

YOLOv11改进 - C3k2融合 | C3k2融合CBSA 收缩 - 广播自注意力:轻量级设计实现高效特征压缩,优化处理效率 | NeurIPS 2025
前言
本文介绍收缩 - 广播自注意力(CBSA)((Contract-and-Broadcast Self-Attention))机制,并将其集成到YOLOv11中。传统注意力机制存在黑盒难理解、计算复杂度高的问题,CBSA通过算法展开推导出本质上可解释且高效的注意力机制。它先从输入数据中选出少量代表性tokens,接着对代表进行收缩计算,再将结果广播给所有原始数据。该机制计算量线性增长,具有明确数学解释,还能统一多种注意力机制。我们将CBSA代码集成到YOLOv11的C3k2模块中。实验证明,改进后的YOLOv11在视觉任务上有可比性能和优越优势。
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv11改进专栏
介绍

摘要
注意力机制在多个领域取得了显著的实证成功,但它们的基础优化目标仍不明确。此外,自注意力的二次复杂度变得越来越难以承受。虽然可解释性和效率是两个相互促进的追求,但先前的工作通常分开研究它们。在本文中,我们提出了一个统一的优化目标,通过算法展开推导出本质上可解释且高效的注意力机制。具体而言,我们构建了所提出目标的一个梯度步骤,其中包含我们的收缩-广播自注意力(CBSA)的一系列前向传递操作,该机制通过收缩输入标记的少量代表来将输入标记压缩到低维结构。这种新颖的机制不仅可以通过固定代表数量来实现线性扩展,还可以在使用不同代表集时涵盖各种注意力机制的实例化。我们进行了广泛的实验,证明了与黑盒注意力机制相比,在视觉任务上具有可比的性能和优越的优势。我们的工作阐明了可解释性和效率的整合,以及注意力机制的统一公式
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
一、核心定位:给注意力机制“拆黑盒、提速度、做统一”
传统注意力机制(比如Transformer里的softmax注意力)有两个大问题:
- “黑盒难理解”:模型为啥关注数据的某个部分、背后的决策逻辑是什么,说不清楚;
- “计算太笨重”:处理长数据(比如高清图的像素块、长文档的词语)时,要算所有数据点之间的关系,数据越长,计算量呈“平方级”暴涨,实际用起来很卡。
之前的研究要么只解决“理解”,要么只解决“速度”,CBSA则想一次性搞定——既让注意力机制的工作过程“说得通”,又让它“跑得飞快”,甚至还能把不同类型的注意力(比如softmax注意力、线性注意力)统一成一个框架。
二、设计逻辑:“抓少数代表,搞定所有数据”
CBSA的核心思路特别像“老师批改作业”:不用逐题看每个学生的作业,先挑几个有代表性的同学(比如中等水平、能反映全班共性问题的),只批改这几个“代表”的作业,再把批改思路告诉全班,大家各自修正。具体分两步:
1. 第一步:选“数据代表”(代表性 tokens)
从输入数据(比如图片的像素块、文本的词语)里,通过简单计算挑出少量“代表”——这些“代表”不是随机选的,而是能抓住数据核心特征的(类似聚类里的“中心点”,但会动态调整)。
比如处理一张高清图时,不用关注每一个像素,而是先选出几十个能代表图片关键区域(比如物体边缘、纹理)的“像素代表”。
2. 第二步:“收缩代表+广播结果”
- 收缩代表:只对这几个“代表”做复杂计算(比如提炼关键信息、优化特征),大幅减少计算量;
- 广播结果:把“代表”的计算结果,通过简单的映射传递给所有原始数据,让所有数据都能学到“代表”的关键信息。
就像老师把“代表作业”的批改思路告诉全班,每个学生都能根据这个思路修正自己的作业,既省时间,又知道“为啥这么改”。
三、关键优势:又快、又懂、还“万能”
1. 速度快:计算量“线性增长”
传统注意力处理N个数据点,计算量是“N的平方”(数据翻倍,计算量翻4倍);而CBSA只算少量“代表”,计算量和数据量呈“线性增长”(数据翻倍,计算量也只翻倍)。
实验里提到,处理高清图(比如512×512像素)时,CBSA的训练和推理速度比传统注意力快2倍以上,参数还更少(比如CBT-Small模型只用ViT-S 30%的参数、40%的计算量,就能达到差不多的精度)。
2. 易理解:不是“黑盒”,逻辑透明
