

【RDMA】4. RDMA操作类型|WRITE|READ
目录
原文:Savir - 知乎
前面几篇涉及RDMA的通信流程时一直在讲SEND-RECV,然而它其实称不上是“RDMA”,只是一种加入了0拷贝和协议栈卸载的传统收发模型的“升级版”,这种操作类型没有完全发挥RDMA技术全部实力,常用于两端交换控制信息等场景。当涉及大量数据的收发时,更多使用的是两种RDMA独有的操作:WRITE和READ。
我们先来复习下双端操作——SEND和RECV,然后再对比介绍单端操作——WRITE和READ。
SEND & RECV
SEND和RECV是两种不同的操作类型,但是因为如果一端进行SEND操作,对端必须进行RECV操作,所以通常都把他们放到一起描述。
为什么称之为“双端操作”?因为完成一次通信过程需要两端CPU的参与,并且收端需要提前显式的下发WQE。下图是一次SEND-RECV操作的过程示意图。原图来自于[1],我做了一些修改。
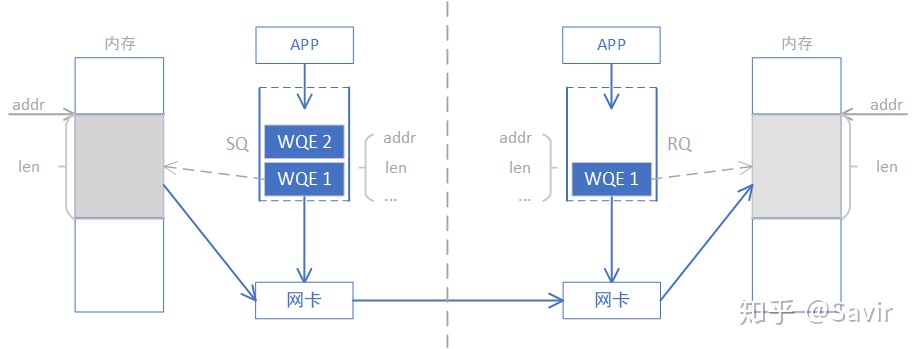
上一篇我们讲过,上层应用通过WQE(WR)来给硬件下任务。在SEND-RECV操作中,不止发送端需要下发WQE,接收端也需要下发WQE来告诉硬件收到的数据需要放到哪个地址。发送端并不知道发送的数据会放到哪里,每次发送数据,接收端都要提前准备好接收Buffer,而接收端CPU自然会感知这一过程。
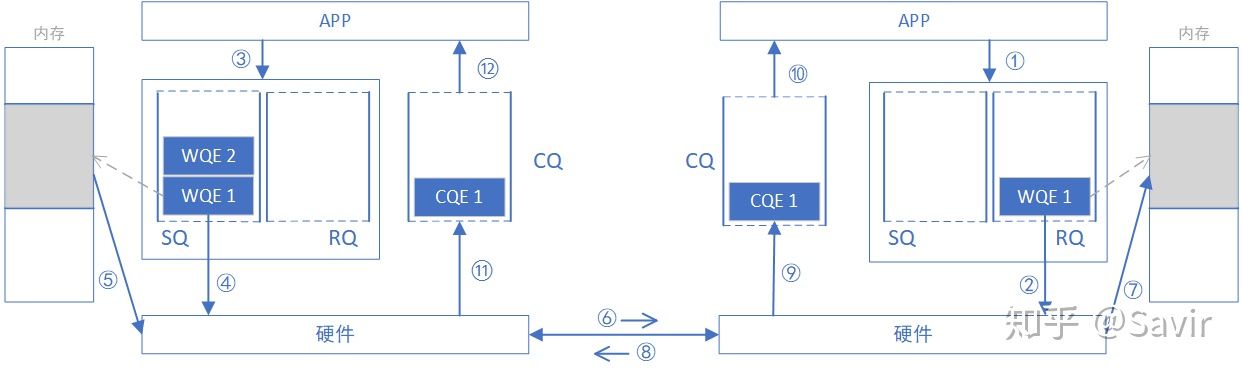
为了下文对比SEND/RECV与WRITE/READ的异同,我们将上一篇的SEND-RECV流程中补充内存读写这一环节,即下图中的步骤⑤——发送端硬件根据WQE从内存中取出数据封装成可在链路上传输数据包和步骤⑦——接收端硬件将数据包解析后根据WQE将数据放到指定内存区域,其他步骤不再赘述。另外再次强调一下,收发端的步骤未必是图中这个顺序,比如步骤⑧⑪⑫和步骤⑨⑩的先后顺序就是不一定的。
下面将介绍WRITE操作,对比之后相信大家可以理解的更好。
WRITE
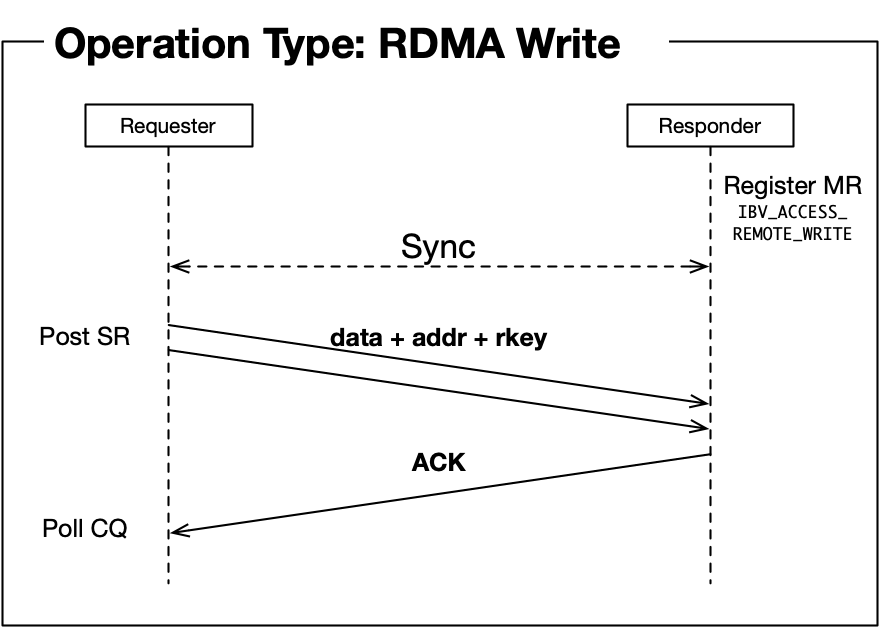
WRITE全称是RDMA WRITE操作,是本端主动写入远端内存的行为,除了准备阶段,远端CPU不需要参与,也不感知何时有数据写入、数据在何时接收完毕。所以这是一种单端操作。
通过下图我们对比一下WRITE和SEND-RECV操作的差异,本端在准备阶段通过数据交互,获取了对端某一片可用的内存的地址和“钥匙”,相当于获得了这片远端内存的读写权限。拿到权限之后,本端就可以像访问自己的内存一样直接对这一远端内存区域进行读写,这也是RDMA——远程直接地址访问的内涵所在。
WRITE/READ操作中的目的地址和钥匙是如何获取的呢?通常可以通过我们刚刚讲过的SEND-RECV操作来完成,因为拿到钥匙这个过程总归是要由远端内存的控制者——CPU允许的。虽然准备工作还比较复杂, 但是一旦完成准备工作,RDMA就可以发挥其优势,对大量数据进行读写。一旦远端的CPU把内存授权给本端使用,它便不再会参与数据收发的过程,这就解放了远端CPU,也降低了通信的时延。
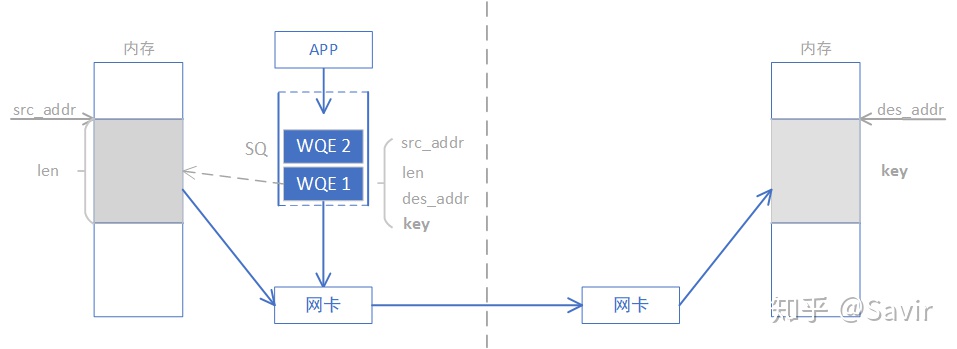
需要注意的是,本端是通过虚拟地址来读写远端内存的,上层应用可以非常方便的对其进行操作。实际的虚拟地址—物理地址的转换是由RDMA网卡完成的。具体是如何转换的,将在后面的文章介绍。
忽略准备阶段key和addr的获取过程,下面我们描述一次WRITE操作的流程,此后我们不再将本端称为“发送”和“接收”端,而是改为“请求”和“响应”端,这样对于描述WRITE和READ操作都更恰当一些,也不容易产生歧义。
