

【大模型】通信元语和相关概念|NCCL梯度|Allreduce|Scatter|Broadcast|Gather
目录
学习nccl时遇到的一些术语理解记录。
布式训练中需要将数据在各个xPU之间传输,就需要一套高效的传输操作(通讯原语),下面橙色标签的是分布式训练中通讯原语在AI框架中的的位置。
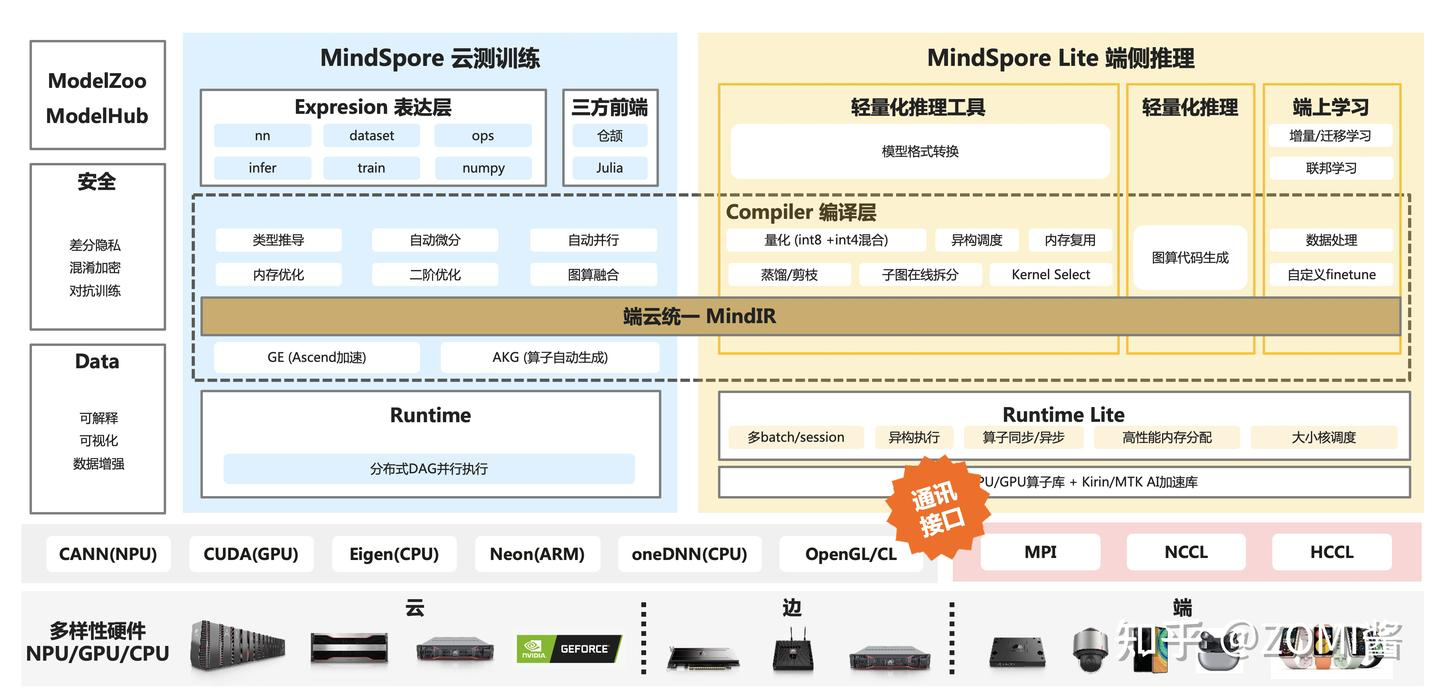
概念解释
通讯元语
通信元语:描述进程间数据交换的基本操作模式,是构建复杂通信行为的“原子操作”。
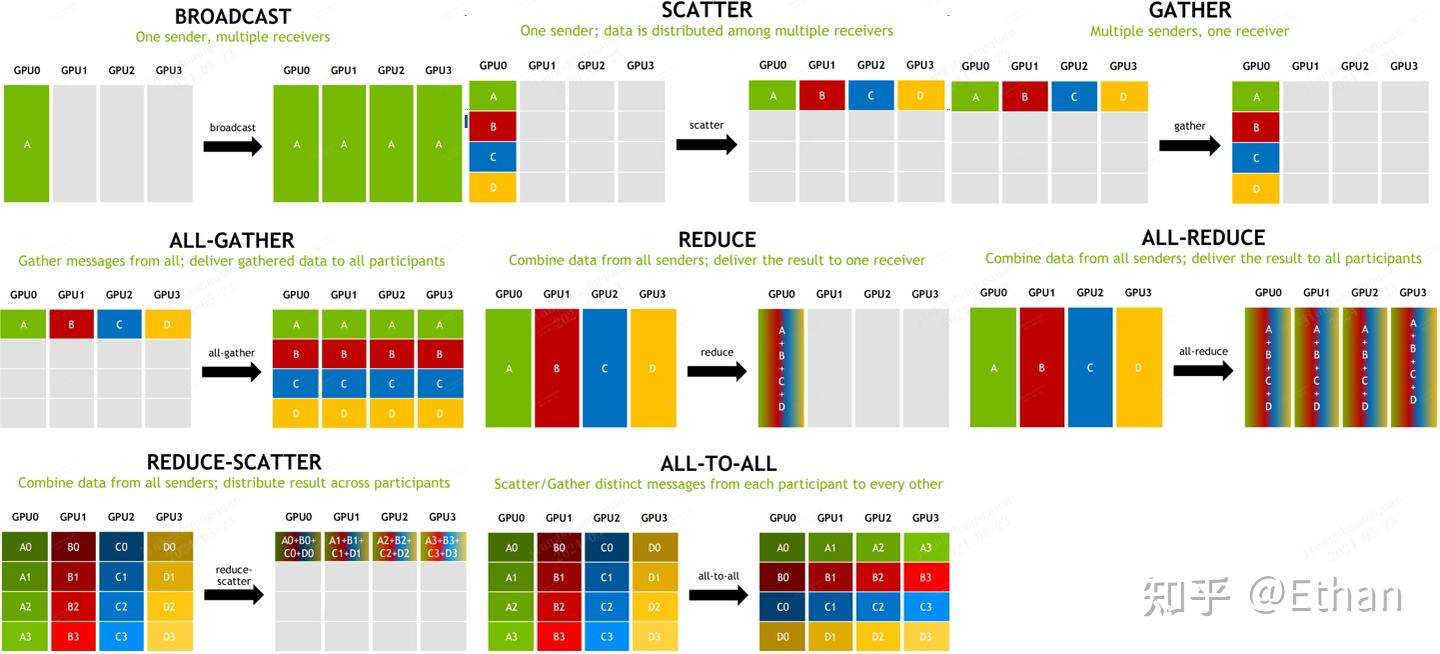
并行任务的通信一般可以分为点对点(Point-to-point communication)和集合通信(Collective communication),P2P通信这种模式只有一个sender和receiver,集合通信则包含多个sender和recevier。常见的通信原语包括:broadcast、gather、all-gather、scatter、reduce、all-reduce、reduce-scatter、all-to-all等。
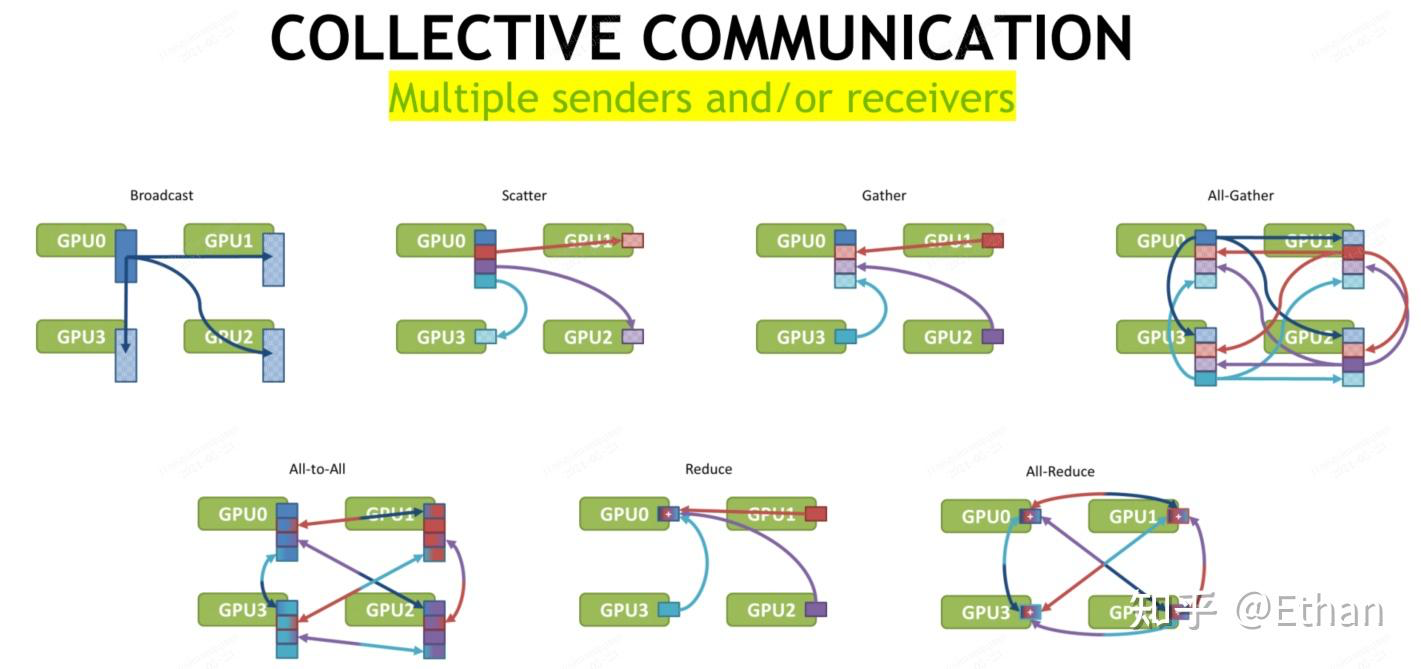
推荐阅读:https://zhuanlan.zhihu.com/p/661538883
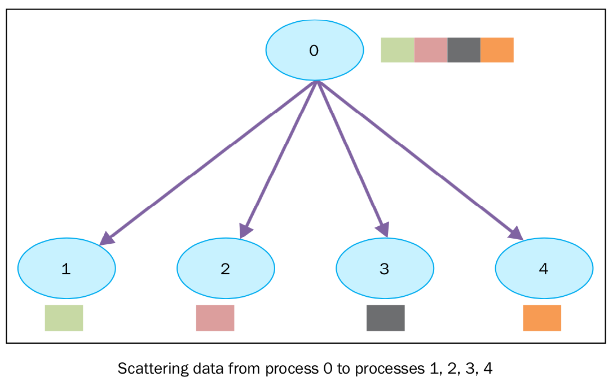
Scatter(发散)--散烟
1 sender, multiple receivers
主节点将数据分块,将不同的数据块分发给不同的节点,完成Scatter后,每个节点数据不一致。
就跟散烟一样,把一包烟拆开,给其他人发烟。
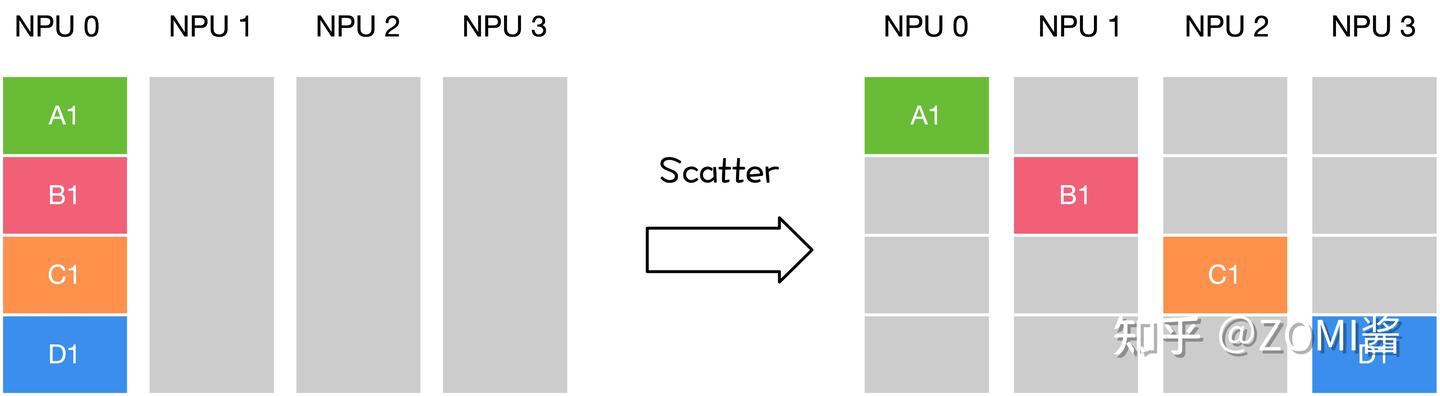
DATA 切片为 DATA-A DATA-B DATA-C DATAD
DATA-A分发给 GPU0
DATA-B分发给 GPU1
DATA-C 分发给 GPU2
DATA-D分发给 GPU3
Scatter是对数据子集的分散,它的反向操作是Gather。
关键点:
- 与Broadcast(全量复制)不同,Scatter分发的是数据切片。
- 示例:模型并行中将参数分片加载到不同GPU。
-
![]()
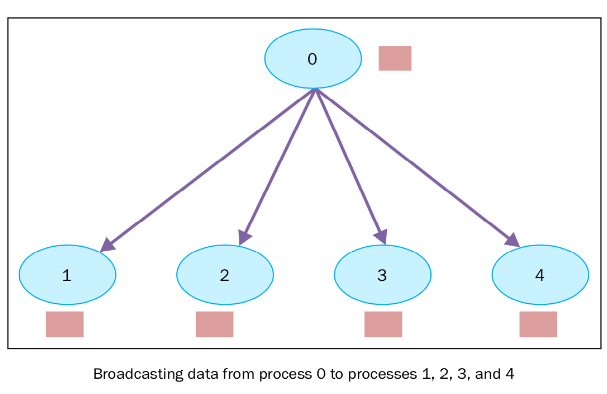
