.iNTERNAL-RETRO.sub.rar',
'url': 'http://www.zimuku.la/detail/44610.html',
'types': ['IDX+SUB'],
'langs': ['繁體中文', 'English', '双语']},
{'title': '小鬼当家2.Home Alone 2 Lost in New York.1992.Eng.srt',
'url': 'http://www.zimuku.la/detail/44818.html',
'types': ['SRT'],
'langs': ['English']},
{'title': '小鬼当家2.Home Alone 2 Lost in New York.1992.Chs.srt',
'url': 'http://www.zimuku.la/detail/44817.html',
'types': ['SRT'],
'langs': ['简体中文']}]
我们点击任意一个条目,进入到资源的详情页面:
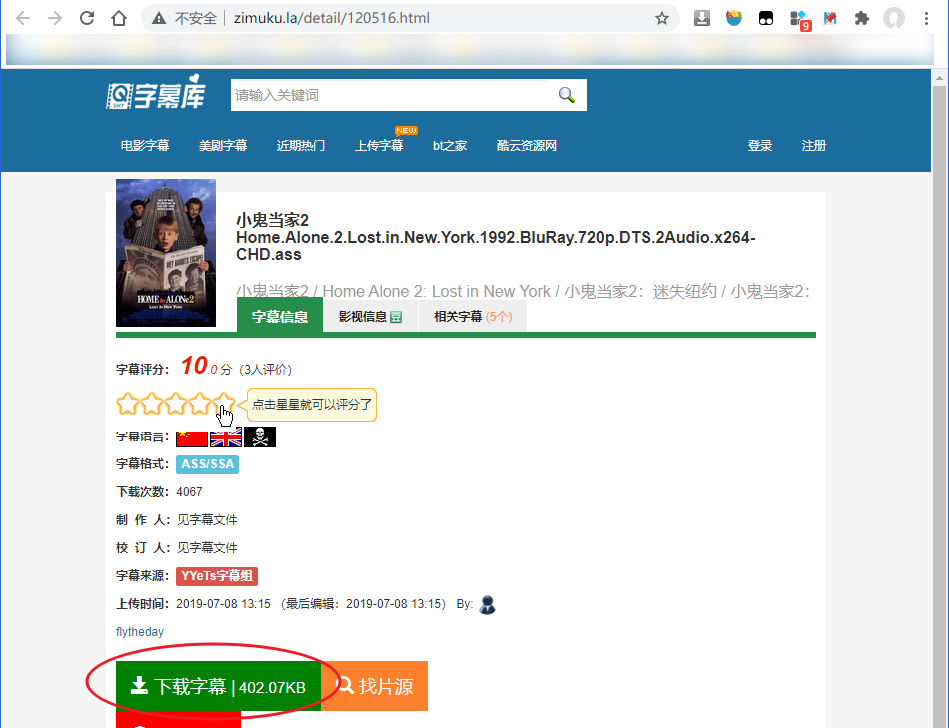
通过检查元素,获取到上图 “下载字幕” 按钮的URL是 http://zmk.pw/dld/120516.html,点击按钮可进入下载通道列表页面:
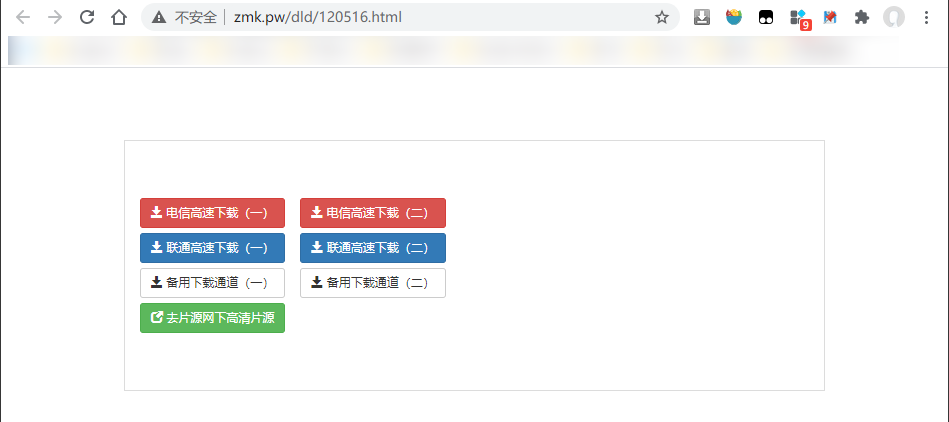
这里需要注意的是,我们并不需要在程序中请求资源的详情页面来获取下载通道页面的URL。因为在资源的搜索页面我们已经拿到了URL http://www.zimuku.la/detail/120516.html,这个URL已经包含了资源的ID信息,我们只需要把ID填到通道页面的URL模板中即可:http://zmk.pw/dld/{}.html。
url = 'http://www.zimuku.la/detail/120516.html'
subid = url.split('/')[-1].split('.')[0]
