Mysql学习笔记
Mysql学习笔记
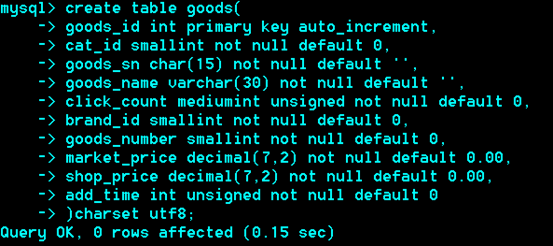
Mysql三大列类型
-
数值型
整型
Tinyint、Smallint、Mediumint、Int、Bigint
小数型
Float(D,M),Decimal(D,M)
-
字符串型
Char(M)
Varchar(M)
Text 文本类型
-
日期时间类型
Date 日期
Time 时间
Datetime 时间类型
Year年类型
-
整型列的字节与存储范围
从数学上讨论tinyint,建表时既能足够存放,又不浪费空间。
即:
(1). 占据空间
(2). 存储范围
Tinyint微小的列类型,1字节。
-
| 类型 | 字节 | 最小值 | 最大值 |
| (带符号/无符号) | (带符号/无符号) | ||
| Tinyint | 1 | -128 | 127 |
| 0 | 255 | ||
| Smallint | 2 | -32768 | 32767 |
| 0 | 65535 | ||
| Mediumint | 3 | -2^23 | 2^23-1 |
| 0 | 2^24-1 | ||
| Int | 4 | -2^31 | 2^31-1 |
| 0 | 2^32-1 | ||
| Bigint | 8 | -2^63 | 2^63-1 |
| 0 | 2^64-1 |
通过占用字节和所存范围分关系合理的选择类型。
例:Tinyint
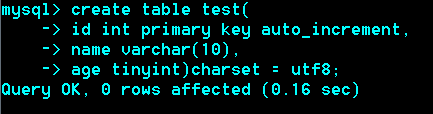


经测试,Tinyint的默认为有符号-128~127之间,当越界时自动取相应的边界值。若要存0~255无符号时:
列的可选属性:
Tinyint(M) unsigned zerofill.
M:宽度(在0填充的时候才有意义)
Unsigned:无符号类型(非负),影响存储范围
Zerofill: 0填充(默认无符号)


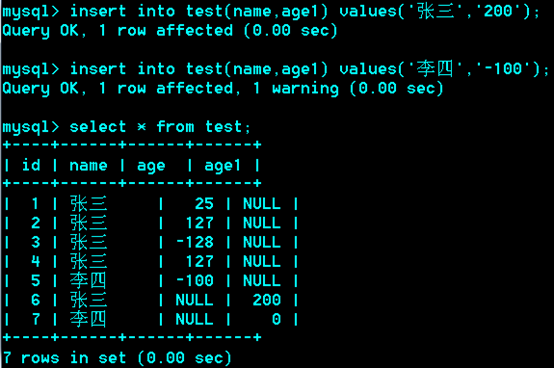
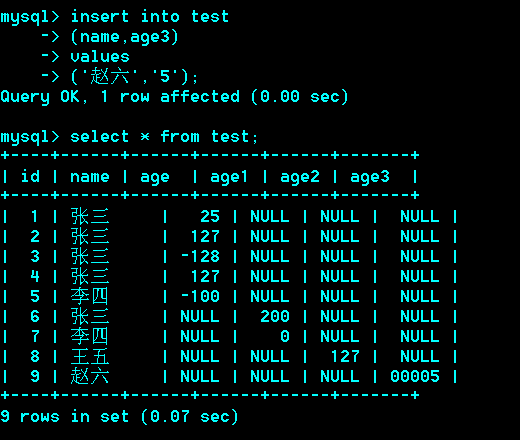
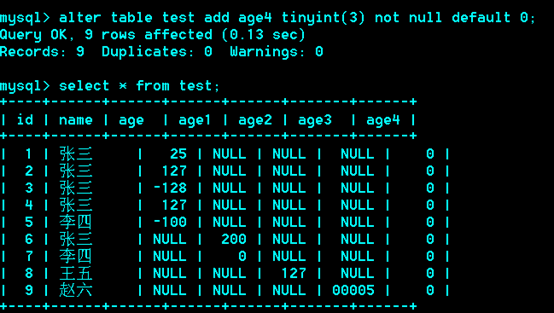
列可以声明默认值,而且推荐声明默认值 not null default 0;
-
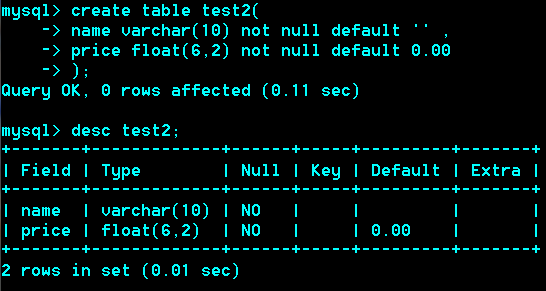
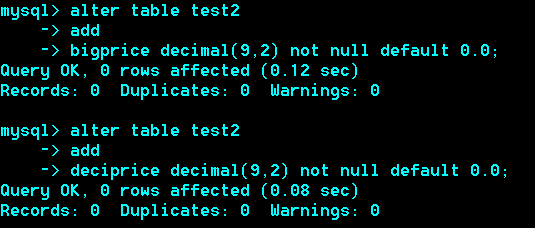
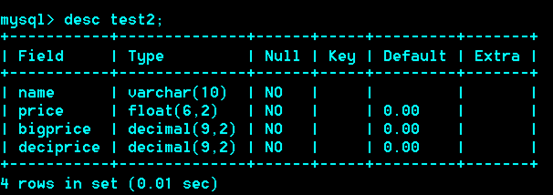
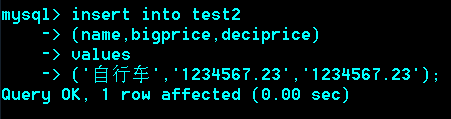
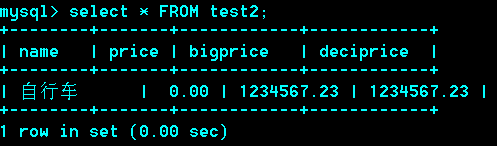
小数型/浮点型、定点型
Float(M,D):M代表总位数,D代表小数位
(6,2)为例:-9999.99 –>9999.99