- 请求端APP以WQE(WR)的形式下发一次WRITE任务。
- 请求端硬件从SQ中取出WQE,解析信息。
- 请求端网卡根据WQE中的虚拟地址,转换得到物理地址,然后从内存中拿到待发送数据,组装数据包。
- 请求端网卡将数据包通过物理链路发送给响应端网卡。
- 响应端收到数据包,解析目的虚拟地址,转换成本地物理地址,解析数据,将数据放置到指定内存区域。
- 响应端回复ACK报文给请求端。
- 请求端网卡收到ACK后,生成CQE,放置到CQ中。
- 请求端APP取得任务完成信息。
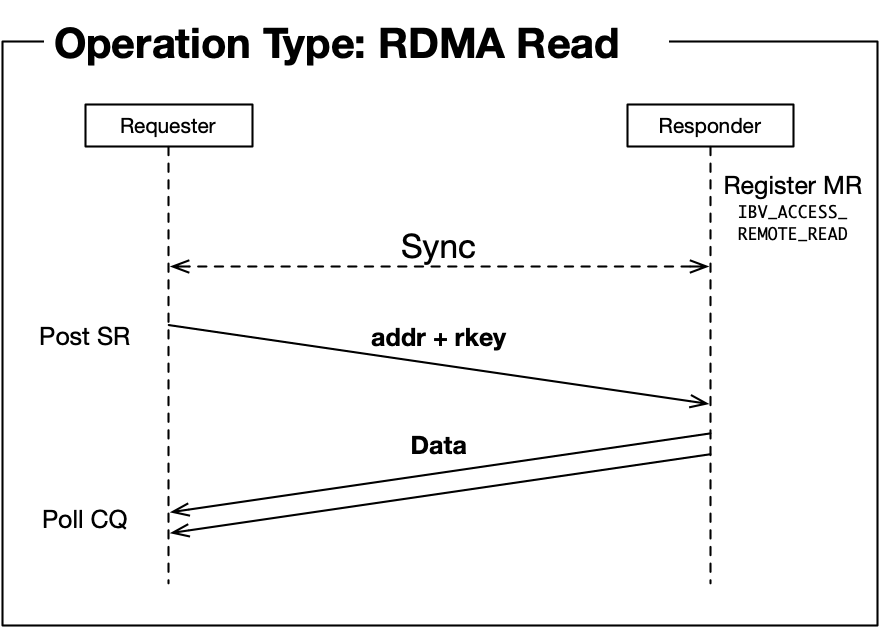
READ
顾名思义,READ跟WRITE是相反的过程,是本端主动读取远端内存的行为。同WRITE一样,远端CPU不需要参与,也不感知数据在内存中被读取的过程。
获取key和虚拟地址的流程也跟WRITE没有区别,需要注意的是“读”这个动作所请求的数据,是在对端回复的报文中携带的。
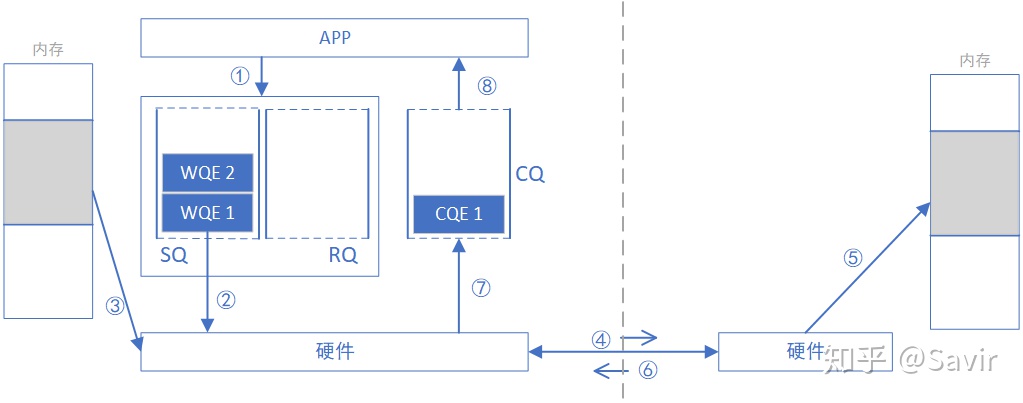
下面描述一次READ操作的流程,注意跟WRITE只是方向和步骤顺序的差别。
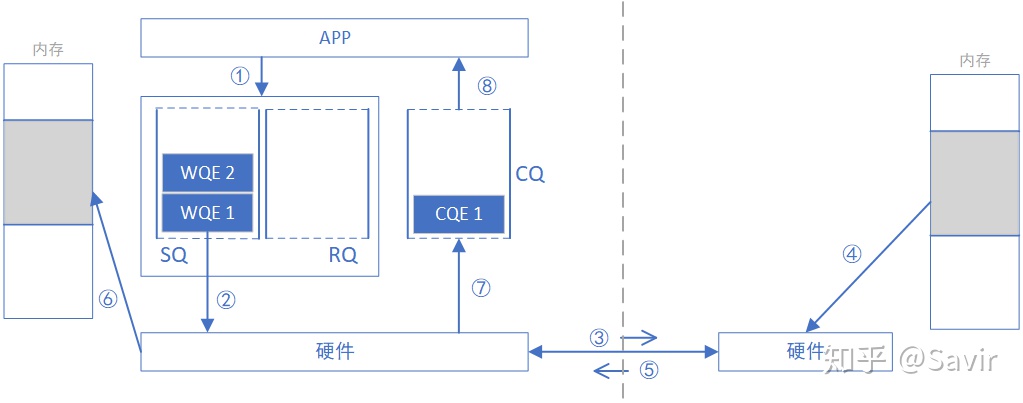
- 请求端APP以WQE的形式下发一次READ任务。
- 请求端网卡从SQ中取出WQE,解析信息。
- 请求端网卡将READ请求包通过物理链路发送给响应端网卡。
- 响应端收到数据包,解析目的虚拟地址,转换成本地物理地址,解析数据,从指定内存区域取出数据。
- 响应端硬件将数据组装成回复数据包发送到物理链路。
- 请求端硬件收到数据包,解析提取出数据后放到READ WQE指定的内存区域中。
- 请求端网卡生成CQE,放置到CQ中。
- 请求端APP取得任务完成信息。
总结
我们忽略各种细节进行抽象,RDMA WRITE和READ操作就是在利用网卡完成下面左图的内存拷贝操作而已,只不过复制的过程是由RDMA网卡通过网络链路完成的;而本地内存拷贝则如下面右图所示由CPU通过总线完成的:
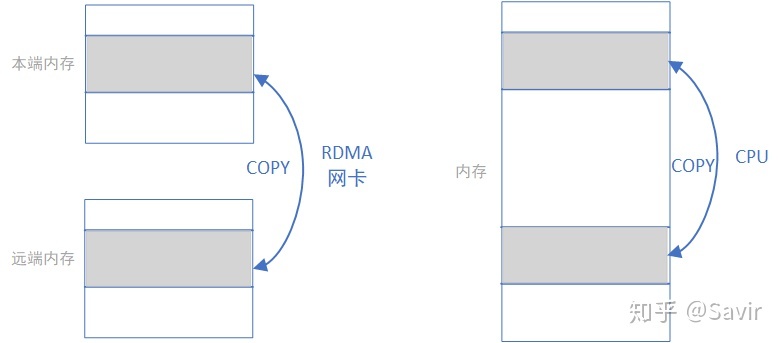
RDMA标准定义上述几种操作的时候使用的单词是非常贴切的,“收”和“发”是需要有对端主动参与的语义 ,而‘读“和”写“更像是本端对一个没有主动性的对端进行操作的语义。
通过对比SEND/RECV和WRITE/READ操作,我们可以发现传输数据时不需要响应端CPU参与的WRITE/READ有更大的优势,缺点就是请求端需要在准备阶段获得响应端的一段内存的读写权限。但是实际数据传输时,这个准备阶段的功率和时间损耗都是可以忽略不计的,所以RDMA WRITE/READ才是大量传输数据时所应用的操作类型,SEND/RECV通常只是用来传输一些控制信息。
除了本文介绍的几种操作之外,还有ATOMIC等更复杂一些的操作类型,将在后面的协议解读部分详细分析。本篇就到这里,下一篇将介绍RDMA 基本服务类型。
参考资料
[1] part1-OFA_Training_Sept_2016.pdf
WRITE|READ编程(RDMA read and write with IB verbs)
(本文讲解的示例代码在:RDMA read and write with IB verbs | The Geek in the Corner)
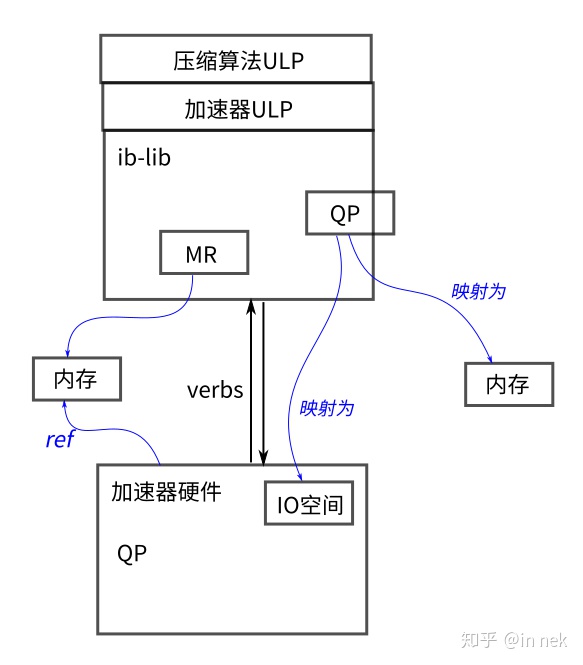