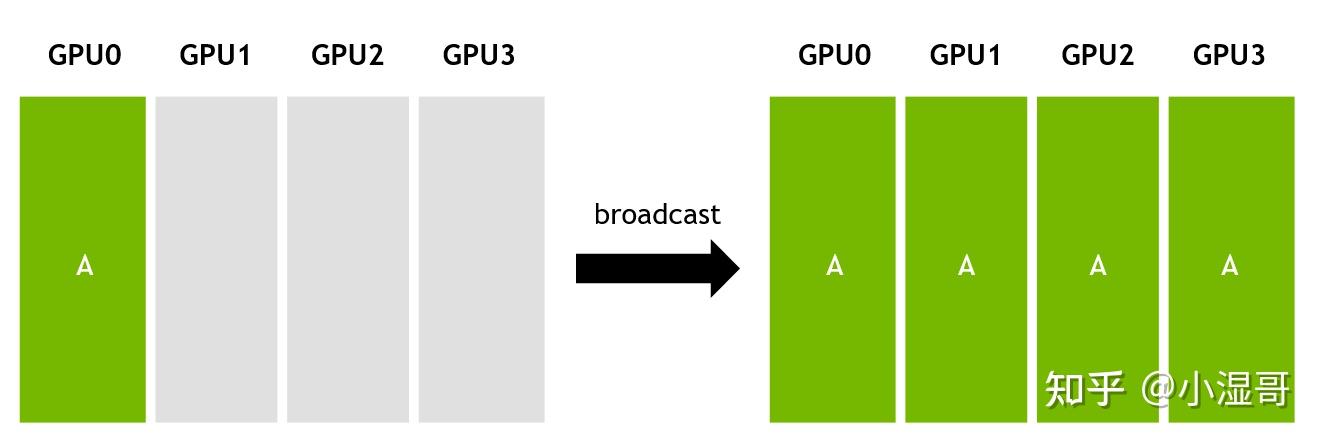
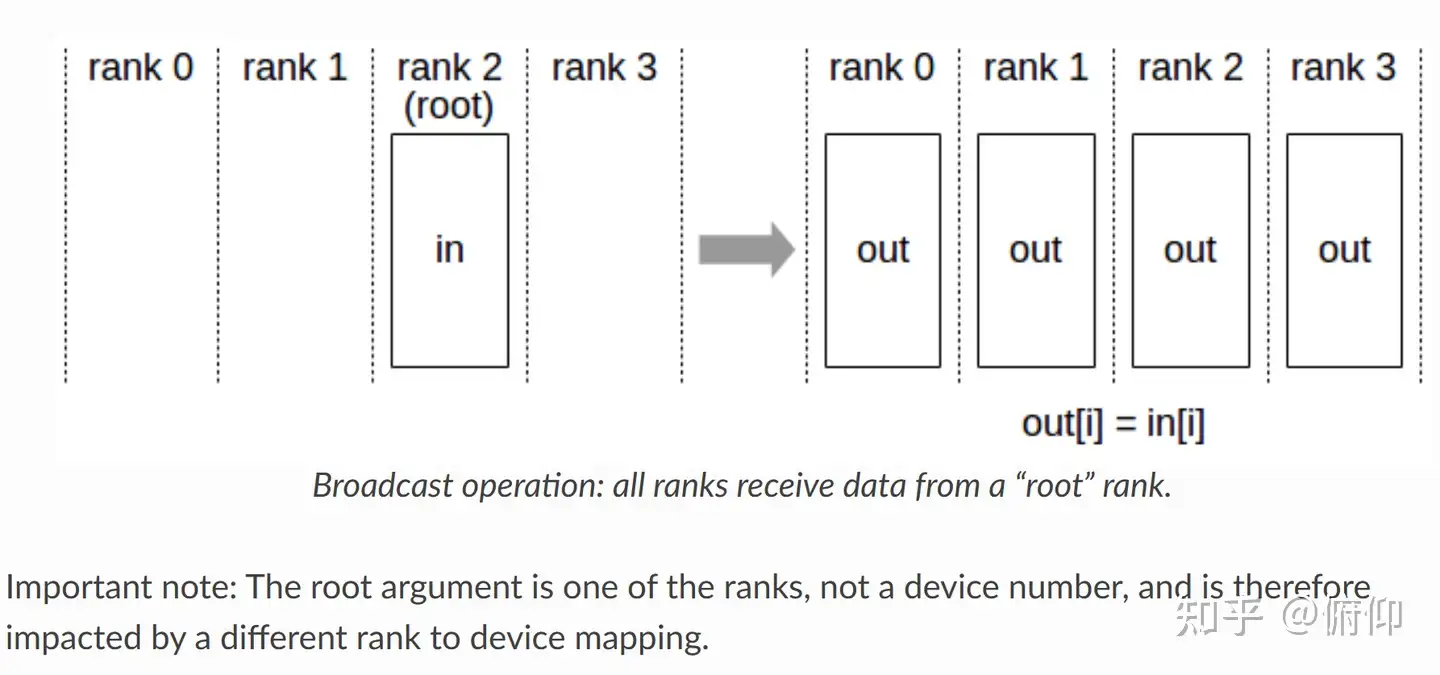
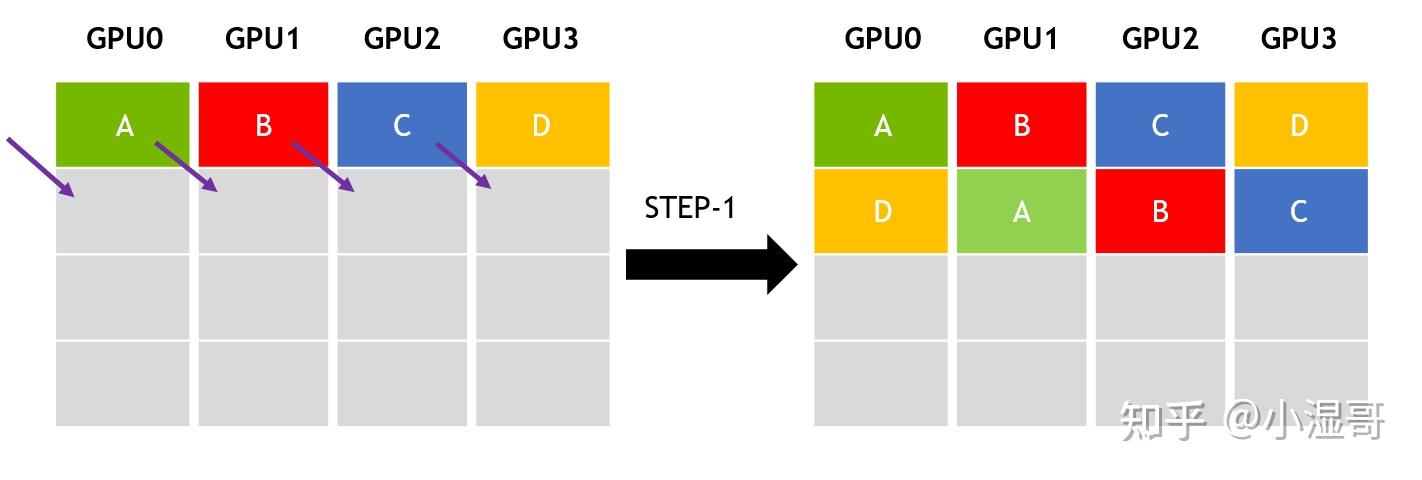
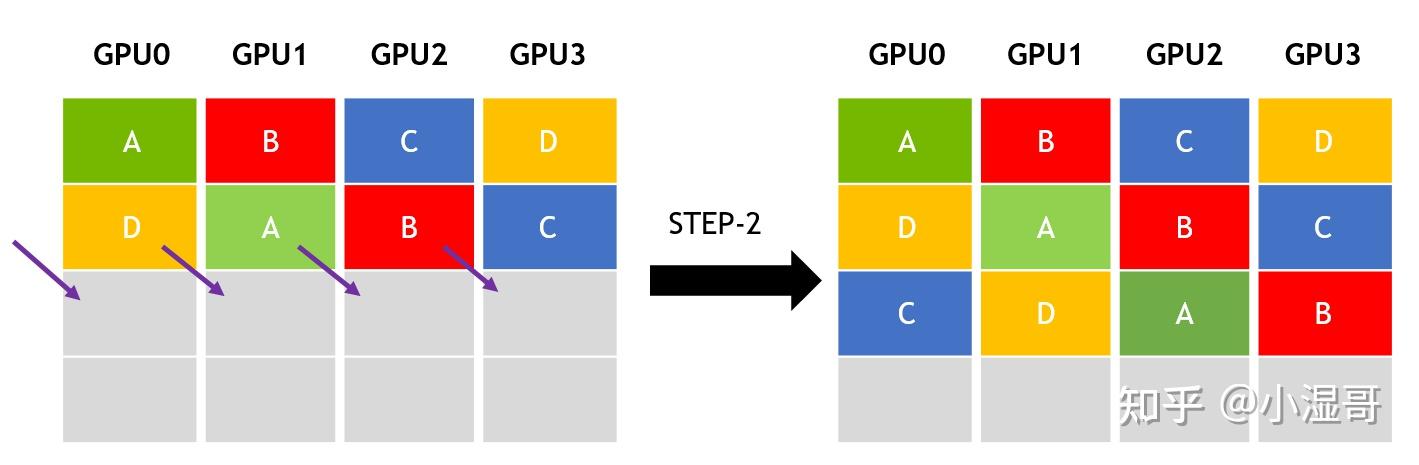
Broadcast(广播)
1 sender, multiple receivers
主节点将数据完整分发给多个节点,完成广播后,每个节点数据一致。
DATA 分发给 GPU0 , GPU1, GPU2, GPU3
Gather(收集)--垒砖头
Multiple senders, 1 receiver
各个节点将各自数据发送给主节点,完成Gather后,主节点拥有所有节点的数据。
就跟垒砖头一样,每个人手上有砖头(砖堆的一部分),把它们垒在一起。
GPU0 有 DATA-A,发送给主节点
GPU1 有 DATA-B,发送给主节点
GPU2 有 DATA-C,发送给主节点
GPU3 有 DATA-D,发送给主节点
主节点拥有DATA-A, DATA-B, DATA-C, DATA-D。
Gather是对数据子集的归并,它的反向操作是Scatter。
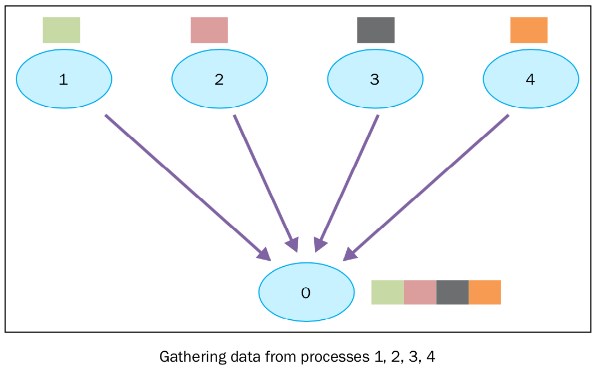
Gather操作会从多个节点里面收集数据到一个节点上面。这个机制对很多平行算法很有用,比如并行的排序和搜索。
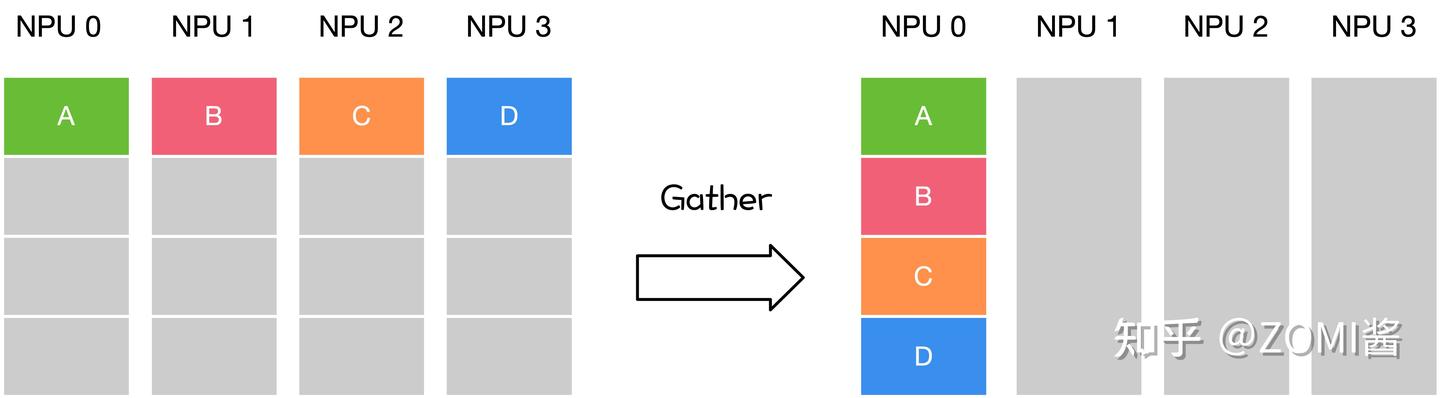
All-Gather(全收集)--gether and to all
Multiple senders, multiple receivers
- 定义:所有节点收集(Gather)数据后,再广播(Bcast)给所有节点(多对多)。All Gather=Gather+Bcast
All-Gather这个名字不太好理解,我认为应该是“gether and to all”,就跟 探子一样,碰头把信息汇总,每个探子就都有了全信息。
一种实现方式:
1.执行Gather,将各个节点所有数据归并到主节点
2.执行Broadcast,将主节点的全量数据分发到各个节点
完成All-Gather后,所有节点具有相同的全量数据
- 关键点:
-
- 通信开销:总数据量 = 节点数 × 单节点数据量。
- 示例:数据并行中同步全局参数。