Decimal(D,M) :
-
字符型列
Char:定长,char(M),M代表宽度,即:可容纳的字符数0<=M<=255
Varchar:变长,0<=M<=65535(约2W—6W个字符受字符集影响)
Text文本串,(约2W—6W个字符受字符集影响)
区别在哪呢?
char定长:M个字符,如果存的小于M个字符,实占M个字符
varchar:M个字符,存的小于M个字符,设为N,N<M,实占N个字符

因此,char定长若存空格,读取时会丢失。而变长不会。
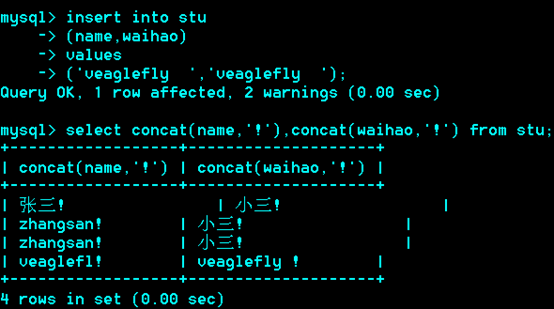
Char利用率小于等于100%,而varchar永远小于100%,1-2个字节用于标志实存字符长度。
Char(M)如何占据M个字符宽度?
答:如果实际存储内容不足M个,则后面加空格补齐,取出来的时候再把后面的空格去掉,(所以如果内容后面有空格,将会被清除)
选择原则:
-
空间利用效率(M固定选Char)
-
速度
速度上:定长速度快些,
-
日期时间列类型
Date 日期
Time 时间
Datatime 时间类型
Year 年类型
-
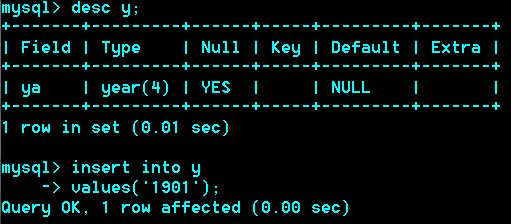
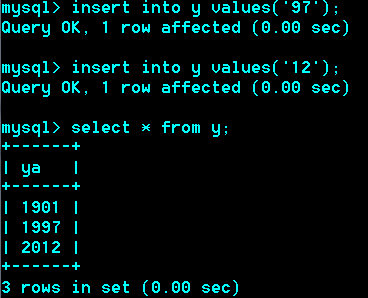
Year类型:1个字节表示1901-2155年【0000年表示错误时】
如果输入两位,"00--69"表示2000—2069,
如果输入两位"70--99"表示1970—1999
如果记得麻烦,输入四位就行了、
-
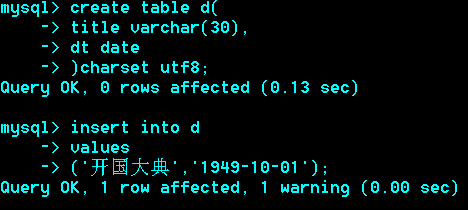
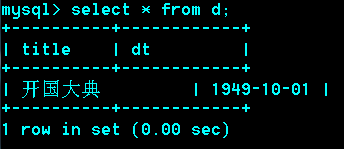
Date类型:典型格式,1992-08-12
'1000-01-01' à'9999-12-31'
-
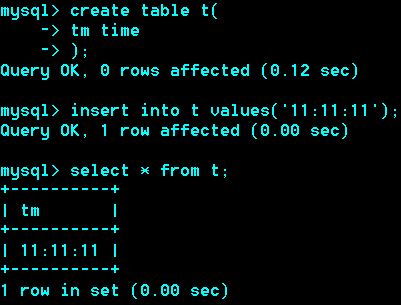
Time 类型,典型格式 hh:mm:ss
'-838:59:59'à'+838:59:59'
-
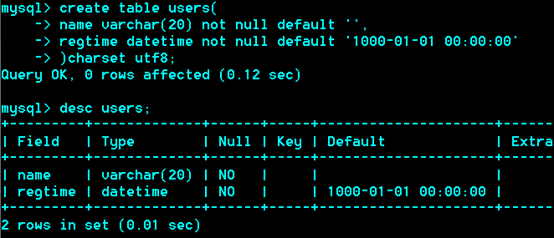
Datetime 典型格式:'1989-05-06 12:23:34'
'1000-01-01 00:00:00'à '9999-12-31 23:59:59`
注意:
在开发中很少使用日期时间类型来表示一个需要精确到秒的列,原因:虽然日期时间类型能够精确到秒,而且方便查看。但是计算不便。用时间戳来表示。
时间戳: 1970-01-01 00:00:00 到当前的秒数
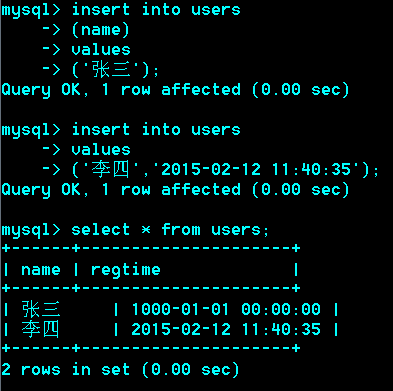
面试1:
当表示性别时,可用1或0表示男女,如,
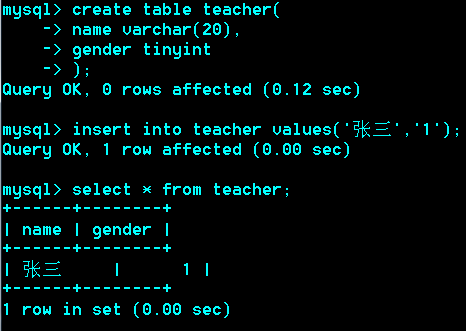
可能会问到为什么不用enum枚举,原因:enum不符合关系型数据库设计理念,而且字节上不比tinyint少。
实例:
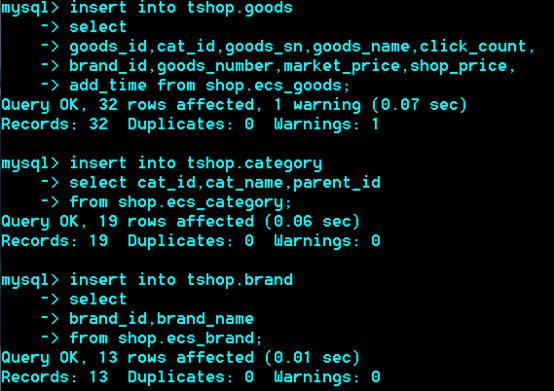
增删改查之案例过程分析
用户注册表单收集,提交数据,注册页面收集到表单的数据后,形成insert语句,user表插入该条数据,用户注册完成
前台用户中心,用户新昵称,根据新昵称和用户id,形成update语句,完成昵称修改
管理后台点击会员列表,此时,网页形成select语句,查询出所有会员的数据,完成会员的查看
管理员后台选中某用户并且删除,捕捉此用户的id,根据用户id形成相应的delete语句
执行delete语句,完成用户的删除。


