

04 Hadoop思想与原理
1.用图与自己的话,简要描述Hadoop起源与发展阶段。
2003-2004年,Google公布了部分GFS和MapReduce思想的细节,受此启发的Doug Cutting等人用2年的业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。然后Yahoo招安Doug Gutting及其项目。
2005年,Hadoop作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
2006年2月被分离出来,成为一套完整独立的软件,起名为Hadoop
Hadoop名字不是一个缩写,而是一个生造出来的词。是Hadoop之父Doug Cutting儿子毛绒玩具象命名的。
Hadoop的成长过程
Lucene–>Nutch—>Hadoop
总结起来,Hadoop起源于Google的三大论文
GFS:Google的分布式文件系统Google File System
MapReduce:Google的MapReduce开源分布式并行计算框架
BigTable:一个大型的分布式数据库
演变关系
GFS—->HDFS
Google MapReduce—->Hadoop MapReduce
BigTable—->HBase
2.用图与自己的话,简要描述名称节点、第二名称节点、数据节点的主要功能及相互关系。

HDFS:分布式文件系统把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群
这些节点分为主从节点,主节点可叫作名称节点(NameNode),从节点可叫作数据节点(DataNode)
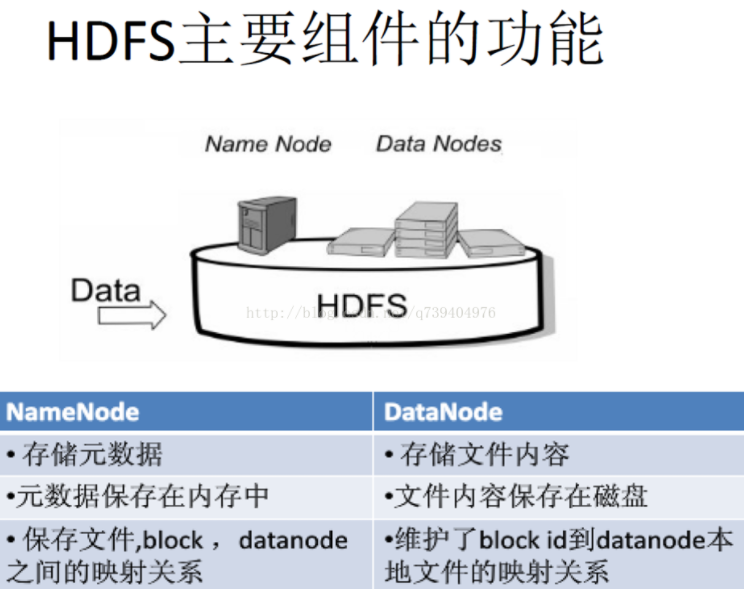
名称节点:
名称节点最主要功能:名称节点记录了每个文件中各个块所在的数据节点的位置信息。
第一名称节点类似于数据目录。其主要有两大构件构成,FsImage和Editlog,FsImage用于存储元数据(长时间不更新、Editlog用于更新数据,但是随着时间推移,Editlog内存储的数据越来越多,导致运行速度越来越慢。所以引入第二名称节点,当第一节点中Editlog到一个临界值时,HDFS会暂停服务,由第二节点将拷贝出Editlog,复制、添加到Fslmage后方并清空原Editlog的内容。
数据节点:
数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表。
5.理解并描述Hbase表与Region的关系。
HBase 表和Region
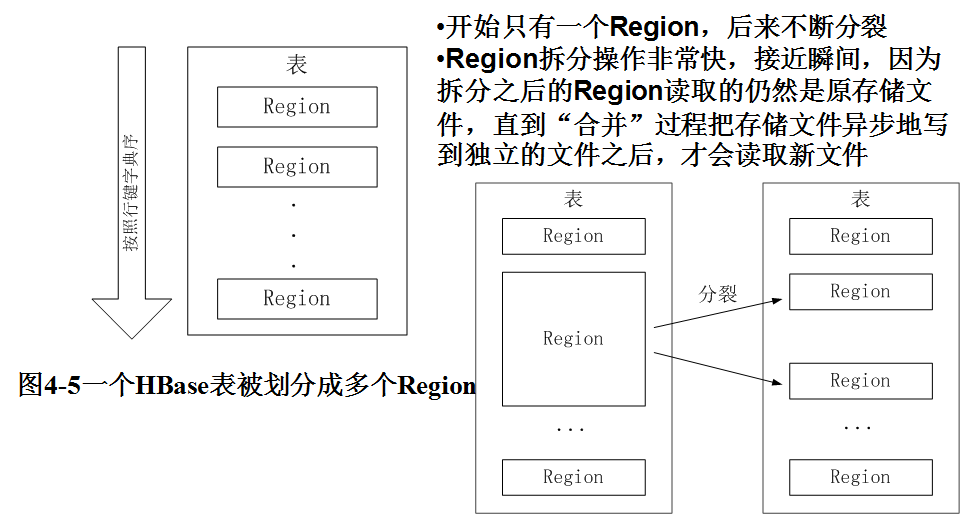