CBSA的每一步都有明确的数学解释:选“代表”是为了抓住数据核心,“收缩”是为了优化特征,“广播”是为了传递信息——整个过程像“拆解问题、解决核心、推广结果”,不像传统注意力那样“不知道为啥这么算”。
比如实验中观察到,CBSA能把杂乱的数据(比如带噪声的点)逐步压缩成规整的“低维结构”(类似把同类数据聚成清晰的簇),这个过程能直观看到,不用“猜模型在想什么”。
3. 万能:能统一所有经典注意力
最厉害的是,CBSA能“变”成其他注意力机制——只要换不同的“代表”选择方式:
- 选“所有数据当代表”,CBSA就等同于传统的softmax注意力;
- 选“正交的代表”(比如数据的主方向),CBSA就变成线性注意力;
- 选“固定方向的代表”,CBSA就变成通道注意力(比如SE、CBAM里的通道优化)。
相当于给不同的注意力机制找了个“统一公式”,能清晰看到它们的本质区别(只是“代表”的选择方式不同)。
核心代码
class CBSA(nn.Module):
def __init__(self, dim, heads, dim_head):
super().__init__()
inner_dim = heads * dim_head
self.heads = heads
self.dim_head = dim_head
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim=-1)
self.proj = nn.Linear(dim, inner_dim, bias=False)
self.step_x = nn.Parameter(torch.randn(heads, 1, 1))
self.step_rep = nn.Parameter(torch.randn(heads, 1, 1))
self.to_out = nn.Linear(inner_dim, dim)
self.pool = nn.AdaptiveAvgPool2d(output_size=(8, 8))
self.qkv = nn.Identity()
def attention(self, query, key, value):
dots = (query @ key.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
out = attn @ value
return out, attn
def forward(self, x, return_attn=False):
b, n, c = x.shape
h = width = int(n ** 0.5)
w = self.proj(x)
self.qkv(w)
rep = self.pool(w[:, :-1, :].reshape(b, h, width, c).permute(0, 3, 1, 2)).reshape(b, c, -1).permute(0, 2, 1)
w = w.reshape(b, n, self.heads, self.dim_head).permute(0, 2, 1, 3)
rep = rep.reshape(b, 64, self.heads, self.dim_head).permute(0, 2, 1, 3)
rep_delta, attn = self.attention(rep, w, w)
if return_attn:
return attn.transpose(-1, -2) @ attn
rep = rep + self.step_rep * rep_delta
x_delta, _ = self.attention(rep, rep, rep)
x_delta = attn.transpose(-1, -2) @ x_delta
x_delta = self.step_x * x_delta
x_delta = rearrange(x_delta, 'b h n k -> b n (h k)')
return self.to_out(x_delta)
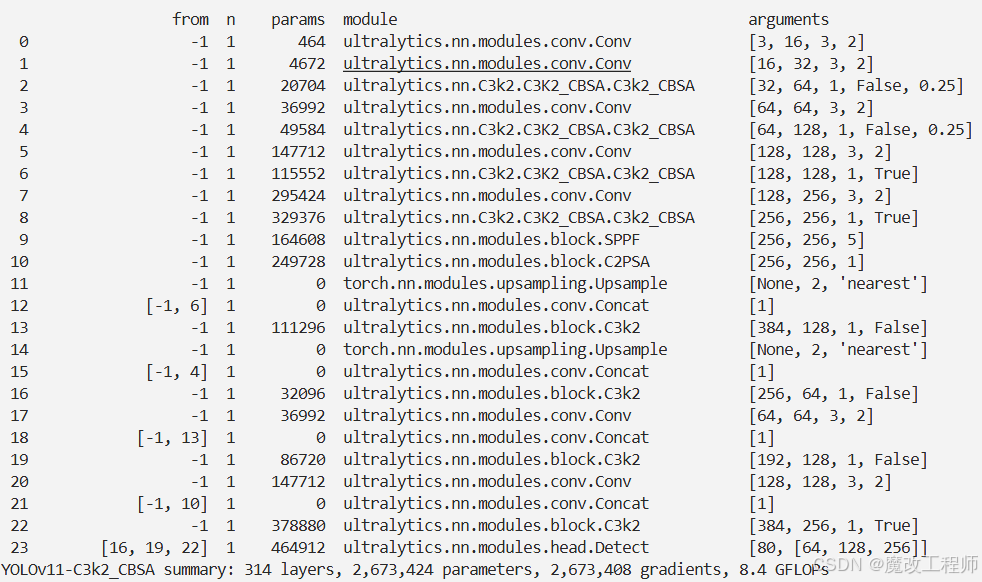
结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号