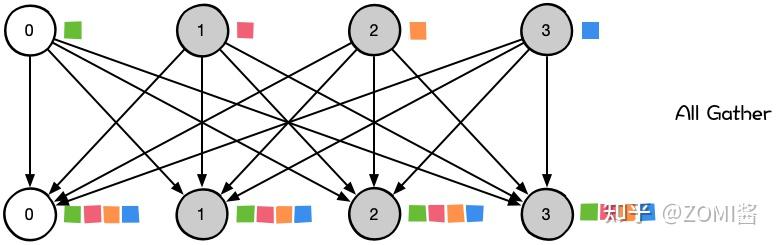
对于分发在所有节点上的一组数据来说,All Gather会收集所有数据到所有节点上。从最基础的角度来看,All Gather相当于一个Gather操作之后跟着一个Bcast操作。下面的示意图显示了All Gather调用之后数据是如何分布的。
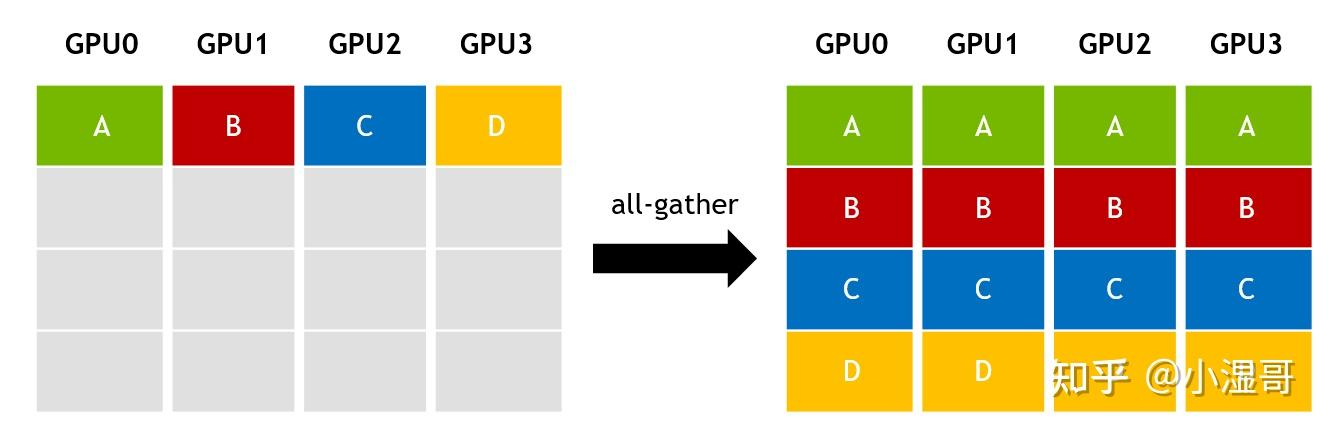
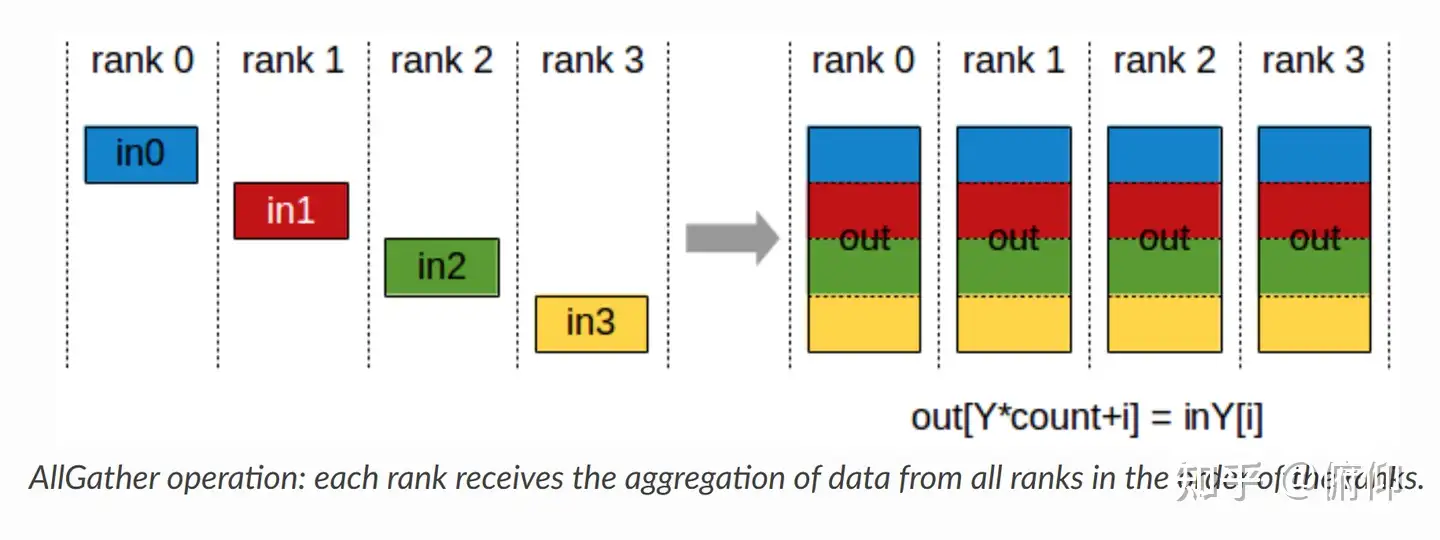
Gather和All-Gather的区别就在于 数据收集回来之后是存在一个节点上还是所有节点上。
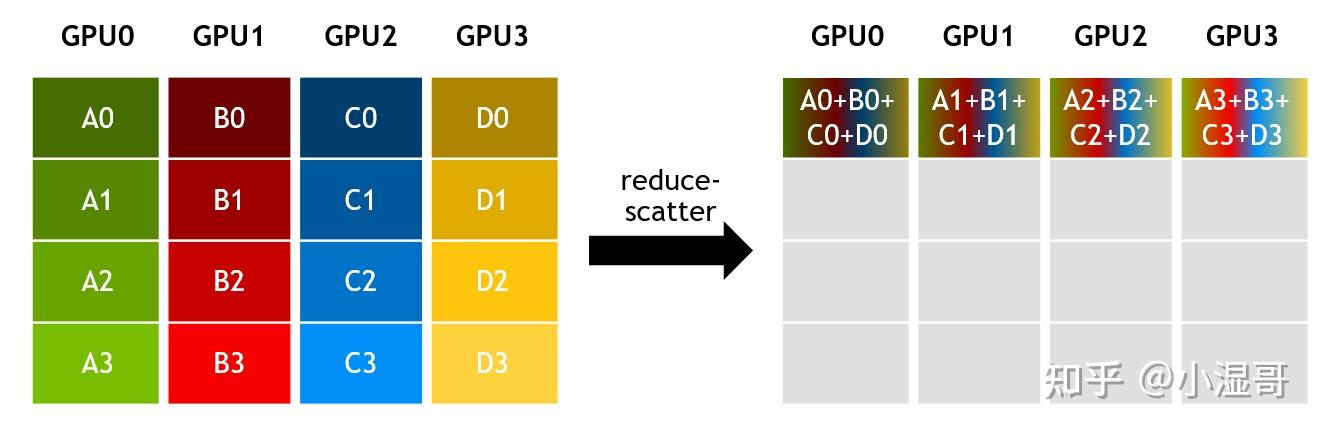
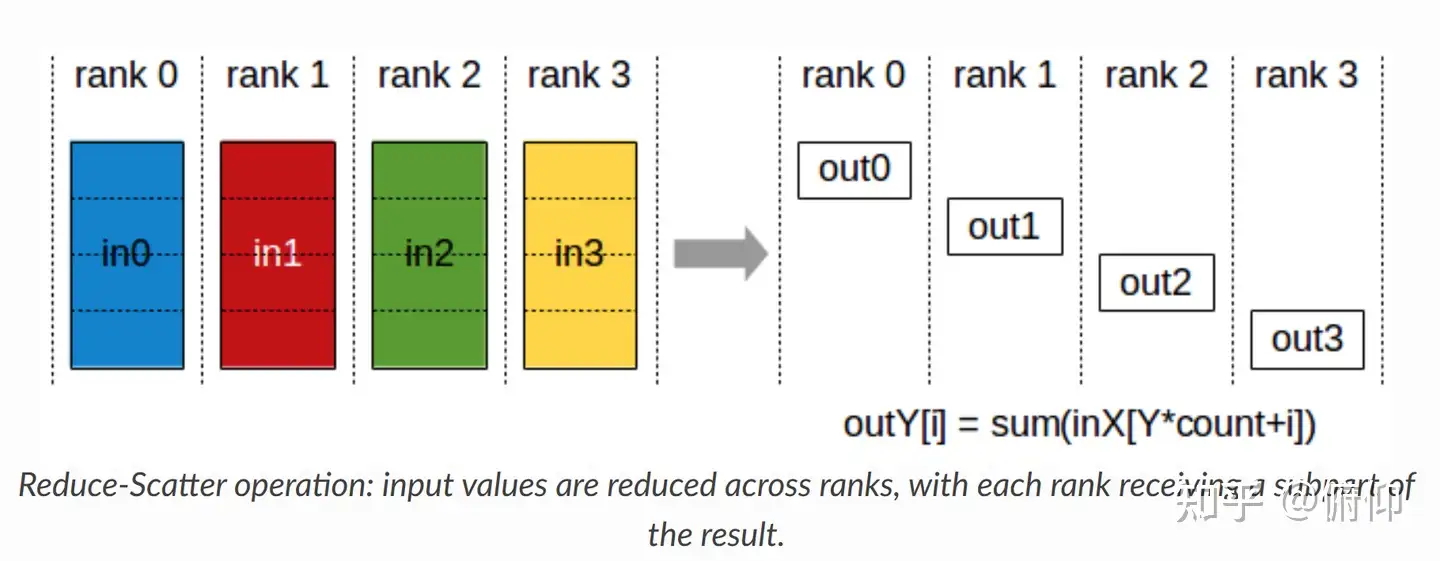
Reduce-Scatter(规约发散)
- 定义:
局部规约(Reduce):所有节点对各自数据分块执行相同的归约操作(如求和、最大值等),生成局部结果。
分散(Scatter):将每个分块的归约结果分发到不同节点,最终每个节点仅保留一个分块的结果。
就跟小朋友N1,N2,N3,N4 各自有红糖,绿糖,紫糖,金糖。N1把自己的糖分4份,把另外三份分别给N2,N3,N4;N2也把自己的糖分4份,把另外三份,给N1,N3,N4....最后大家都有一部分不同颜色的糖。
关键点:
- 数学等价于:对每个数据块独立执行Reduce,再执行Scatter。
- 反向操作是All-Gather(而非用户提到的“等价于节点数量次操作”)。
- 示例:混合并行中局部梯度聚合后分发。
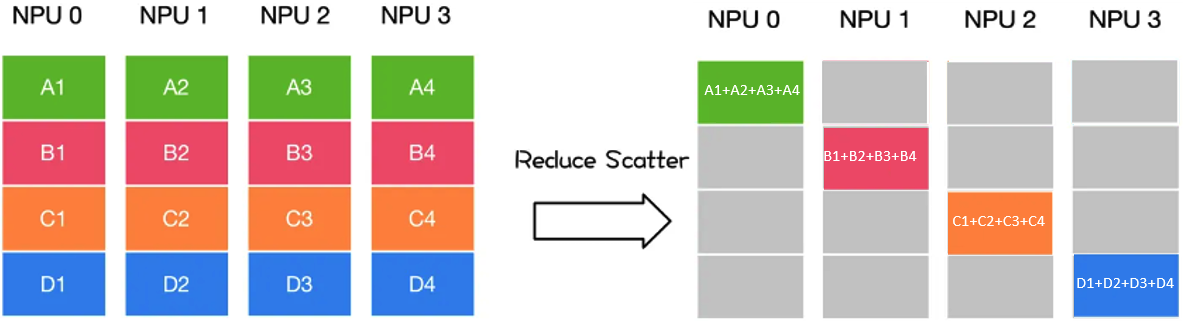
- Reduce Scatter:每个进程的数据被分块,每块独立归约后,将归约结果分散到不同进程。
如下图:GPU1~GPU4的数据分成a~d块,然后对a-b每一块独立归约,结果是:
a1+a2+a3+a4,b1+b2+b3+b4,c1+c2+c3+c4,d1+d2+d3+d4,然后总数据是(a1+a2+a3+a4,b1+b2+b3+b4,c1+c2+c3+c4,d1+d2+d3+d4),再总数据的4部分(切片)分散到CPU1~GPU4:
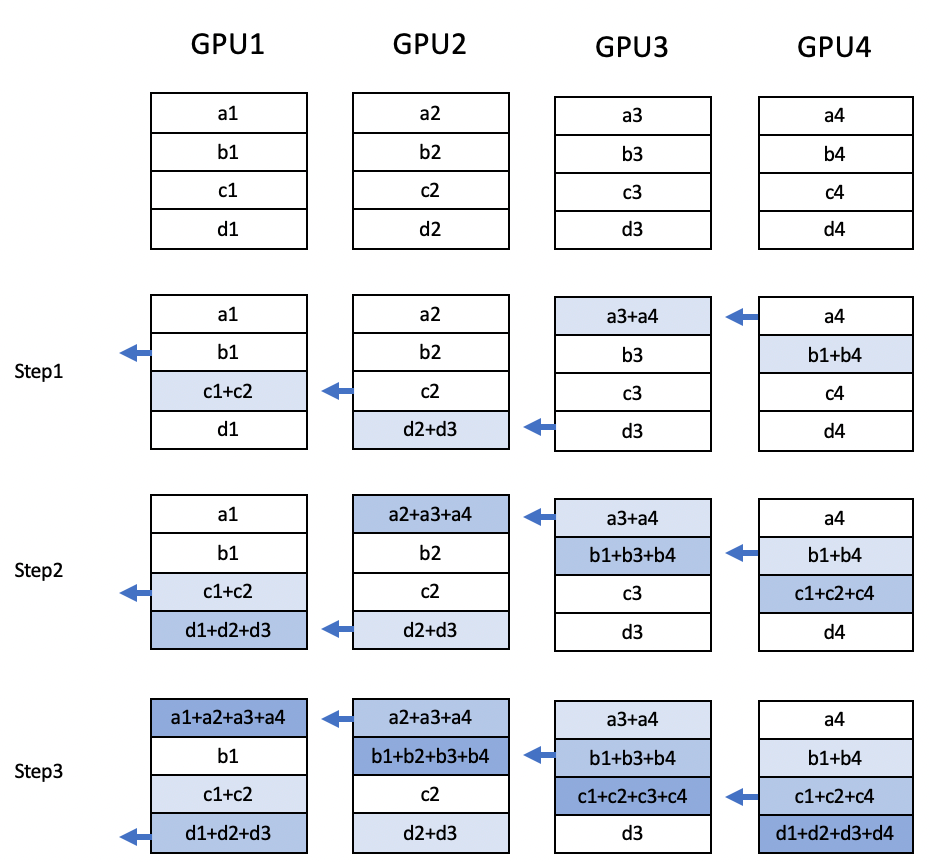
详细过程见:
大模型训练(4):AllReduce详解-https://ddelephant.blog.csdn.net/article/details/145127504
Reduce -- 收作业
Multiple senders, 1 receivers
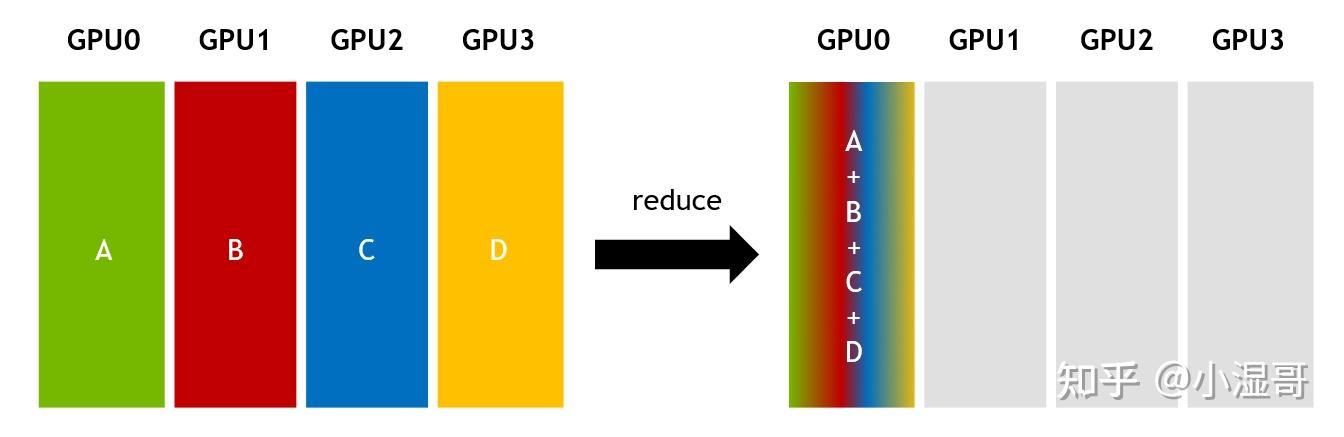
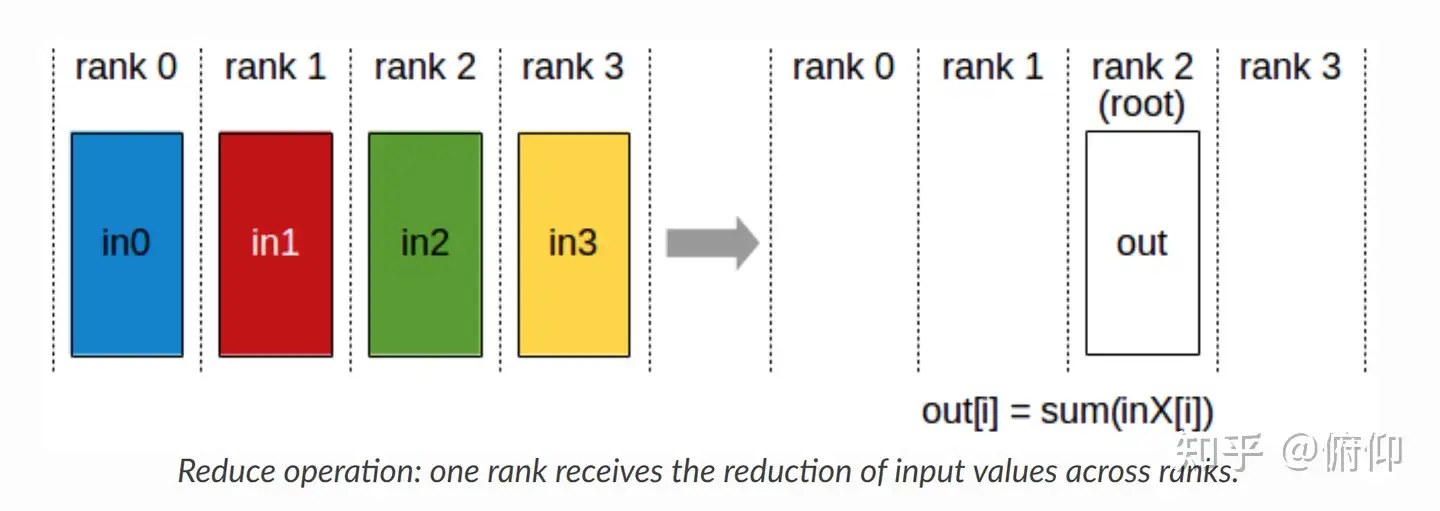
Reduce(归约) 是一种“聚合”操作(本质是一种规约运算,即数据之间进行数学运算(求和、求积、矩阵运算等等)),与“拆分”相反,本质是通过迭代合并,逐步缩小数据规模,最终得到全局结果。
就跟课代表收作业一样,把同学的作业都收到自己手上。
Gather是将所有节点的数据归并至主节点
Reduce是将所有节点的数据进行规约运算,而后将运算结果归于主节点
All-Reduce(全规约)-- reduce and to all
Multiple senders, multiple receivers
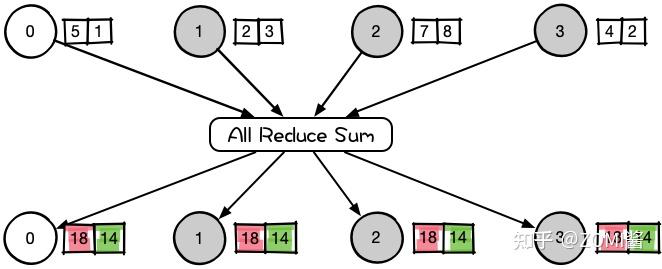
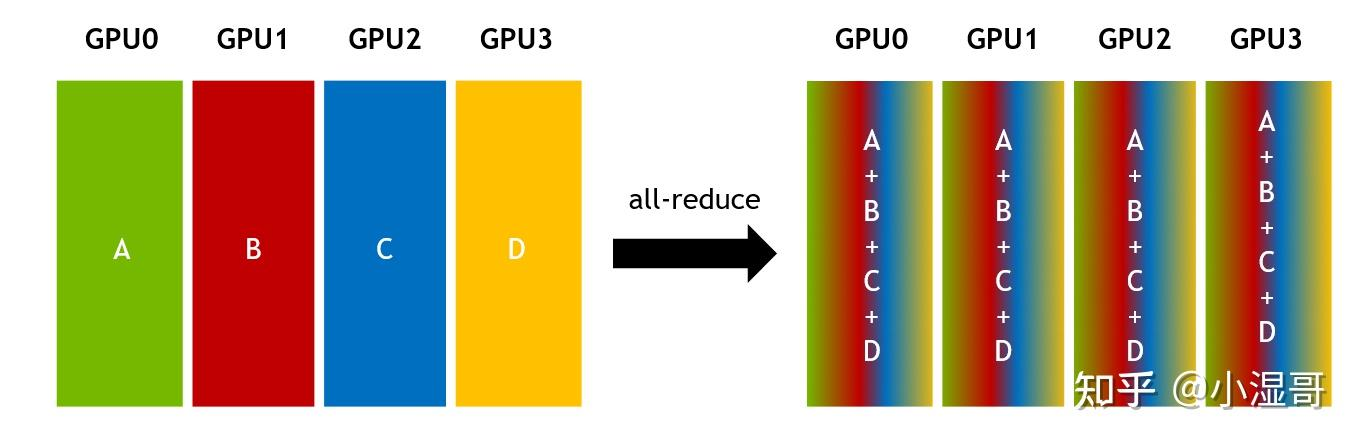
将所有节点的数据进行规约(Reduce),将规约运算后的结果发送给所有的节点(Broadcast)。
一种的All-Reduce实现方式:
1.执行Reduce,将所有数据规约运算至主节点
2.执行Broadcast,将规约运算后的数据分发至所有节点
还有一种Reduce-Scatter + All-Gather的方式。
- 关键点:
- 高频实现方式:Reduce-Scatter + All-Gather(通信效率高于单Reduce+Broadcast)。
- 示例:数据并行中的梯度同步。
All-reduce与reduce的区别就在于后者最后的结果是只保存在一个进程中,All-reduce需要每个进程都有同样的结果。所以All-reduce一般包含scatter操作,所以有时候也会看到reduce-scatter这种说法,其实reduce-scatter可以看成是all reduce的一种实现方式
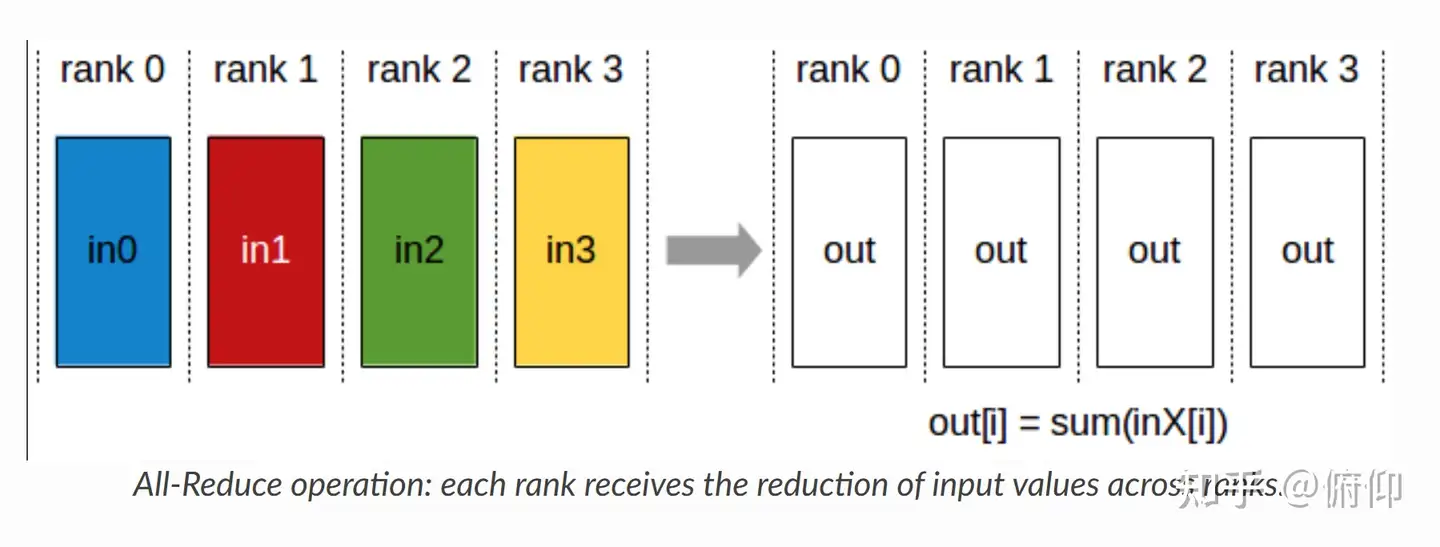
Allreduce与Ring-Allreduce的区别?
在大模型训练中,有一种并行计算操作,将多个进程的数据聚合后,将结果返回给所有进程。这就是Allreduce