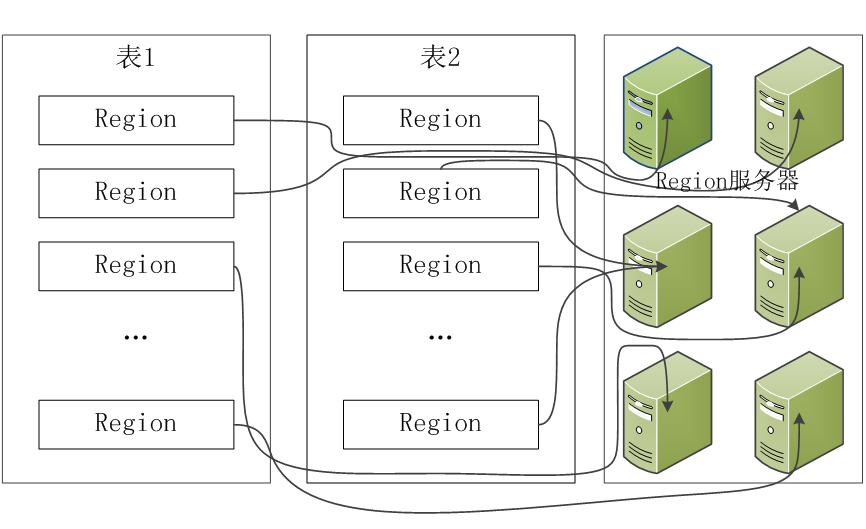
6.理解并描述Hbase的三级寻址。
系统如何找到某个row key (或者某个 row key range)所在的region
bigtable 使用三层类似B+树的结构来保存region位置。
第一层: 保存zookeeper里面的文件,它持有root region的位置。
第二层:root region是.META.表的第一个region其中保存了.META.表其它region的位置。通过root region,我们就可以访问.META.表的数据。
第三层: .META.表它是一个特殊的表,保存了hbase中所有数据表的region 位置信息。
7.通过HBase的三级寻址方式,理论上Hbase的数据表最大有多少个Region?
Region数量
通常较少的region数量可使群集运行的更加平稳,官方指出每个RegionServer大约100个regions的时候效果最好,理由如下:
-
HBase的一个特性MSLAB,它有助于防止堆内存的碎片化,减轻垃圾回收Full GC的问题,默认是开启的。但是每个MemStore需要2MB(一个列簇对应一个写缓存memstore)。所以如果每个region有2个family列簇,总有1000个region,就算不存储数据也要3.95G内存空间。
-
如果很多region,它们中Memstore也过多,内存大小触发Region Server级别限制导致flush,就会对用户请求产生较大的影响,可能阻塞该Region Server上的更新操作。
-
HMaster要花大量的时间来分配和移动Region,且过多Region会增加ZooKeeper的负担。
-
从HBase读入数据进行处理的mapreduce程序,过多Region会产生太多Map任务数量,默认情况下由涉及的region数量决定。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号