将 RDMA 与verbs一起使用非常简单:首先注册内存块,然后交换内存描述符,然后进行读/写操作。注册是通过调用 ibv_reg_mr() 来完成的,它将内存块固定(从而防止它被交换出)并返回一个包含 uint32_t key的结构 ibv_mr * ,允许远程访问注册的内存。然后必须通过某种带外机制与对等方交换此key以及块的地址。然后,对方可以在调用 ibv_post_send() 时使用key和地址来post RDMA 读和写请求。
一些代码可能有指导意义:
/* PEER 1 */
/* PEER 1 */
const size_t SIZE = 1024;
char *buffer = malloc(SIZE);
struct ibv_mr *mr;
uint32_t my_key;
uint64_t my_addr;
mr = ibv_reg_mr(
pd,
buffer,
SIZE,
IBV_ACCESS_REMOTE_WRITE);
my_key = mr->rkey;
my_addr = (uint64_t)mr->addr;
/* exchange my_key and my_addr with peer 2 */
/* PEER 2 */
/* PEER 2 */
const size_t SIZE = 1024;
char *buffer = malloc(SIZE);
struct ibv_mr *mr;
struct ibv_sge sge;
struct ibv_send_wr wr, *bad_wr;
uint32_t peer_key;
uint64_t peer_addr;
mr = ibv_reg_mr(
pd,
buffer,
SIZE,
IBV_ACCESS_LOCAL_WRITE);
/* get peer_key and peer_addr from peer 1 */
strcpy(buffer, "Hello!");
memset(&wr, 0, sizeof(wr));
sge.addr = (uint64_t)buffer;
sge.length = SIZE;
sge.lkey = mr->lkey;
wr.sg_list = &sge;
wr.num_sge = 1;
wr.opcode = IBV_WR_RDMA_WRITE;
wr.wr.rdma.remote_addr = peer_addr;
wr.wr.rdma.rkey = peer_key;
ibv_post_send(qp, &wr, &bad_wr);PEER 1 的 ibv_reg_mr() 的最后一个参数 IBV_ACCESS_REMOTE_WRITE 指定我们希望对PEER 2 具有对位于缓冲区的内存块的写访问权限。
在实践中使用它更复杂。本文附带的示例代码连接两台主机,交换内存区域密钥keys、读取或写入远程内存,然后断开连接。顺序如下:
- 初始化上下文并注册内存区域。
- 建立连接。
- 使用之前帖子中描述的发送/接收模型在对等点之间交换内存区域密钥keys。
- 后读/写操作。
- 断开。
连接的每一端都有两个线程:处理连接事件的主线程和轮询完成队列(CQ)的线程。为了避免死锁和竞争条件,我们安排了我们的操作,以便一次只有一个线程发布工作请求。为了详细说明上面的顺序,在建立连接后,
客户端将:
- 在 MSG_MR 消息中发送其 RDMA 内存区域密钥keys。
- 等待服务器的 MSG_MR 消息(包含其 RDMA 密钥keys)。
- 发布 RDMA 操作。
- 通过发送 MSG_DONE 消息通知服务器它已准备好断开连接。
- 等待来自服务器的 MSG_DONE 消息。