实现Allreduce 有多种算法(策略),其效率高度依赖于具体的实现方式和网络拓扑结构,比较常见的算法有Ring-Allreduce 和 tree-Allreduce、分组交换(Group-based)、二维网格(2D-Torus)等。

Hierarchical All-Reduce:
- 对于多节点环境,NCCL支持层次化的all-reduce算法,该算法利用节点内部的高带宽连接和节点之间的较低带宽连接来有效地执行全局all-reduce操作。
通过使用这些策略,NCCL帮助研究人员和工程师更有效地利用多GPU系统进行深度学习模型的训练,缩短训练时间并提高资源利用率。值得注意的是,实际应用中可能会根据具体的应用场景和硬件配置选择合适的分布式训练策略。
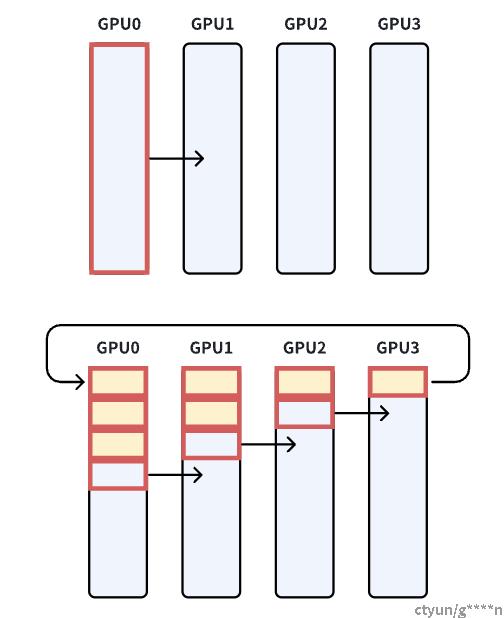
Ring-base collective
Ring-base collective是将所有的通信节点通过首位相连形成一个单向环,数据在环上依次传输。
在broadcast场景,假设有4个GPU,GPU0为sender将信息发送给剩下的GPU,有两种方式:
- 采用一次传输全部。
- 分成多次传输两种方式进行发送。
前者的通信时间会随着通信节点数线性增长,在进行两个GPU节点之间的通信时,其余节点的带宽是浪费的,效率很低。后者会将需要传输的数据分成多份,每次只传输一部分数据,因此每个GPU节点都会同时参与数据的传输,且通信时间不会随着节点数的增加,只和数据总量和带宽有关,注意:数据分割数需要远大于GPU节点数。
-
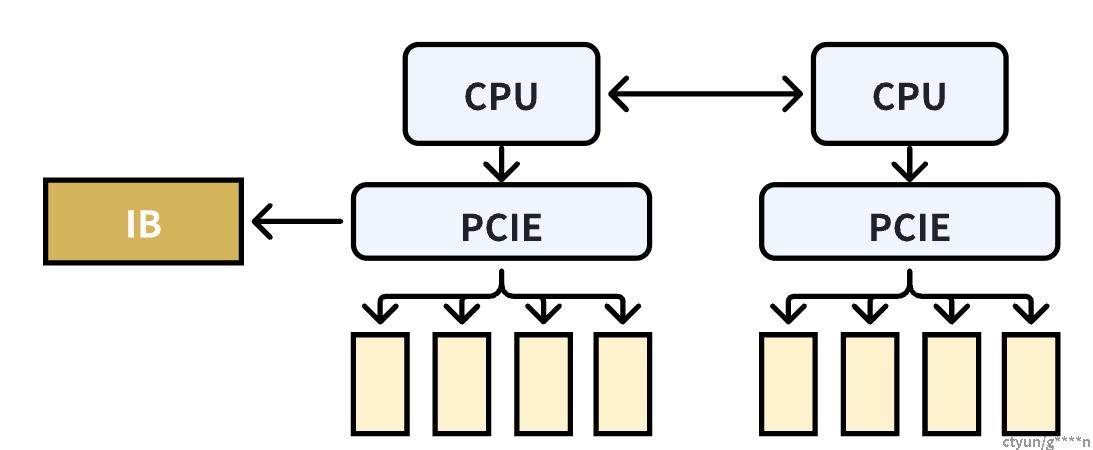
单机4卡通过同一个PCIe switch挂载在一颗CPU上,
-
单机8卡通过两个CPU下不同的PCIe switch挂载
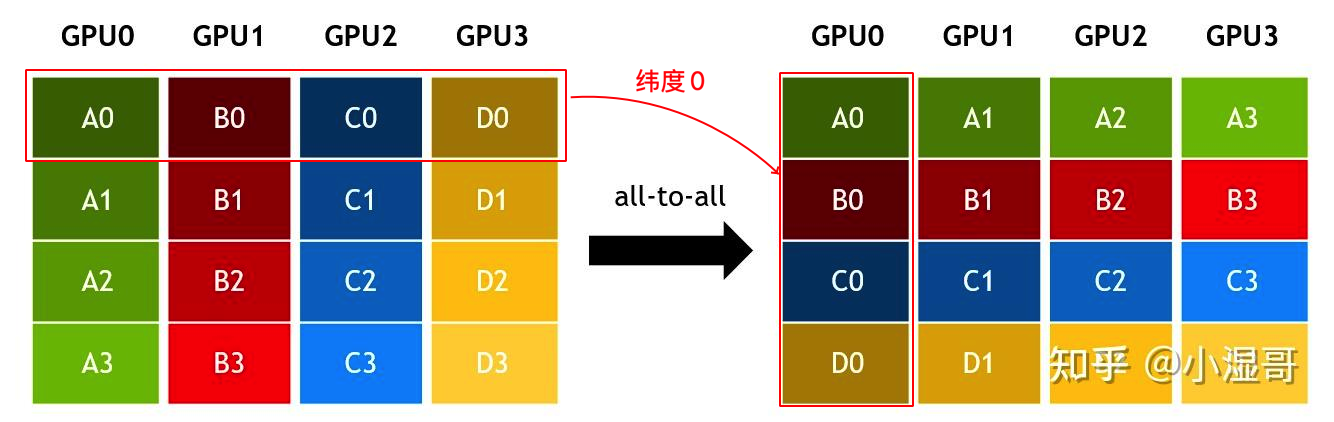
All to All (Gather-Scatter)
Multiple senders, multiple receivers
每个节点将数据且分为若干维度,每一个节点对一个维度的所有数据进行Gather。
一种实现的步骤如下:
- 每个节点将本地数据切片分块,将不同维度的数据块分发给不同的节点(Scatter)
- 每个节点对新数据只做保存,不做规约,只是Gather
CPU0 有 A0,B0,C0,D0
CPU1 有 A1,B1,C1,D1
...