阶段总结(一)
列类型的概念
数值型
整型 tinyint smallint mediumint int bigint
整型的unsigned代表无符号,zerofill代表0填充,M代表宽度(在0填充)
浮点型/定点型 float(M,D) unsigned Mà精度,即总位数,D代表小数位 decimal比float更精确。
字符型
Char(M)定长,可存储的字符数,M<=255
Varchar(M) ,变长,可存储的字节数,M<=65535
Char与varchar的不同点
Char(M),实占M个字符,不够M个右侧补空格,取出时,在去除右侧空格,导致右侧真有空格时会丢失。
Varchar(M) ,有1-2个字节来标记真实的长度,
日期时间型
Year 1901-2155,如果输2位,'00-69'之间+2000,'70-99'之间+1900
Date YYYY-MM-DD,范围在1000-01-01à9999-12-31
Time HH :ii:ss,范围在-838:59:59à838:59:59
Datetime YY-MM-DD HH:ii:ss 1000-01-01 00:00:00à9999-12-31 23:59:59
开发中的一个问题—精确到秒的时间表示方式,不是用datetime,而是用int来表示时间戳
用时间戳方便计算,而且方便格式化成不同的显示样式。
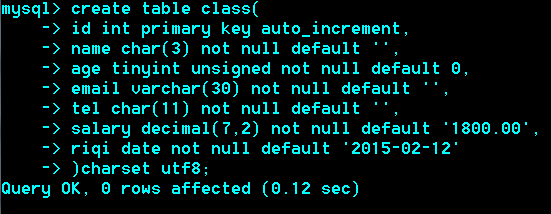
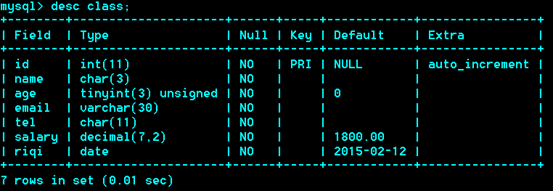
建表语句
Create table 表明(
列名称 ,列类型[列属性][默认值],
…..
)engine 引擎名 charset 字符集
增:insert
答:往哪张表增,增那几列,各为什么值?
Insert into 表名
(列1,列2,..列N)
Values
(值1,值2..值N)
**如果不声明插入的列,则默认插入所有列。
改:update
答:修改哪张表,修改那几列,修改成什么值?在哪几行上生效?
Update表名
Set
列1 = 值1,
列2 = 值2,
….
列N =值N
Where 表达式;
删:delete
删除哪张表的数据,删除哪些行?
Delete from 表名
Where 表达式
查:select * from 表名
查询的五种语句:where,group,having,order by,limit
-
Where 条件查询
比较运算符
-
In <值1,值2,值3…..值N>,等于1àN任意一个。
例:select goods_id from goods where cat_id in(4,5);
-
Between 值1 and 值2,表示在值1和值2之间
例:select goods_id from goods where cat_id between 1 and 5;
逻辑运算符
-
Not 逻辑非
例:select good_id from goods where cat_id not in(4,5);
- Or 逻辑或
- And 逻辑与
模糊查询:
案例:想查找'诺基亚'开头的所有商品
Likeà像,% à 通配任意字符 _ à单个字符
Select goods_id from goods where goods_name like '诺基亚%';
Select goods_id from goods where goods_name like '诺基亚__';
-
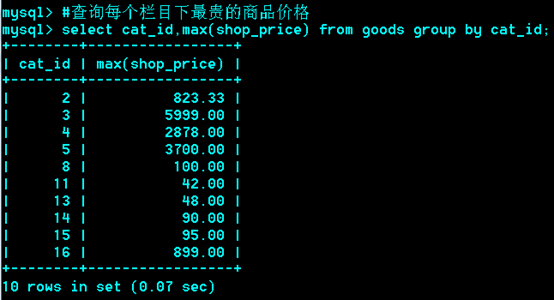
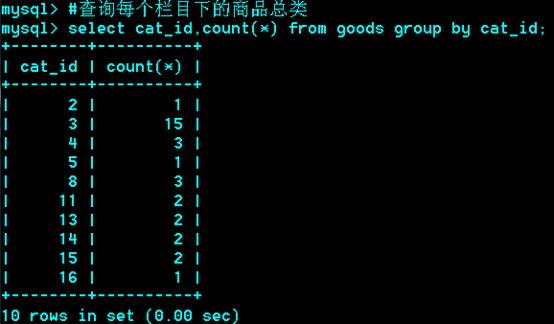
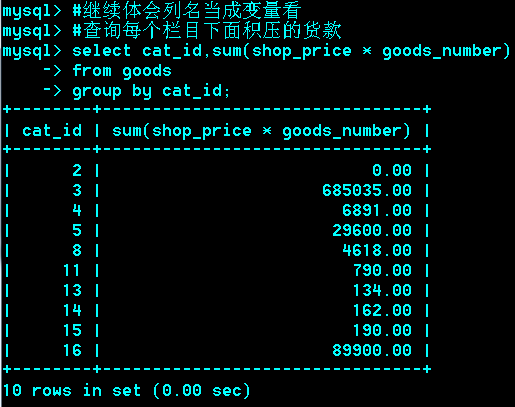
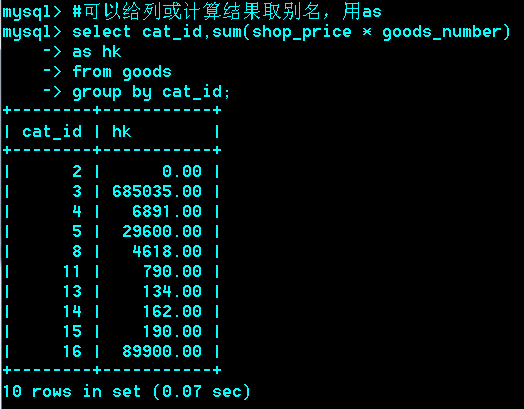
Group分组查询
Group by
作用:把 行按 字段分组
语法: group by col1,col2…colN
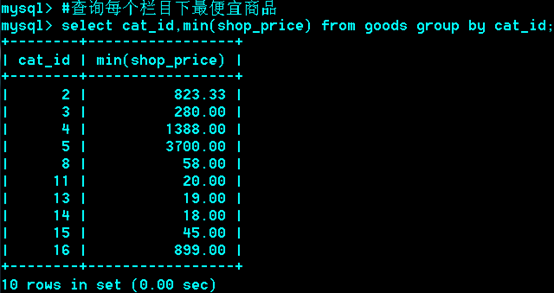
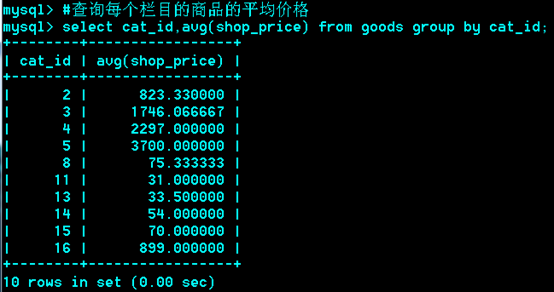
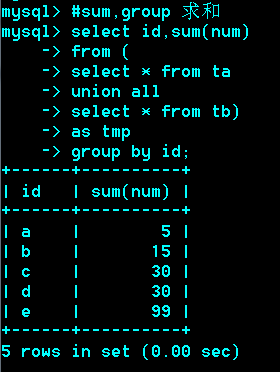
运用场合:常见于统计场合,如按栏目计算帖子数,统计每个人的平均成绩等。
Group与统计函数
Max:求最大,
min: 求最小,
sum:求总和,
avg:求平均,
count:求总行数
练习:
-
-