- 断开。
第一步发生在 RDMA 连接事件处理程序线程的上下文中,但第二步到第六步发生在verbs CQ 轮询线程的上下文中。(verbs =verbs api =verbs 库)
服务端的操作顺序类似:
- 等待客户端的 MSG_MR 消息及其 RDMA 密钥。
- 在 MSG_MR 消息中发送其 RDMA 密钥。
- 发布 RDMA 操作。
- 通过发送 MSG_DONE 消息通知客户端它已准备好断开连接。
- 等待来自客户端的 MSG_DONE 消息。
- 断开。
这里所有六个步骤都发生在verbs CQ 轮询线程的上下文中。等待 MSG_DONE 是必要的,否则我们可能会在对等方(peer)的 RDMA 操作完成之前关闭连接。在(服务端)发送 MSG_DONE 之前,我们不必等待 RDMA 操作 完成——InfiniBand 规范要求 requests 将按照它们发布的顺序启动 处理。这意味着在 RDMA 操作完成之前,对等方(peer)不会收到 MSG_DONE。
为简洁起见(并说明它们几乎相同),此示例的代码合并了上一组帖子中的许多客户端和服务器代码(common.c中),客户端 (rdma-client) 和服务器 (rdma-server) 继续运行不同的 RDMA 连接管理器循环处理事件(RDMA connection manager event loops),但它们相同的verbs 代码部分——轮询 CQ、发送消息、发布 RDMA 操作等共用一份代码。
我们也使用相同代码进行RDMA 读取和写入操作,因为它们非常相似。 rdma-server 和 rdma-client 将““read” or “write” 作为它们的第一个命令行参数。
让我们从 rdma-common.c 的顶部开始,它包含客户端和服务器通用的verbs 代码。我们首先定义我们的消息结构体。我们将使用它来在节点之间传递 RDMA 内存区域 (MR) 密钥并发出我们已完成的信号。
struct message
{
enum {
MSG_MR,
MSG_DONE
} type;
union {
struct ibv_mr mr;
} data;
};我们的连接结构体已扩展,包括用于 RDMA 操作的内存区域以及对等方(peer)的 MR 结构和两个状态变量:
struct connection
{
struct rdma_cm_id *id;
struct ibv_qp *qp;
int connected;
struct ibv_mr *recv_mr;
struct ibv_mr *send_mr;
struct ibv_mr *rdma_local_mr;
struct ibv_mr *rdma_remote_mr;
struct ibv_mr peer_mr;
struct message *recv_msg;
struct message *send_msg;
char *rdma_local_region;
char *rdma_remote_region;
enum {
SS_INIT,
SS_MR_SENT,
SS_RDMA_SENT,
SS_DONE_SENT
} send_state;
enum {
RS_INIT,
RS_MR_RECV,
RS_DONE_RECV
} recv_state;
};完成处理程序(completion handler)使用 send_state 和 recv_state 这两个状态枚举变量来确保对等点(peer)之间的消息和 RDMA 操作的正确顺序。
该结构体由 build_connection() 初始化:
void build_connection(struct rdma_cm_id *id)
{
struct connection *conn;
struct ibv_qp_init_attr qp_attr;
build_context(id->verbs);
build_qp_attr(&qp_attr);
TEST_NZ(rdma_create_qp(id, s_ctx->pd, &qp_attr));
id->context = conn = (struct connection *)malloc(sizeof(struct connection));
conn->id = id;
conn->qp = id->qp;
conn->send_state = SS_INIT;
conn->recv_state = RS_INIT;
conn->connected = 0;
register_memory(conn);
post_receives(conn);
}由于我们使用 RDMA read操作,我们必须在 struct rdma_conn_param 中设置initiator_depth 和responder_resources。这些控制并行的 RDMA read请求的数量(These control the number of simultaneous outstanding RDMA read requests):
void build_params(struct rdma_conn_param *params)
{
memset(params, 0, sizeof(*params));
params->initiator_depth = params->responder_resources = 1;
params->rnr_retry_count = 7; /* infinite retry */
}将 rnr_retry_count 设置为 7 表示我们希望网卡在对端回复 receiver-not-ready (RNR) 错误时无限期地重新发送。当在对端发布相应的接收请求( receive request)之前发布发送请求(send request )时,会发生 RNR。
使用 send_message() 函数post 发送:
void send_message(struct connection *conn)
{
struct ibv_send_wr wr, *bad_wr = NULL;
struct ibv_sge sge;
memset(&wr, 0, sizeof(wr));
wr.wr_id = (uintptr_t)conn;
wr.opcode = IBV_WR_SEND;
wr.sg_list = &sge;
wr.num_sge = 1;
wr.send_flags = IBV_SEND_SIGNALED;
sge.addr = (uintptr_t)conn->send_msg;
sge.length = sizeof(struct message);
sge.lkey = conn->send_mr->lkey;
while (!conn->connected);
TEST_NZ(ibv_post_send(conn->qp, &wr, &bad_wr));
}send_mr() 封装了这个函数,并被 rdma-client 用来将它的 MR 发送到服务器,提示服务器发送它的 MR 作为响应,从而启动 RDMA 操作:
void send_mr(void *context)
{