假设有n个rank(集群通信进程),对于单个rank而言,它需要把自己数据分成n等份按照顺序发送个各个rank,同时接收其它rank发过来的数据。如下图所示,是rank数量为4的alltoall操作示意,为了方便理解数据长度设置为1。图中的操作过程有点类似于矩阵的一个转置操作。
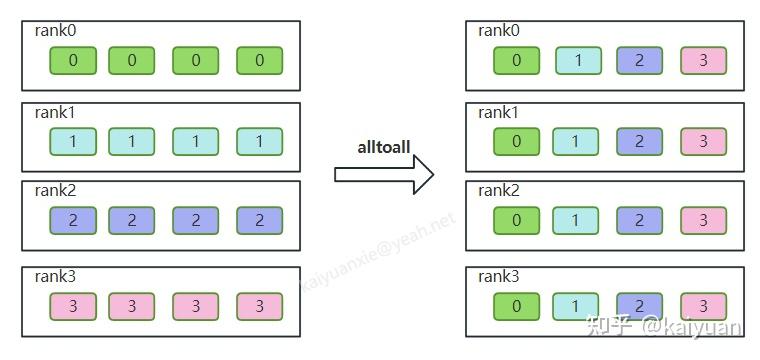
摘自:https://zhuanlan.zhihu.com/p/718765726
NCCL中的通信原语实现
NCCL中包含三种原语操作:Copy、Reduce和ReduceAndCopy。
单机多卡之间通过PCIe、NVlink、GPU Direct P2P进行通信;
多机多卡之间通过socket、InfiniBand with GPU Direct RDMA进行通信。
下图右侧部分为单机多卡间的通信环,左侧通过IB(InfiniBand无限带宽)实现多机之间的数据传输
其他
什么是梯度
梯度可以被理解为一个多变量函数的导数。
说明:
损失函数衡量了模型预测结果与真实标签之间的差异,我们希望通过调整神经网络的权重参数,使得这个差异尽可能小。
在训练神经网络时,我们通常希望最小化损失函数。梯度下降及其变种(如随机梯度下降 SGD、Adam 等)是实现这一目标的常用优化算法。这些算法的核心思想都是利用损失函数相对于权重的梯度来迭代地更新权重。梯度提供了损失函数在当前权重值下的变化方向和变化率信息,我们沿着负梯度方向更新权重,就可以逐步减小损失函数的值。
神经网络训练过程
正向传播:首先,输入数据通过网络向前传播,计算出预测结果。
计算损失:然后,比较预测结果与真实标签,计算损失函数的值。
反向传播:接下来,通过反向传播算法计算损失函数关于各层权重的梯度。
参数更新:最后,根据计算得到的梯度,按照一定的学习率更新网络的权重。

AI框架中的通信实现(MPI和NCCL)
分布式集群的网络硬件多种多样,可以是Ethernet、InfiniBand 等,深度学习框架通常不直接操作硬件,而是使用通信库。之所以采用通信库屏,是因为其蔽了底层硬件细节,提供了统一封装的通信接口。其中MPI和NCCL是最常用的通讯库,MPI专注于CPU的并行通讯,NCCL则专注于GPU的通讯。
MPI (Message Passing Interface )
MPI 信息传递接口,是一个用于编写并行计算程序的编程接口。它提供了丰富全面的通信功能。
MPI 常用于在计算集群、超算上编写程序,比如很多传统科学计算的并行程序。MPI 接口的兼容性好,通信功能丰富,在深度学习框架中主要用于 CPU 数据的通信。
MPI是一个开放接口,有多种实现的库,一种广泛使用的开源实现是 Open MPI。一些硬件厂商也提供针对硬件优化的实现。
NCCL (NVIDIA Collective Communication Library )
NCCL 英伟达集合通信库,是一个专用于多个 GPU 乃至多个节点间通信的实现。它专为英伟达的计算卡和网络优化,能带来更低的延迟和更高的带宽。
NCCL 也提供了较丰富的通信功能,接口形式上与 MPI 相似,可满足大多数深度学习任务的通信需求。它在深度学习框架中专用于 GPU 数据的通信。因为NCCL则是NVIDIA基于自身硬件定制的,能做到更有针对性且更方便优化,故在英伟达硬件上,NCCL的效果往往比其它的通信库更好。
MPI和NCCL的关系
openMPI的通讯算法和通讯操作原语最晚在2009年就都已经成熟并开源了,而Nvidia在2015年下半年首次公开发布NCCL。
既然openMPI已经实现了这么多All Reduce算法,为什么英伟达还要开发NCCL?是不是从此只要NCCL,不再需要MPI了呢?
NO
从openMPI的源码里能看到,其完全没有考虑过深度学习的场景,基本没有考虑过GPU系统架构。很明显的一点,MPI中各个工作节点基本视为等同,并没有考虑节点间latency和带宽的不同,所以并不能充分发挥异构场景下的硬件性能。
Nvidia的策略还是比较聪明,不和MPI竞争,只结合硬件做MPI没做好的通信性能优化。在多机多卡分布式训练中,MPI还是广泛用来做节点管理,NCCL只做GPU的实际规约通信。NCCL可以轻松与MPI结合使用,将MPI用于CPU到CPU的通信,将NCCL用于GPU到GPU的通信。
而NCCL的优势就在于完全贴合英伟达自己的硬件,能充分发挥性能。但是基本的算法原理其实相比openMPI里实现的算法是没有太大变化。
NCCL1.x只能在单机内部进行通信,NCCL2.0开始支持多节点(2017年Q2)。所以在NCCL2之前大家还会依赖MPI来进行集合通信。
术语关联与优化
- Reduce-Scatter与显存优化:
-
- 在ZeRO等显存优化技术中,通过Reduce-Scatter平衡显存占用与通信开销。
- All-to-All vs. All-Gather:
-
- All-to-All:全交换操作(每个节点发送不同数据给不同节点)。
- All-Gather:所有节点获得相同的全局数据。
- 硬件拓扑影响:
-
- NCCL利用NVLink/PCIe拓扑优化通信路径(如环形算法降低All-Reduce延迟)。
(https://www.zhihu.com/question/608944113)
- Collective Operations:NCCL 支持各种集体通信操作,如广播(Broadcast)、规约(Reduction)、聚合(Aggregation)、AllReduce、AllGather 等。这些操作可以在多个 GPU 或节点之间进行数据同步和合并。
- Processes and Groups:NCCL 中的进程(Processes)表示参与通信的计算节点。进程可以组织成组(Groups),以便在组内进行集体通信。
