
EM算法原理:
EM算法一般用于无监督学习模型,因为无监督学习没有标签(即y值),EM算法可以先给无监督学习估计一个隐状态(即标签),有了标签,算法模型就可以转换成有监督学习,这时就可以用极大似然估计法求解出模型最优参数。其中估计隐状态流程应为EM算法的E步,后面用极大似然估计为M步。
EM算法(Expectation Maximization Algoithm,最大期望参数)是一种迭代类型的算法,是一种 在概率模型中寻找参数最大似然估计或者最大后验估计的算法。
EM算法流程:
1、初始化分布参数
2、重复下面两个步骤直到模型收敛
E步骤,估计隐藏变量的概率分布期望函数
M步骤,根据期望函数重新估计分布参数
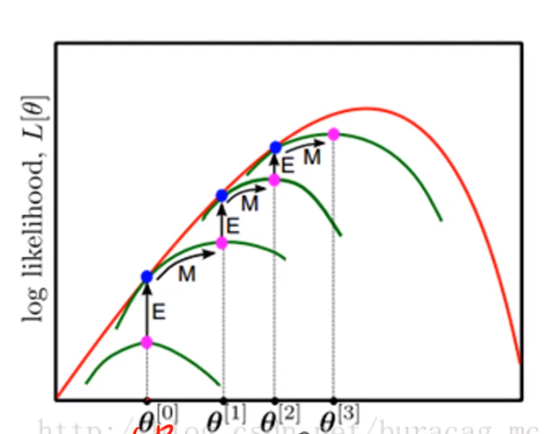
图解EM算法原理:
首先给定一个初始值∂^0,这时可以通过极大似然函数求解出一个新的∂^1,再把∂^1作为新的极大似然函数的参数,求得∂^2,然后不断的迭代,最后生成∂不会变,即迭代终止。求得最终解