struct connection *conn = (struct connection *)context;
conn->send_msg->type = MSG_MR;
memcpy(&conn->send_msg->data.mr, conn->rdma_remote_mr, sizeof(struct ibv_mr));
send_message(conn);
}完成处理程序( completion handler)完成大部分工作。它维护 send_state 和 recv_state,根据需要回复消息和发布 RDMA 操作:
void on_completion(struct ibv_wc *wc)
{
struct connection *conn = (struct connection *)(uintptr_t)wc->wr_id;
if (wc->status != IBV_WC_SUCCESS)
die("on_completion: status is not IBV_WC_SUCCESS.");
if (wc->opcode & IBV_WC_RECV) {
conn->recv_state++;
if (conn->recv_msg->type == MSG_MR) {
memcpy(&conn->peer_mr, &conn->recv_msg->data.mr, sizeof(conn->peer_mr));
post_receives(conn); /* only rearm for MSG_MR */
if (conn->send_state == SS_INIT) /* received peer's MR before sending ours, so send ours back */
send_mr(conn);
}
} else {
conn->send_state++;
printf("send completed successfully.\n");
}
if (conn->send_state == SS_MR_SENT && conn->recv_state == RS_MR_RECV) {
struct ibv_send_wr wr, *bad_wr = NULL;
struct ibv_sge sge;
if (s_mode == M_WRITE)
printf("received MSG_MR. writing message to remote memory...\n");
else
printf("received MSG_MR. reading message from remote memory...\n");
memset(&wr, 0, sizeof(wr));
wr.wr_id = (uintptr_t)conn;
wr.opcode = (s_mode == M_WRITE) ? IBV_WR_RDMA_WRITE : IBV_WR_RDMA_READ;
wr.sg_list = &sge;
wr.num_sge = 1;
wr.send_flags = IBV_SEND_SIGNALED;
wr.wr.rdma.remote_addr = (uintptr_t)conn->peer_mr.addr;
wr.wr.rdma.rkey = conn->peer_mr.rkey;
sge.addr = (uintptr_t)conn->rdma_local_region;
sge.length = RDMA_BUFFER_SIZE;
sge.lkey = conn->rdma_local_mr->lkey;