- Communicators:Communicators 是 NCCL 中用于定义进程之间通信关系的对象。它指定了参与通信的进程组和通信模式(如点对点、广播等)。
- Devices and Streams:NCCL 与 GPU 设备密切相关,它可以在多个 GPU 设备之间进行通信。同时,NCCL 还支持与 CUDA 流(Streams)的集成,以实现异步通信和并行计算。
- Synchronization:在分布式计算中,同步是至关重要的。NCCL 提供了各种同步原语,如 barrier 同步,以确保进程在执行集体通信操作时达到一致的状态。
- Performance Optimization:NCCL 注重性能优化,它提供了一些技术来提高通信效率,如集体通信的合并、数据传输的批量处理、通信与计算的重叠等。
- Fault Tolerance:NCCL 还考虑了容错性,支持在部分节点故障或网络不稳定的情况下进行可靠的通信。
作者:俯仰
链接:https://www.zhihu.com/question/608944113/answer/3470292977
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
CUDA Steam语义
NCCL调用是和固定的stream联系在一起的,特定的stream会作为集体通信函数的最后一个参数传入。当操作成功进入给定steam的队列中后,NCCL调用才会返回,否则会报错。集体操作接下来会在CUDA设备上异步执行。对应操作的状态可以使用标准的CUDA语义进行查询,比如调用cudaStreamSynchrionize或者使用CUDA事件(event)。
CUDA Semantics(CUDA 语义)通常指的是在CUDA编程模型中,数据和操作如何在GPU上执行的规则和行为。CUDA是由NVIDIA开发的一种并行计算平台和API模型,它允许开发者使用GPU进行通用计算(GPGPU)。
NCCL也支持在同一组调用中使用多个stream,这样做会在NCCL kernel开始执行之前在所有的stream之间产生stream的依赖,会阻塞掉所有的steam,直到NCCL kernel执行完成。
就表现而言,好像这个NCCL操作作用于所有的stream上,但其实只是一个单个的操作,它会在stream之间产生一个全局的同步点。
组调用(Group Calls)
组函数(Group functions)可以将多个调用合并成一个。有三种用法,它们也可以组合起来 :
- 使用一个线程管理多个GPU
- 聚合通信算子,从而提升性能
- 合并多个send/receive类型的点对点操作。
调试与性能分析
- 工具支持:
-
- 使用
NCCL_DEBUG=INFO输出通信事件,定位死锁或性能瓶颈。
- 使用
- 通信开销公式:
-
- All-Reduce时间 ≈ (数据量/带宽) × (节点数-1)/节点数(环形算法)。
- 混合并行场景:
-
- 数据并行:依赖All-Reduce同步梯度。
- 模型并行:依赖Reduce-Scatter分发激活值。
常见误区
- 误区1:Reduce-Scatter等价于执行节点数量次操作。
修正:数学上等价,但实际通过单次高效通信实现。 - 误区2:Scatter与Broadcast功能相同。
修正:Scatter分发切片,Broadcast复制全量数据。
总结
| 术语 | 通信模式 | 典型场景 | 反向操作 |
| Reduce | 多对1 | 梯度归约到主节点 | - |
| Scatter | 1对多 | 模型并行参数分片 | Gather |
| Reduce-Scatter | 多对多 | 混合并行局部梯度聚合 | All-Gather |
| Gather | 多对1 | 参数服务器收集梯度 | Scatter |
| All-Gather | 多对多 | 数据并行全局参数同步 | Reduce-Scatter |
| All-Reduce | 多对多 | 数据并行梯度同步(高效实现) | - |
掌握这些术语及其关联,可更高效地优化大模型训练的通信策略。建议结合NCCL文档及PyTorch/TensorFlow的通信API(如torch.distributed.all_reduce)深入理解。
参考:
Broadcast,Scatter,Gather,Reduce,All-reduce分别是什么? - marsggbo - 博客园
https://zhuanlan.zhihu.com/p/718765726
https://zhuanlan.zhihu.com/p/465967735
https://zhuanlan.zhihu.com/p/661538883
https://www.zhihu.com/question/608944113/answer/3470292977
----------------------未消化备份--------------------------------------------------
环形拓扑
NCCL通常使用一个或多个环形拓扑,来实现上述通信原语,能够得到最大化的带宽利用率。在nccl-test工具中,默认拓扑就是Ring
环形拓扑有强一致性,环中某一个瓶颈就是整条环的最大带宽。
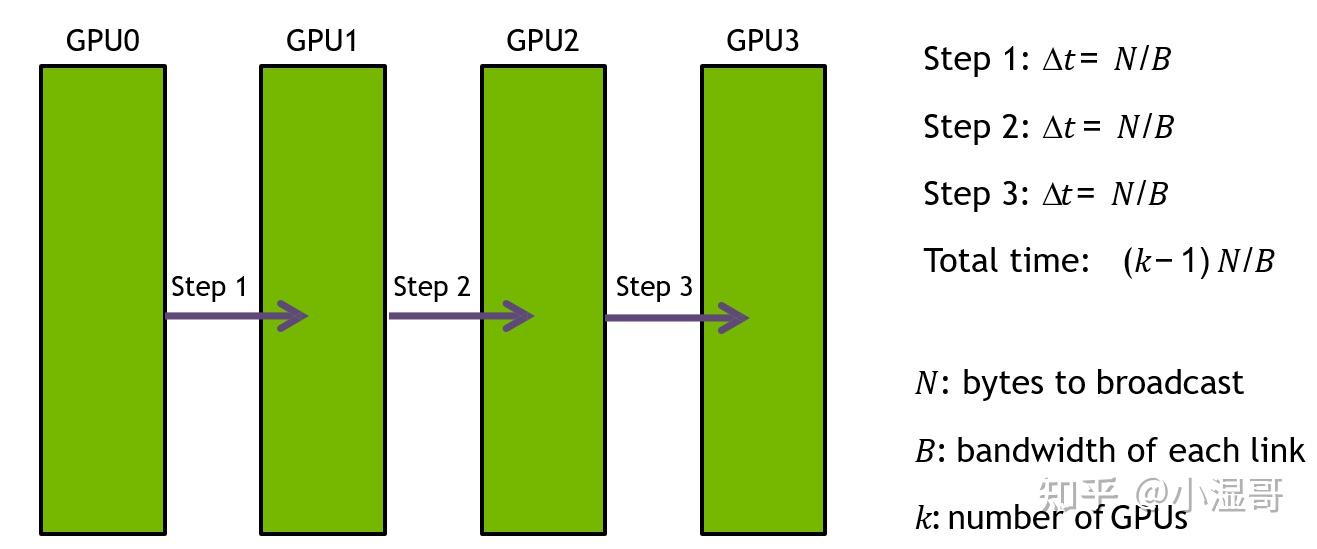
Broadcast
是 GPU数量, 单GPU的数据量, 链路带宽
一次发送全部数据,广播耗时
100Gb数据,100Gbps带宽,4个节点,总计(4 - 1) *100Gb/100Gbps = 3s
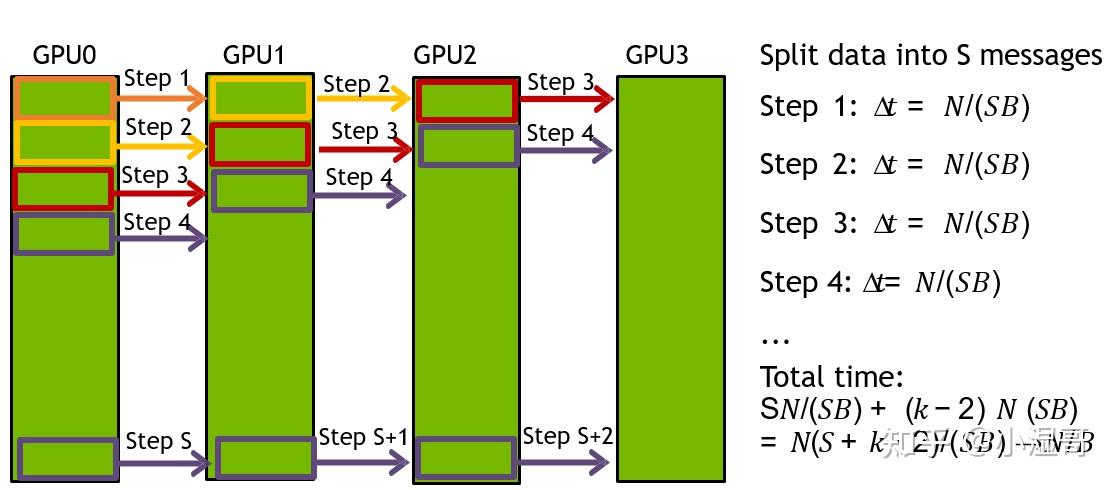
如果分成小块数据传输,效率会更高
S个数据块,完成广播需要 �+(�−2) 个steps