-
-

-

-
-
-
-
-
-

-
-
-
Having
-
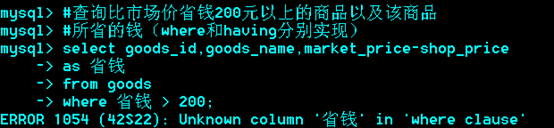
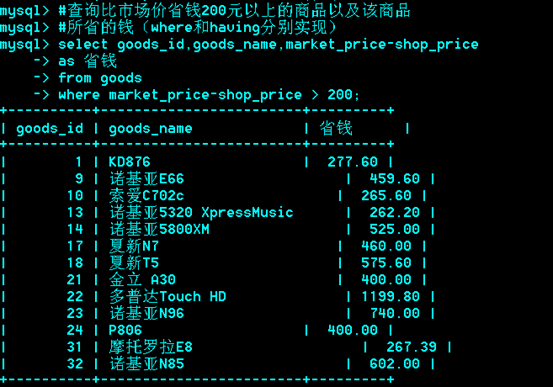
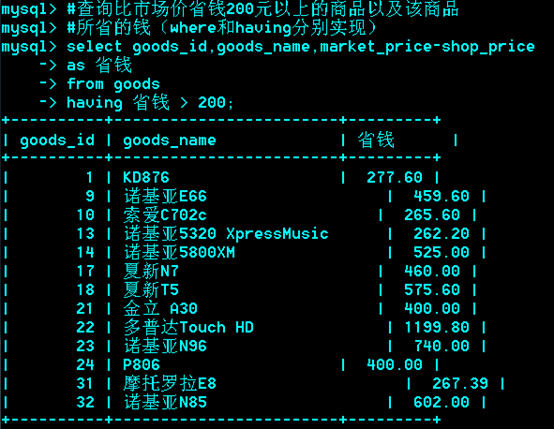
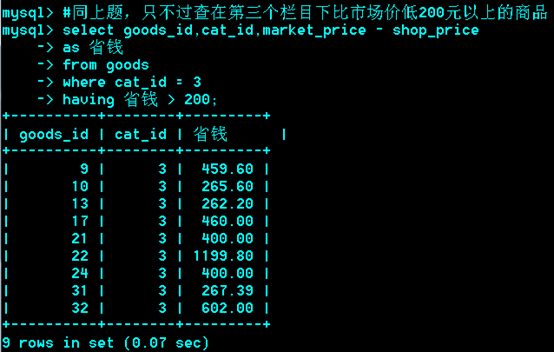
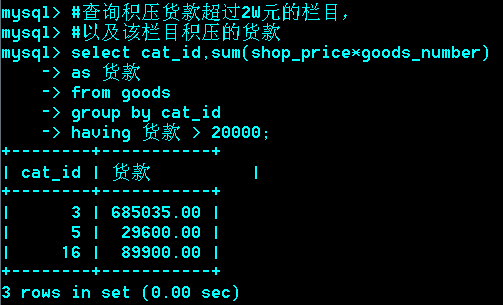
*******例题:

只用一个select,不用子查询和左连接。
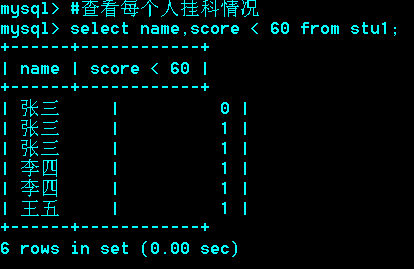
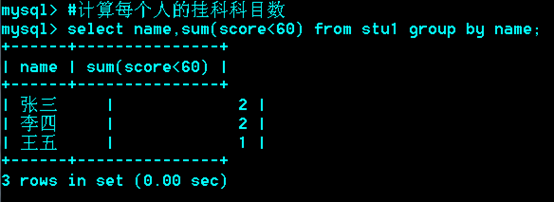
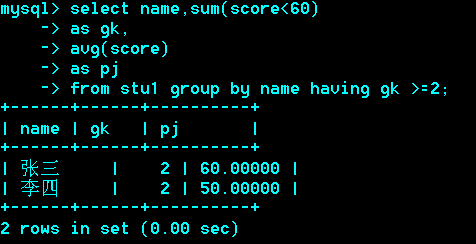
-
Order by
Order by 排序功能
接一个或多个字段对查询结果进行排序
知识点在本项目案例的运用
对栏目的商品按价格由高到低或由低到高排序
知识点的运用场合描述
各种排序场合,如取热点新闻,发帖状元等。

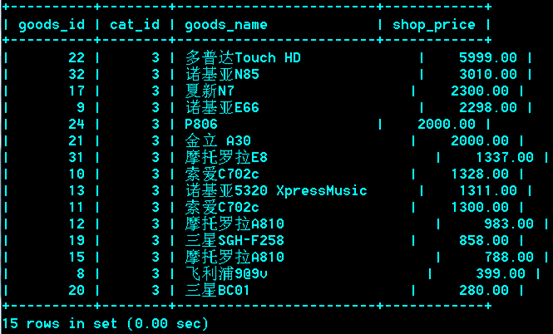

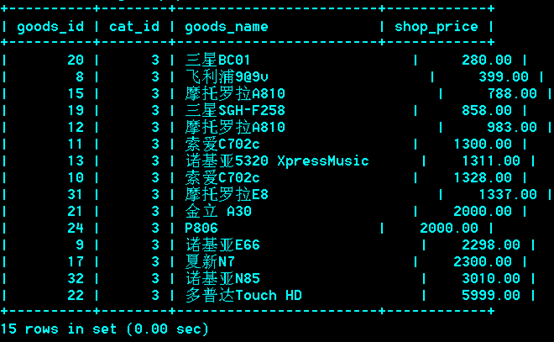
多重排序:

Limit在语句的最后起到了限制条目的作用。
Limit offset,[N]
offset:偏移量,N:条目;如果不写,则从头开始写。即:limit 0,N;
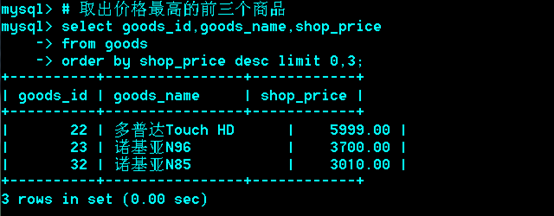


Truncate table清空表
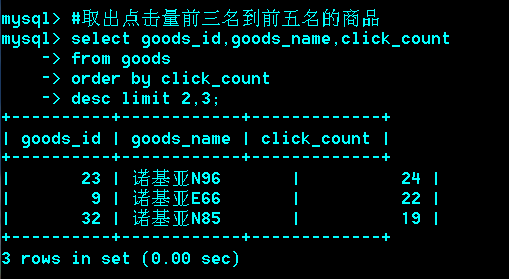
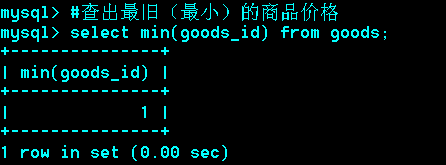
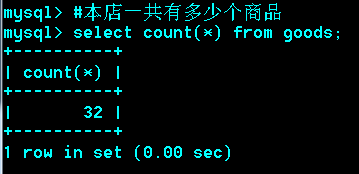
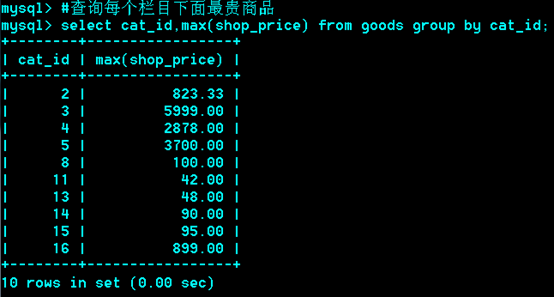
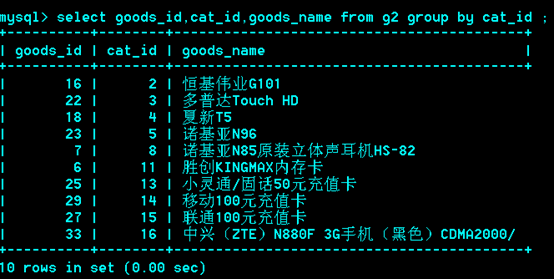
思考:取出每个栏目下最贵的商品
解法一:
首先建个临时表g2,将goods表导入g2,

