

第三次作业 词频统计
一、
学号:2017035107002
姓名:班雪
完整代码如下:
# filename: word_freq.py
# 注意:代码风格
from string import punctuation
def process_file(dst): # 读文件到缓冲区
try: # 打开文件
f = open(dst,"r")
except IOError as s:
print (s)
return None
try: # 读文件到缓冲区
bvffer = f.read()
except:
print ("Read File Error!")
return None
f.close()
return bvffer
def process_buffer(bvffer):
if bvffer:
word_freq = {}
bvffer = bvffer.lower()
for fh in ',.!?+-_':
bvffer = bvffer.replace(fh, " ")
words = bvffer.strip().split()
for word in words:
word_freq[word] = word_freq.get(word, 0) + 1
return word_freq
def output_result(word_freq):
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
for item in sorted_word_freq[:10]: # 输出 Top 10 的单词
print(item)
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('dst')
args = parser.parse_args()
dst = args.dst
bvffer = process_file(dst)
word_freq = process_buffer(bvffer)
output_result(word_freq)
二、程序分析
1)读取文件

2)设置缓冲区,对文本特殊符号进行修改,并读入字典
3)设置输出函数,进行排序并输出。
4)封装main函数

三、统计结果
1、大文件运行命令:
python word_freq.py Gone_with_the_wind.txt
结果

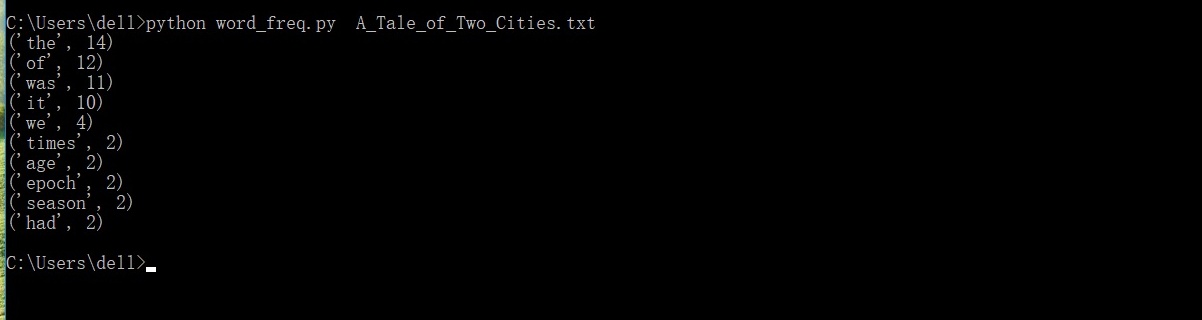
2、小文件运行命令:
python word_freq.py A_Tale_of_Two_Cities
运行结果:
![]()
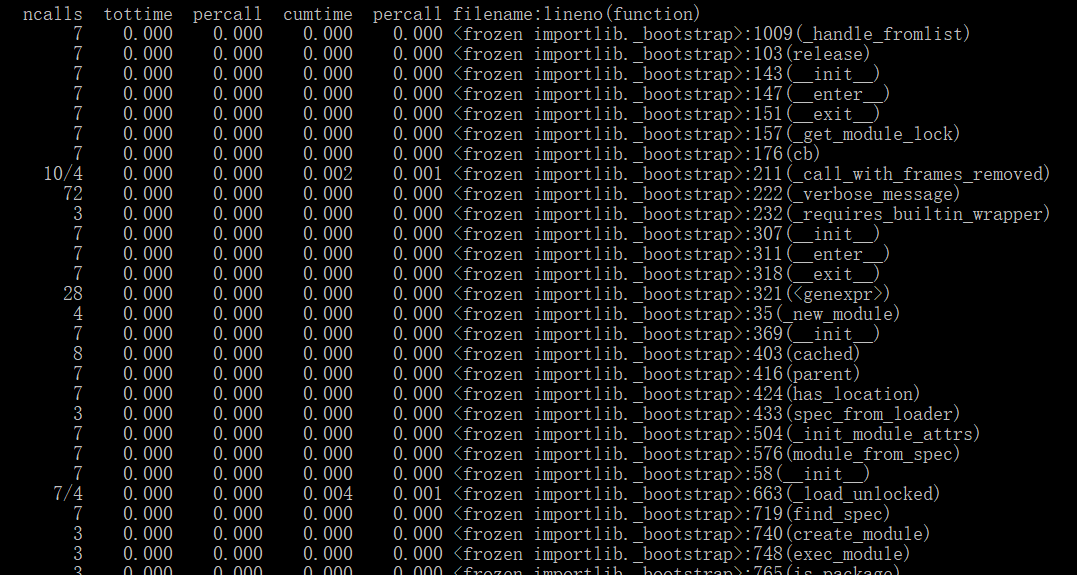
3、执行次数最多的代码,执行时间最长的代码
![]()
4、分析结果
![]()
四、总结
对git还是不太了解,需要进一步的掌握,学会了了简单的词频统计的操作,运用的还是不够熟练 ,需要加快运行词频统计的操作

---恢复内容结束---

 浙公网安备 33010602011771号
浙公网安备 33010602011771号