TEST_NZ(ibv_post_send(conn->qp, &wr, &bad_wr));
conn->send_msg->type = MSG_DONE;
send_message(conn);
} else if (conn->send_state == SS_DONE_SENT && conn->recv_state == RS_DONE_RECV) {
printf("remote buffer: %s\n", get_peer_message_region(conn));
rdma_disconnect(conn->id);
}
}
Let’s examine on_completion() in parts. First, the state update:
if (wc->opcode & IBV_WC_RECV) {
conn->recv_state++;
if (conn->recv_msg->type == MSG_MR) {
memcpy(&conn->peer_mr, &conn->recv_msg->data.mr, sizeof(conn->peer_mr));
post_receives(conn); /* only rearm for MSG_MR */
if (conn->send_state == SS_INIT) /* received peer's MR before sending ours, so send ours back */
send_mr(conn);
}
} else {
conn->send_state++;
printf("send completed successfully.\n");如果完成的操作是接收操作(即,如果 wc->opcode 设置了 IBV_WC_RECV),则 recv_state 递增。
如果收到的消息是 MSG_MR,我们将收到的 MR 复制到我们的连接结构的 peer_mr 成员中,并重新准备接收槽。这对于确保我们在对端的 RDMA 操作完成后收到 MSG_DONE 消息是必要的。如果我们收到了对方的 MR 但还没有发送我们的(服务器就是这种情况),我们就调用 send_mr() 将我们的 MR 发给对方。更新 send_state 并不复杂。
接下来我们检查 send_state 和 recv_state 的两个特定组合:
if (conn->send_state == SS_MR_SENT && conn->recv_state == RS_MR_RECV)
{
struct ibv_send_wr wr, *bad_wr = NULL;
struct ibv_sge sge;
if (s_mode == M_WRITE)
printf("received MSG_MR. writing message to remote memory...\n");
else
printf("received MSG_MR. reading message from remote memory...\n");
memset(&wr, 0, sizeof(wr));
wr.wr_id = (uintptr_t)conn;
wr.opcode = (s_mode == M_WRITE) ? IBV_WR_RDMA_WRITE : IBV_WR_RDMA_READ;
wr.sg_list = &sge;
wr.num_sge = 1;
wr.send_flags = IBV_SEND_SIGNALED;
wr.wr.rdma.remote_addr = (uintptr_t)conn->peer_mr.addr;