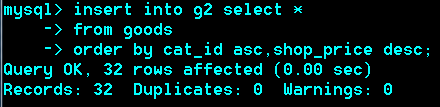
此时,g2中每个栏目的第一个goods_id就是该栏目下最贵的那个,再取出每个栏目下的第一个。
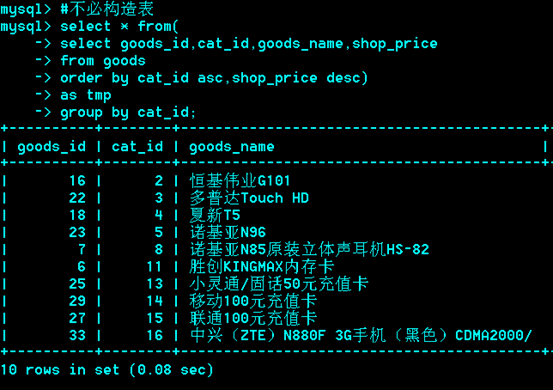
解法二:
思想类似解法一,将select后的结果看作是一张表。
-
良好的理解模型
-
Where 表达式:把表达式放在行中,看表达式是否为真,
-
列:理解成变量,可以运算
-
取出结果:可以理解成一张临时表
-
-
子查询
-
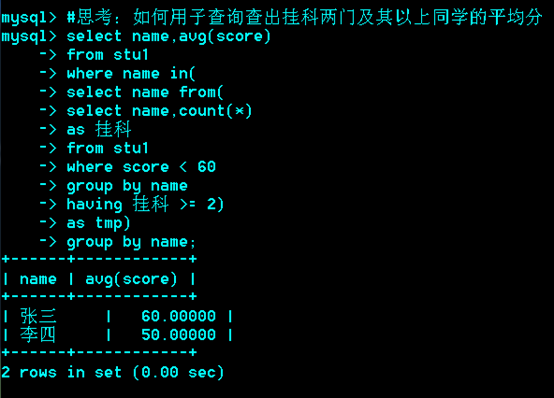
Where型子查询
-
From型子查询
-
Exist型子查询
-
Where型子查询
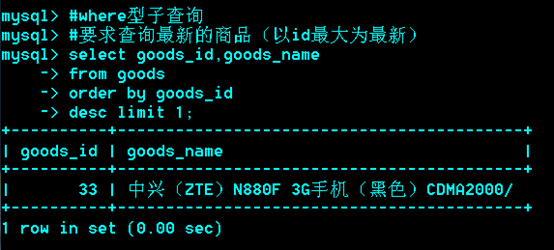

是指把内层的查询结果作为外层查询的比较条件。
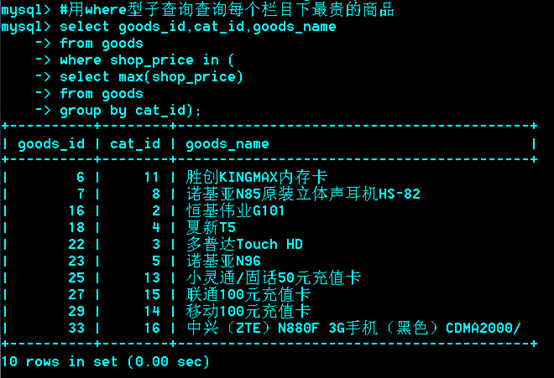
-
From型子查询
把内层的查询结果当成表供外层继续查询
-
-
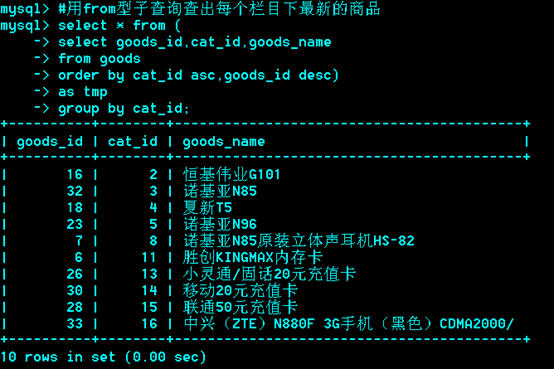
使用了from + where子查询。
-
Exists子查询
把外层的查询结果拿到内层,看内层的查询是否成立。
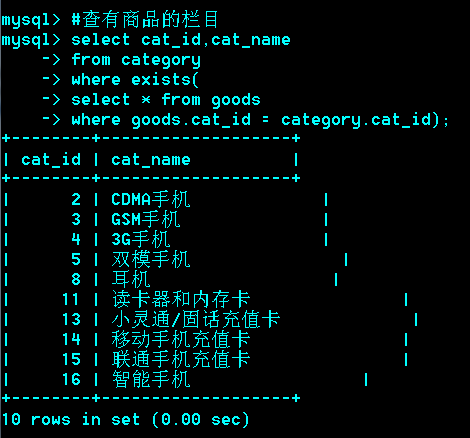
阶段总结二
查select
Where 表达式
表达式在哪一行成立,哪一行就取出来
=,!=/<>,>,<,>=,<=,in,between and,or,not
Group by
分组,一般和统计函数配合使用
Max,min,avg,sum,count
Having
数据在表中,表在硬盘或内存以文件形式存在
Where就是针对表文件发挥作用的
查询的结果,也可以看成一张表,其文件一般临时存在缓冲区
针对查询的结果发挥作用
Order by
作用:排序
可以针对字段,升序【asc】,降序【desc】。
有可能一个字段拍不出结果,可以选用其他字段继续排列
Limit
限制条目
Limit【offset】【N】
Offset:偏移量
N:取出条目,取出3-5条,limit2,3.
子查询
Where型,内层的查询结果作为外层查询的比较条件
From型子查询
把内层的查询结果供外层再次查询
注意:内层的查询结果看成临时表,加as临时表名
Exists型子查询
把外层的查询结果带入到内层,看内层是否成立。
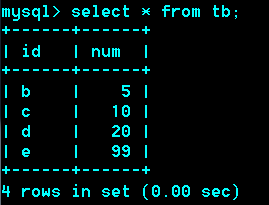
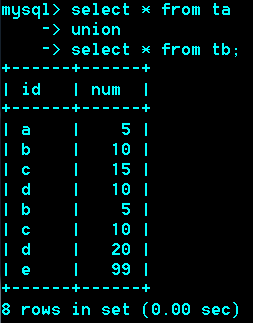
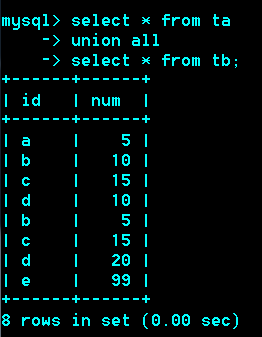
Union:联合
作用:把两次或多次查询结果合并