每个Step,一条链路的数据量是 �/� , 所以耗时 �=(�/�)/�=�/(��)
总共Step数量是 �+(�−2) , 总耗时 �=�(�+�−2)/(��) , 当S足够大时可 近似 �=�/�
100Gb数据,100Gbps带宽,4个节点,假设S为100,总计 ,1.02 s 完成广播
nccl-test代码:
其中 count是块数,typesize每块大小,count*typesize 就是 � , sec 就是 �
| ```c // broadcast.cu void BroadcastGetBw(size_t count, int typesize, double sec, double* algBw, double* busBw, int nranks) { double baseBw = (double)(count * typesize) / 1.0E9 / sec; *algBw = baseBw; double factor = 1; *busBw = baseBw * factor; } ``` |
|---|
All-reduce
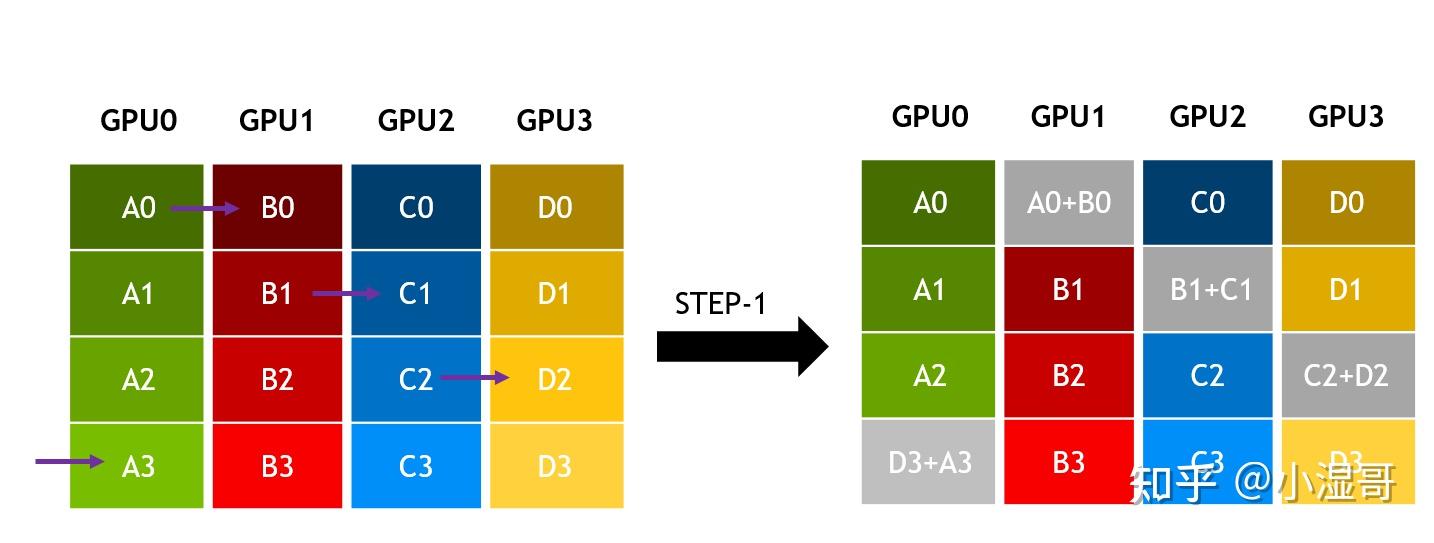
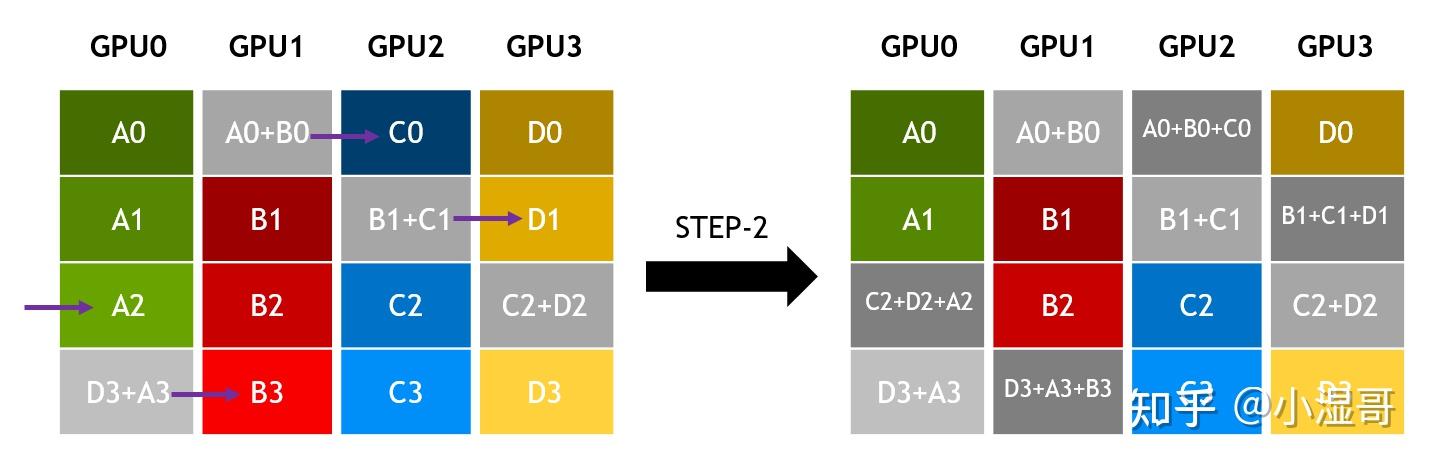
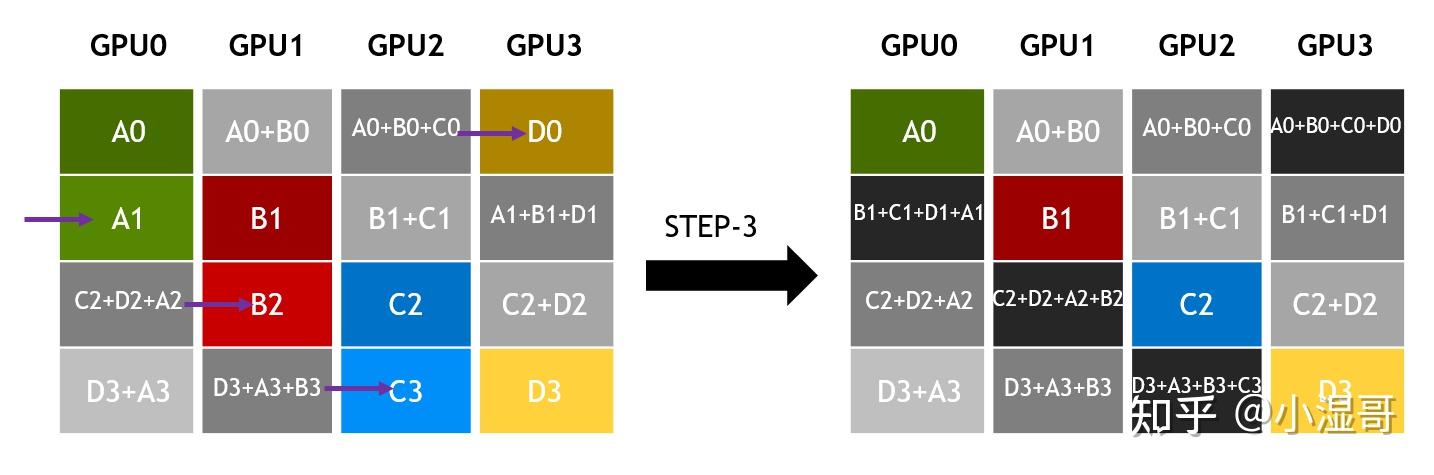
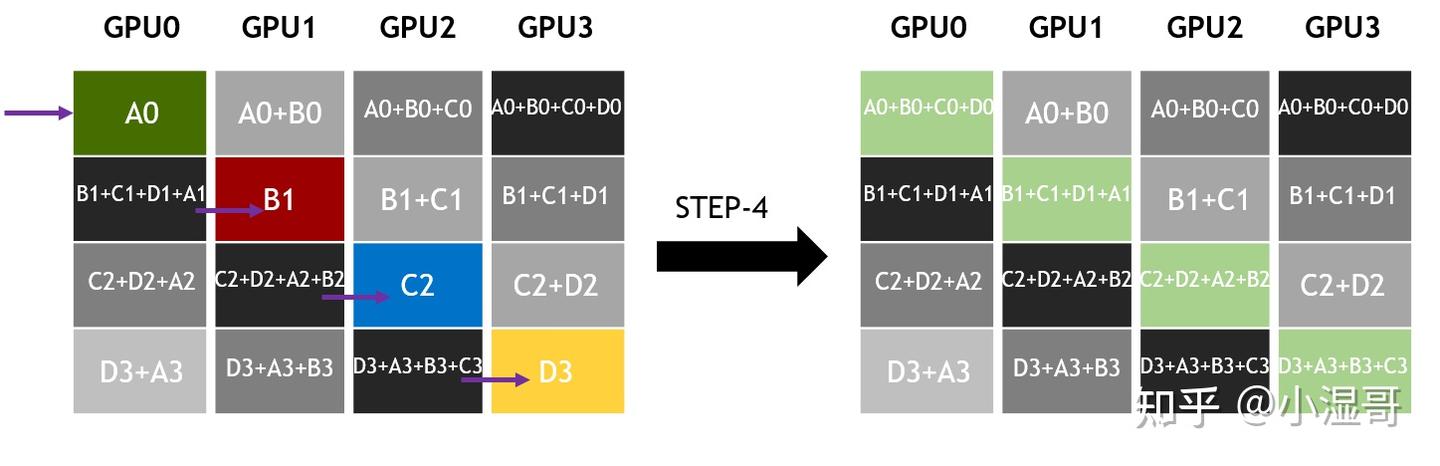
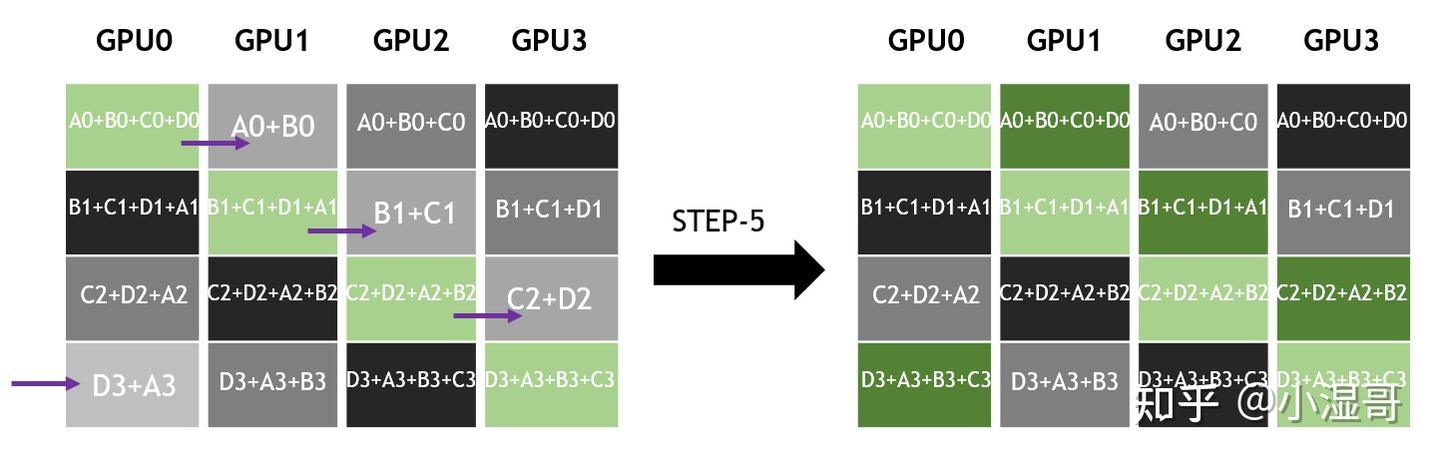
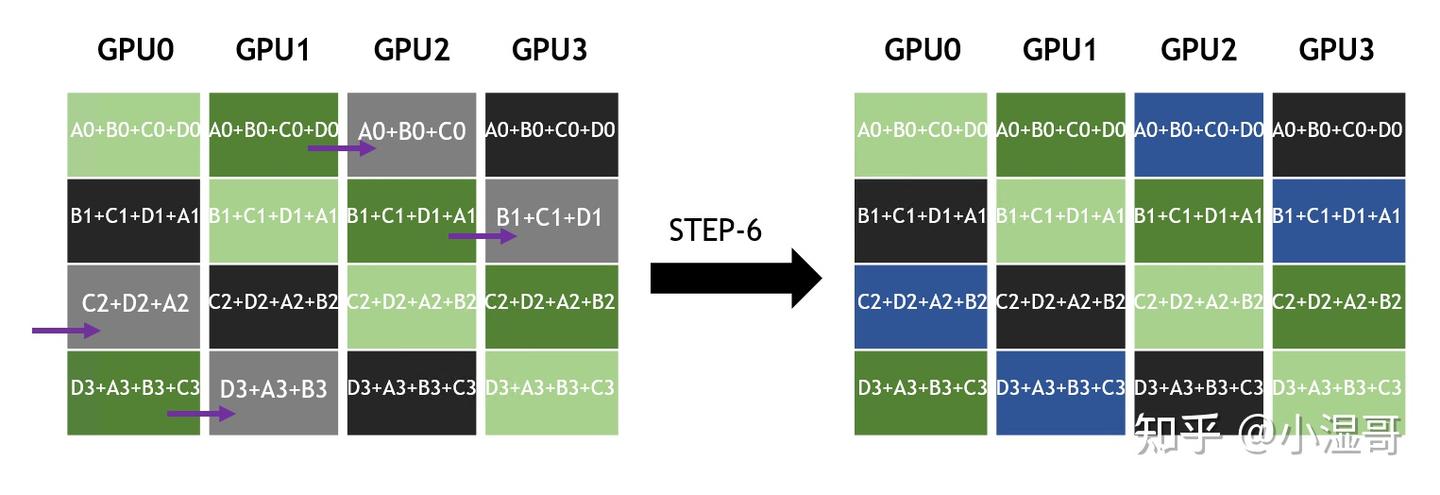
� 是 GPU数量, � 单GPU所有维度的数据量, � 链路带宽
数据分成 S 个维度, 同GPU数量即 S = k
一个step,发送的数据量是 �/� ,所用时间为 �=(�/�)/�=�/(��)
(�−1) steps以后,每个GPU都有一个维度的规约结果
再 (�−1) steps,完成各个维度完整数据的广播。
总计 2(�−1) steps
总时间 �=2(�−1)∗�/(��)=2�(�−1)/��
数据量 �
�����=�/(2�(�−1)/��)
�����=�∗�/(2(�−1))
�=�����∗2(�−1)/�
nccl-tests源码:
nranks代表GPU数量
| //all_reduce.cu void AllReduceGetBw(size_t count, int typesize, double sec, double* algBw, double* busBw, int nranks) { double baseBw = (double)(count * typesize) / 1.0E9 / sec; *algBw = baseBw; double factor = ((double)(2*(nranks - 1)))/((double)nranks); *busBw = baseBw * factor; } |
|---|
All-Gather
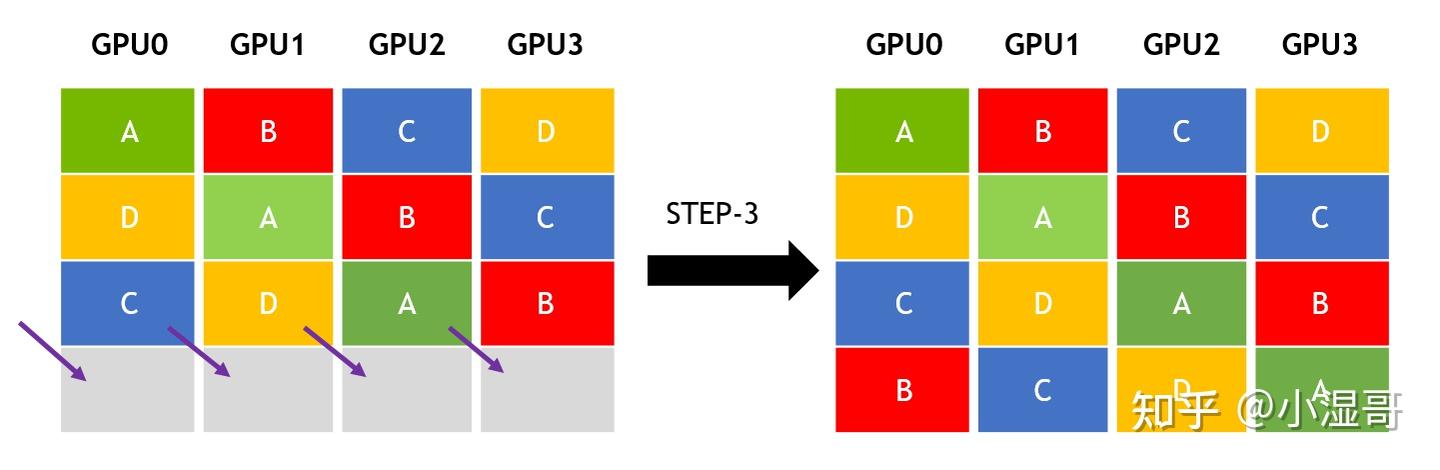
� 是 GPU数量, � 单GPU单维度的数据量, � 链路带宽busbw
�=�/�
�=�∗�����=�∗(�−1)=�(�−1)/�
�=�(�−1)/�
总共单GPU的数据量是 �∗�
�����=(�∗�)/�=�∗�/(�−1)
�=�����∗(�−1)/�
nccl-test源码:
| // all_gather.cu void AllGatherGetBw(size_t count, int typesize, double sec, double* algBw, double* busBw, int nranks) { double baseBw = (double)(count * typesize * nranks) / 1.0E9 / sec; *algBw = baseBw; double factor = ((double)(nranks - 1))/((double)nranks); *busBw = baseBw * factor; } |
|---|
All-to-All
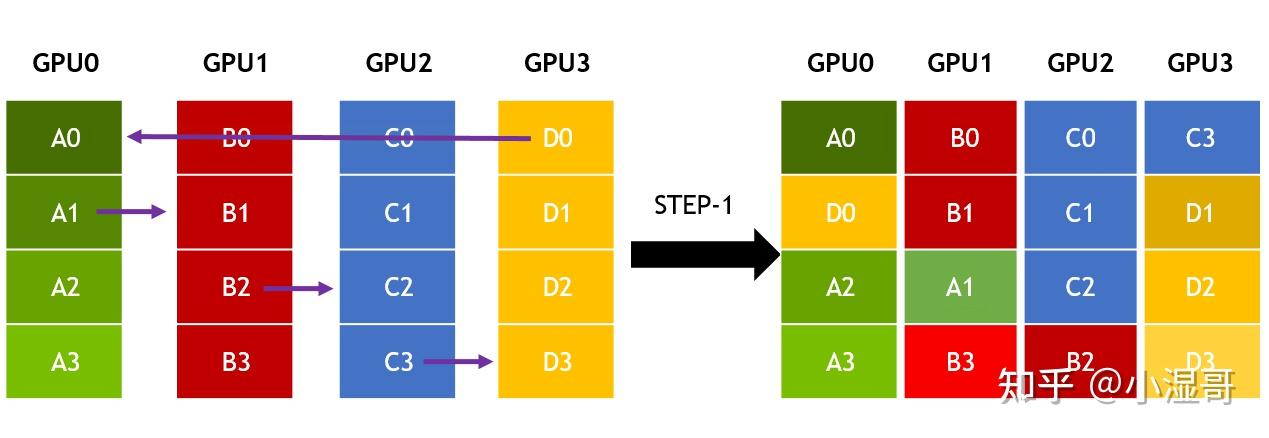
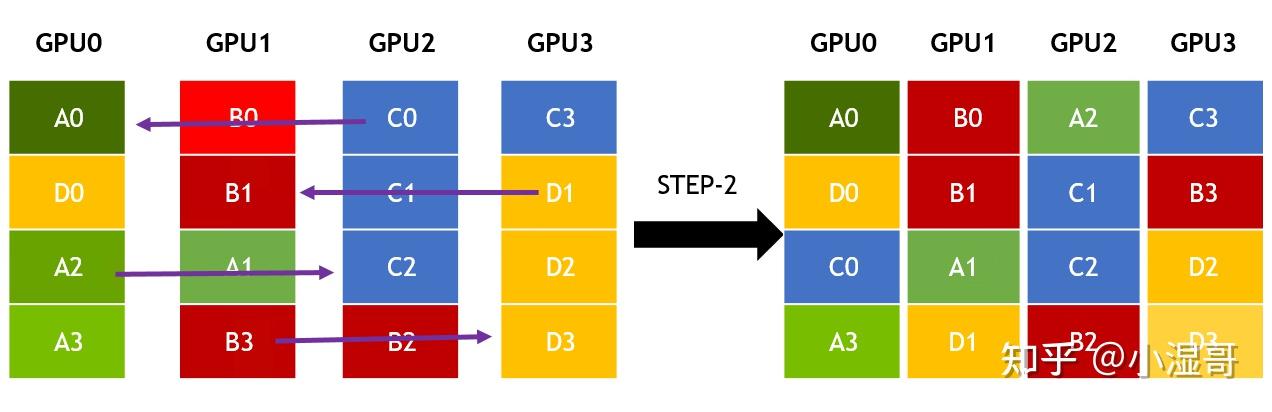
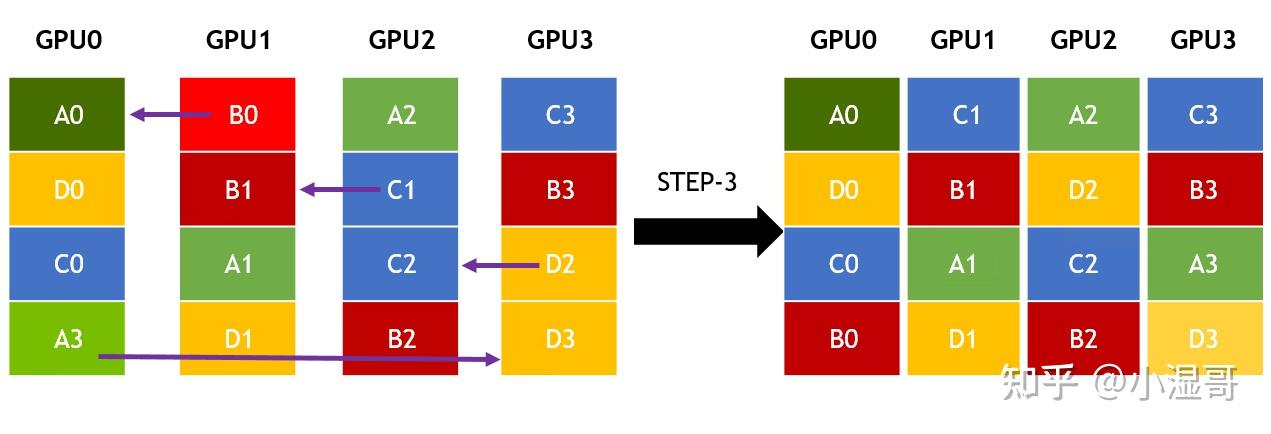
All-toAll是点对点通信,将每一个维度发送到对应的GPU节点上。
� 个GPU,维度也是 � , 一个GPU数据量为 � , 链路带宽为 �
一次发送数据量为 �/�
一次发送的时间 �=�/(��)
一共要发送 �−1 次
总时间 �=(�−1)∗�=(�−1)���
�����=�/�=�∗�/(�−1)
�=�����∗(�−1)/�
nccl-test源码:
| void AlltoAllGetBw(size_t count, int typesize, double sec, double* algBw, double* busBw, int nranks) { double baseBw = (double)(count * nranks * typesize) / 1.0E9 / sec; *algBw = baseBw; double factor = ((double)(nranks-1))/((double)(nranks)); *busBw = baseBw * factor; } |
|---|
发布于 2023-10-16 11:46・IP 属地广东


 浙公网安备 33010602011771号
浙公网安备 33010602011771号