channels_url = 'http://zmk.pw/dld/{}.html'.format(subid)
channels_rps = get_with_ntries(channels_url)
channels_bs = BeautifulSoup(channels_rps.text, 'lxml')
在下载通道页按F12打开调试界面,切换到 Network 标签,刷新页面,可以看到下面只有 6 个条目:
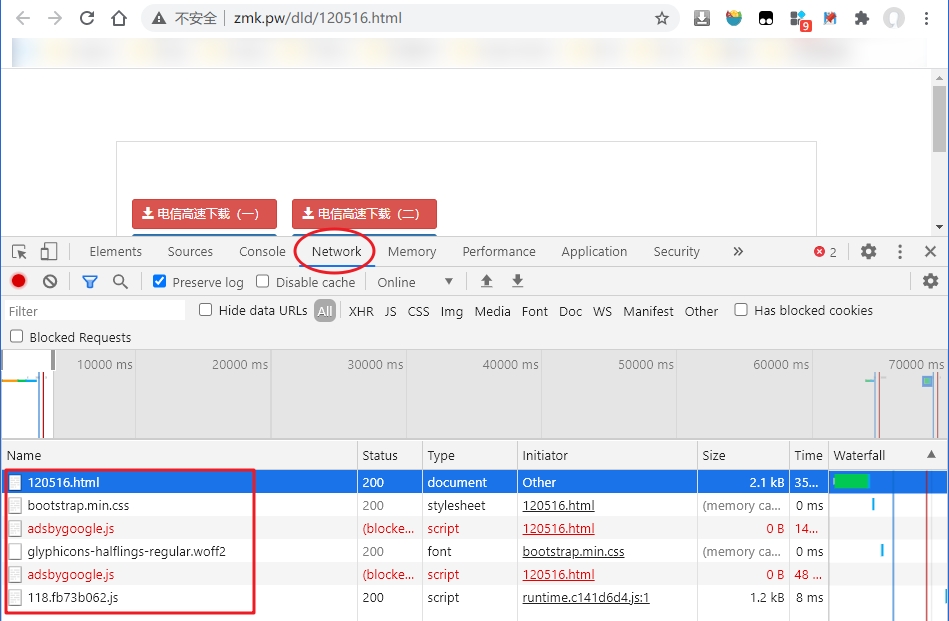
我们点击第一个下载通道,即 电信高速下载(一),弹出保存文件的窗口,可以看到,我们想要的文件已经正确拿到了,我们先点击确定保存,然后在下载管理器中查看下载的文件的URL:
http://static.zimuku.la/download/MjAxOS0wNy0wOCUyRjVkMjJkMTRkZTkzMDQuYXNzfEhvbWUuQWxvbmUuMi5Mb3N0LmluLk5ldy5Zb3JrLjE5OTIuQmx1UmF5LjcyMHAuRFRTLjJBdWRpby54MjY0LUNIRC5hc3N8MTYwODk3MDAzMnwxZDk4OTZkMnw%3D
我们可以在命令行中用 curl 检验一下这个 URL 能否下载到我们想要的资源
curl -o test.ass http://static.zimuku.la/download/MjAxOS0wNy0wOCUyRjVkMjJkMTRkZTkzMDQuYXNzfEhvbWUuQWxvbmUuMi5Mb3N0LmluLk5ldy5Zb3JrLjE5OTIuQmx1UmF5LjcyMHAuRFRTLjJBdWRpby54MjY0LUNIRC5hc3N8MTYwODk3MDAzMnwxZDk4OTZkMnw%3D
然后就可以在当前目录下看到 test.ass 这个资源了,可以用记事本打开它查看是否有效。这里需要注意的是,使用 curl 时需要用 -o 指定输出文件,因为URL没有提供可用的文件名称。
我们回到浏览器中,可以看到此时后台多了四个条目:
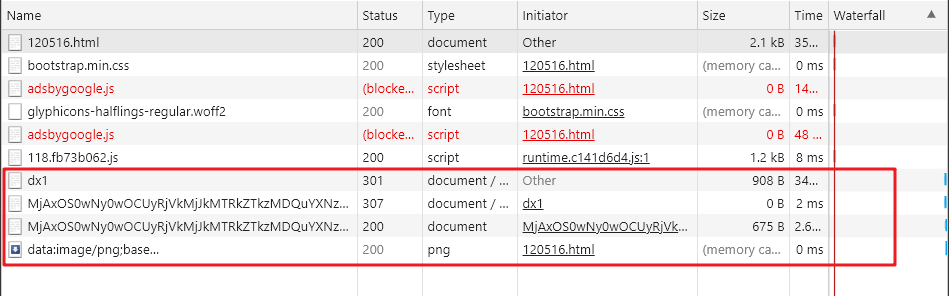
先看第一个 dx1:
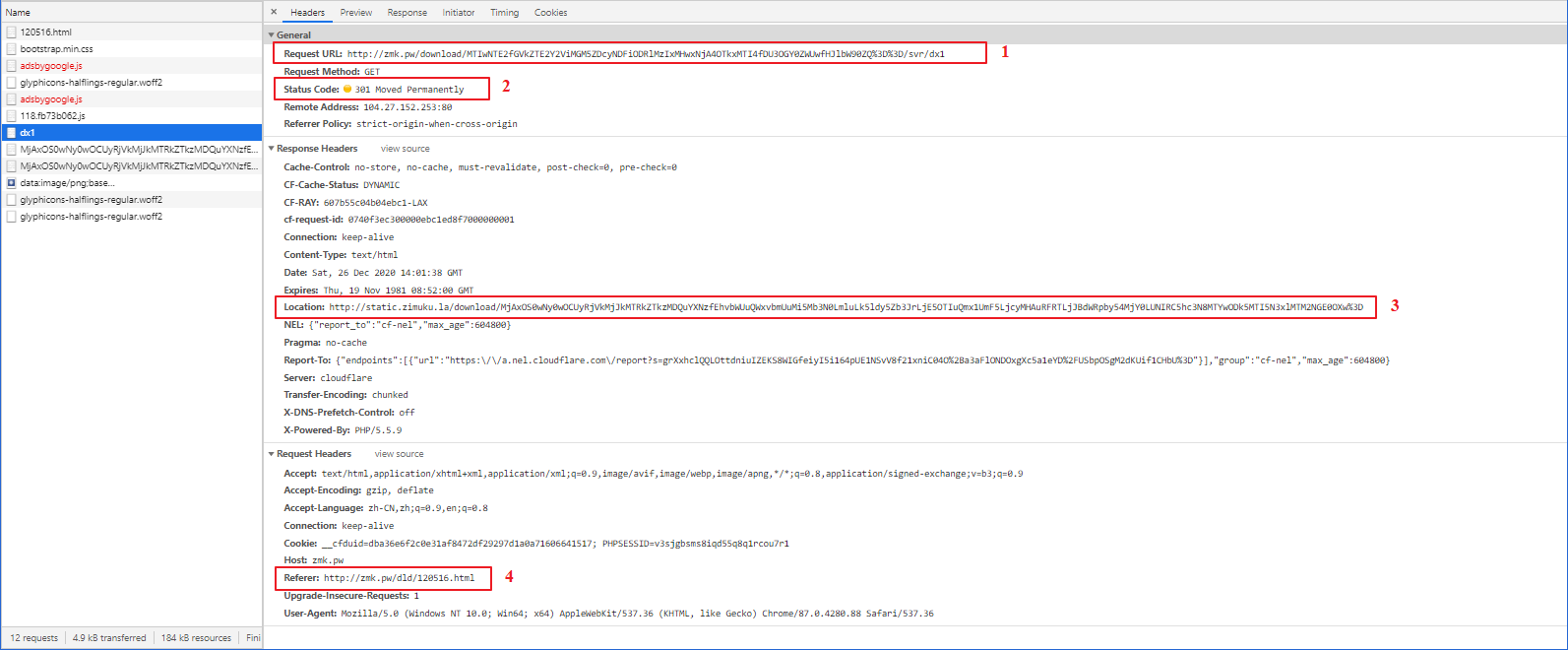
我标出了四个重点关注的地方:
- 通过元素检查可以发现,这个 URL 与 电信高速下载(一) 中的 URL 一致
- 状态码显示,该 URL 已被永久移除。但是我们在浏览器中直接访问这个 URL,发现它竟然跳转到了资源详情页面( http://www.zimuku.la/detail/120516.html ),这表示它经历了一次重定向
- 这个 URL 与我们下载文件显示的 URL 是一致的,我们需要的就是这个 URL,它位于 dx1 请求的 响应头 中,所以我们需要发起这个 dx1 请求,然后拿到它的 响应头
- dx1 请求需要设置当前页面 URL 为 referer 防盗
所以接下来,我们构造这个会被重定向的请求,并且从响应头中拿到下载的真实URL:
rd_url = 'http://zmk.pw' + channels_bs.select_one('div[class="down clearfix"]').a.get('href')
rd_rps = get_with_ntries(rd_url, headers={'Referer': channels_url}, allow_redirects=False)
dl_url = rd_rps.headers['Location']
这里:
- 防盗链:在 headers 中设置 Referer 字段
- allow_redirects=False 禁止重定向,这样能拿到直接请求URL的结果
然后调用 curl 下载资源:
os.system('curl -o "{}" "{}"'.format(fp, dl_url))
有时候下载的资源没有文件类型后缀,它极有可能是一个压缩文件,可以自行检测文件类型,并添加类型后缀字符串。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号