要求:两次查询的列数一致。
推荐:查询的每一列,相对应的列类型也一样。
可以来自于多张表。多条sql语句union后的列名以第一个sql语句的列名为准。
例:
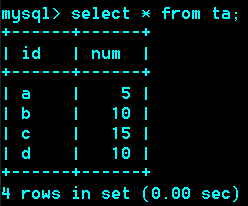
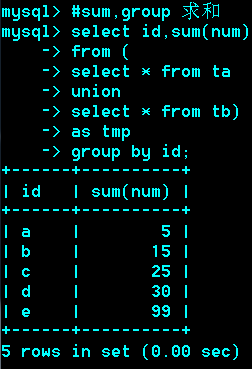
利用from型子查询,并配合sum聚合函数来实现。
如果不同的语句取出的行,有完全相同,(每个列的值都相同)
那么相同的行将会合并(去重复)
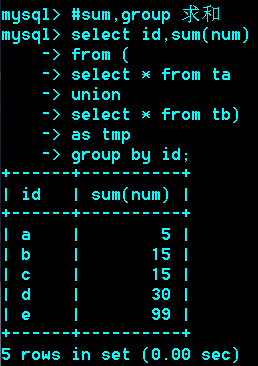
如果不去重复,可以加all。
如果子句中有order by,limit,需加()。
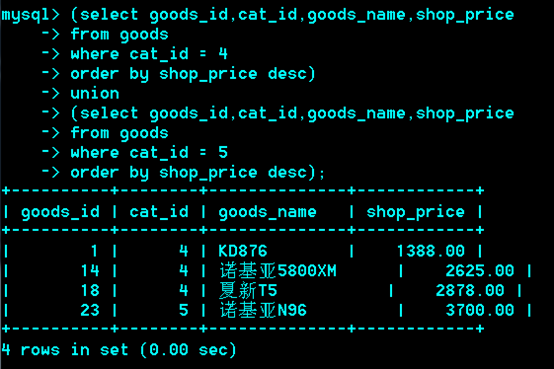
推荐排序放到所有子句之后,即对最终合并的结果进行排序。
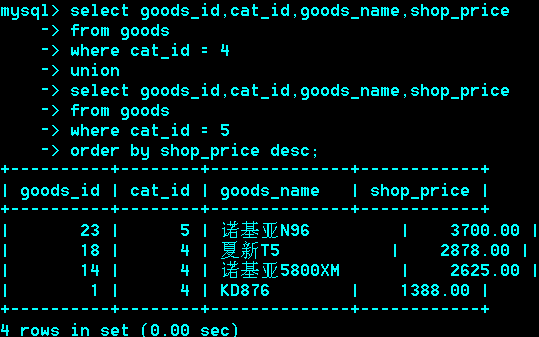
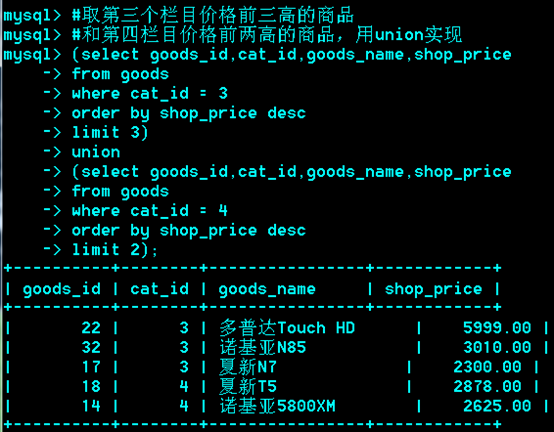
在子句中,order by 配合limit使用才有意义。不配合limit使用,会被语法分析器优化分析时,去除。
连接查询概念与左连接语法
子查询就是在原有的查询语句中,嵌入新的查询,来得到我们想要的结果集。一般根据子查询的嵌入位置分为,where型子查询,from型子查询。
学习内容
左连接,右连接,内连接
作用:
从两张或多张表中取出相关联的数据
应用案例:
非常广泛。如取文章及其所在栏目名称
去个人信息及其所发布的文章等。
数据库中以表为单位存储数据。

左连接

以左表为准,去右表找匹配数据,找不到匹配,用null补齐
右连接

内连接

如何记忆:
-
左右连接可以相互转化
-
推荐将右连接转化为左连接,兼容性好一些
-
内连接:查询左右表都有的数据,即:不要左右连接中null的那一部分,是左右连接的交集。
思考:能否查出左右连接的并集呢?
目前不能,目前的mysql不支持外连接。可以使用union来达到目的。
三表连接

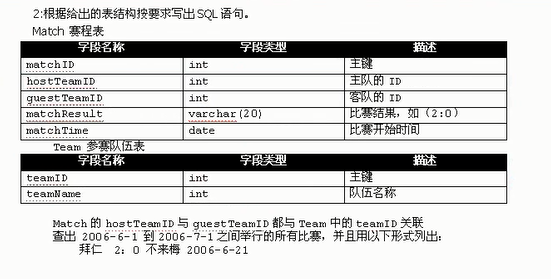
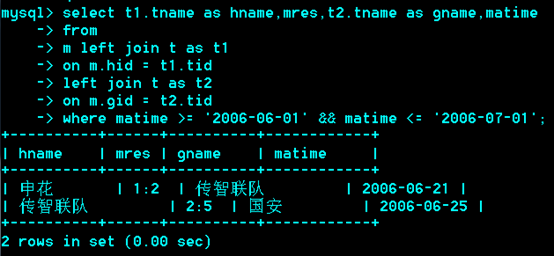
面试题:
回顾建表语句:
Create table 表名(
列名称 列类型[列属性][默认值],à列声明
列名称 列类型[列属性][默认值],
列名称 列类型[列属性][默认值],
列名称 列类型[列属性][默认值],
)charset = utf8/gbk…
表增加列,修改列,删除列
增加列:
Alter table 表名 add 列声明
增加的 列默认在表的最后一列
可以用after来声明新增的列在那一列后面。
After table 表名 add 列声明 after ..
如果新增放在最前面?
After table 表名 add 列声明 first
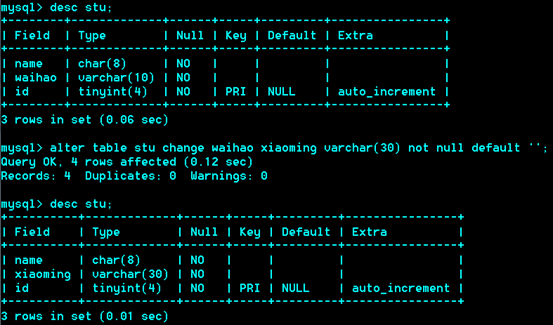
修改列:
After table 表名 change 旧列名 列声明
删除列:
Alter table 表名 drop 列名
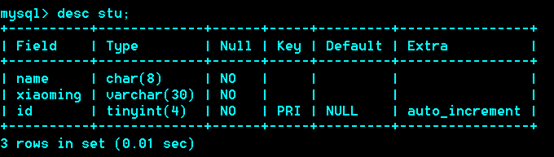
视图:view
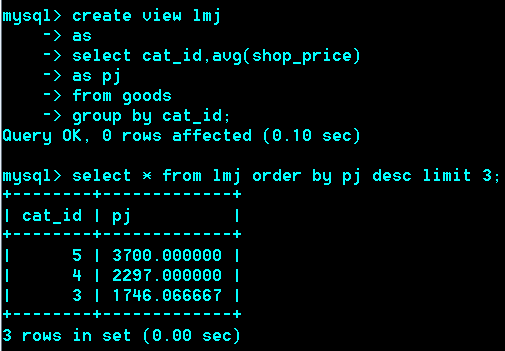
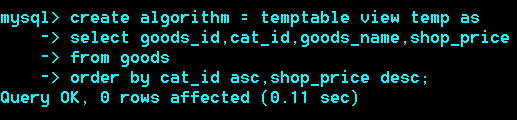
查询每个栏目下最贵的商品à
Select goods_id,goods_name,cat_id,shop_price from goods order by cat_id asc shop_price desc;
查询结果当成一张表看,
如果某个查询结果出现的非常频繁,也就是拿这个结果当作子查询出现的非常频繁
Create table g2 like goods;
Insert into g2 select……
上面两句是想保存一个查询结果到表里面,供其他查询用
视图的定义:
视图是有查询结果形成的一张虚拟表,
视图的创建语法:
Create view 视图名 select 语句;