wr.wr.rdma.rkey = conn->peer_mr.rkey;
sge.addr = (uintptr_t)conn->rdma_local_region;
sge.length = RDMA_BUFFER_SIZE;
sge.lkey = conn->rdma_local_mr->lkey;
TEST_NZ(ibv_post_send(conn->qp, &wr, &bad_wr));
conn->send_msg->type = MSG_DONE;
send_message(conn);
}
else if (conn->send_state == SS_DONE_SENT && conn->recv_state == RS_DONE_RECV)
{
printf("remote buffer: %s\n", get_peer_message_region(conn));
rdma_disconnect(conn->id);
}这些组合中的第一个是当我们既发送了我们的 MR 又收到了对方的 MR 时。这表明我们已准备好发布 RDMA 操作并发布 MSG_DONE。发布 RDMA 操作意味着构建 RDMA 工作请求(RDMA work request)。这类似于发送工作请求( work request),除了我们指定 RDMA 操作码并传递对等方的 RDMA 地址/密钥:
wr.opcode = (s_mode == M_WRITE) ? IBV_WR_RDMA_WRITE : IBV_WR_RDMA_READ;
wr.wr.rdma.remote_addr = (uintptr_t)conn->peer_mr.addr;
wr.wr.rdma.rkey = conn->peer_mr.rkey;请注意,我们不需要为 remote_addr 使用 conn->peer_mr.addr(即remote_addr不一定非得等于 conn->peer_mr.addr?)— 如果我们愿意,我们可以使用落入 ibv_reg_mr() 注册的内存区域范围内的任何地址(如conn->peer_mr.addr+x,conn->peer_mr.addr+x在注册的内存区域范围内?)。
第二个状态组合是 SS_DONE_SENT 和 RS_DONE_RECV,表明我们已经发送 MSG_DONE 并从对等方接收 MSG_DONE。这意味着打印消息缓冲区并断开连接是安全的:
printf("remote buffer: %s\n", get_peer_message_region(conn));
rdma_disconnect(conn->id);就是这样。如果一切正常,您应该在使用 RDMA 写入时看到以下内容:
|
|
|
|
当使用 RDMA read时:
|
|
|
|
再次,示例代码可在此处获得。
Updated, Oct. 4: Sample code is now at https://github.com/tarickb/the-geek-in-the-corner/tree/master/02_read-write.

https://www.researchgate.net/figure/RDMA-Write_fig2_4245345
Introduction to Programming Infiniband RDMA | Better Tomorrow with Computer Science


 浙公网安备 33010602011771号
浙公网安备 33010602011771号