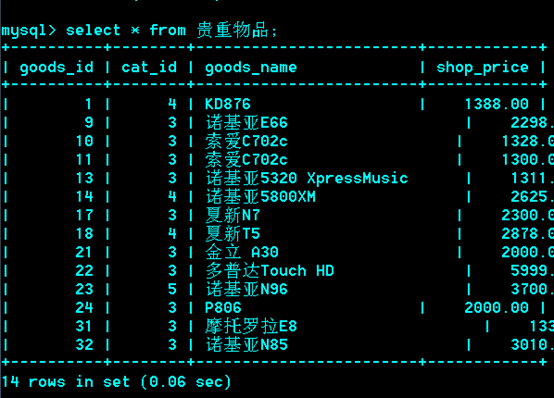
为什么要视图?
答:
-
可以简化查询,某一个复杂的查询,翻来覆去的查。
简化查询的例子:
-
进行权限控制
把表的权限封闭,但是开放相应的视图权限,视图里只开放部分数据。
-
大数据分表时可以用到
比如,表的行数超过200万时,就会变慢
可以把一张表的数据拆成四张表来存放
比如:News表
Newsid,1,2,3,4
News1,news2,news3,news4表
把一张表的数据分散到四张表里,分散的方法有很多,最常用的可以用id取模来计算(把数据均匀的分到几张表里)
Id%4+1 =[1,2,3,4]
比如$_GET['id'] = 17, 17%4+1 = 2,$tableName = 'news'.'2'
Select * from news2 where id =17;
还可以用视图,把四张表形成一张视图
Create view news as select from news2 union….
视图的删除:
Drop view;
视图的修改:
Alter view as select …
视图与表的关系:
视图的数据来源于表,若表的数据改变,则视图的数据自动改变。是表的查询结果。
修改视图的数据时,表的数据也会跟着修改。
但是视图也并不总是增删改的,视图的数据与表的数据有严格的一一对应时,可以修改。对于insert还应注意,视图必须包含表中没有默认值的列
视图的算法algorithm
Algorithm = merge/temptable/underfined
Merge:当引用视图时,引用视图的语句与定义视图的语句合并
Temptable:当引用视图时,根据视图的创建语句建立一个临时表
Underfined:未定义,
Merge意味着视图只是一个规则,语句规则,当查询视图时,把查询视图的语句与创建时的语句等合并,分析,形成一条语句。
而temptable是根据创建语句瞬间创建一张临时表,然后查询视图的语句从该临时表查数据。

字符集
字符集与校对集
Create table 表名(
列声明
)charset utf8;
mysql 的字符集设置非常灵活可以设置服务器默认字符集
数据库默认字符集
表默认字符集
列字符集
如果某一个级别没有指定字符集,则继承上一级,
以表声明utf8为例:
存储的数据在表中,最终是utf8;
- 告诉服务器,我发送的数据是什么编码的。character_set_client
- 告诉转换器,转换成什么编码的character_set_connection
- 查询的结果用什么编码character_set_results
如果以上三者都为字符集N,则可以简写为
Set names N;
推论:什么时候会乱码?
- Client声明与事实不符
- Result与客户端页面不符的时候
什么时间将会丢失数据?
校对集:字符集的排序规则
一个字符集可以有一个或者多个排序规则
Utf8默认utf8_general_ci不区分大小写
阶段总结(三)
Union的用法
合并查询的结果,取select结果的并集
对于重复的行去掉,如果不去重复,可以用union all
Union的要求:
各select查出的列数一致
如果子句中用了order by limit
那么子句要用小括号()抱起来
如果子句只用order by 没有limit
Orderby被优化掉,不起作用
左连接、右连接、内连接
Select ta.列,tb.列
Ta left/right/inner join tb
On ta.列 = tb.列 (关系不一定是等于)
Where…
左连接与右连接:
可以相互转化
A left b à b right a
内连接:inner join
左右连接的交集,两张表能相互匹配上的行
表的管理à列的增删改
给表增加列:
Alter table 表名add 列声明[after/first]
修改表的列:
Alter table 表名 change 待修改列名 列声明
删除别的列:
Alter table 表名 drop 列名
视图 view
视图是一张虚拟的表,没有真实的数据存在,只是一张与表的一种查询产生的关系。
语法:
Create [algorithm = merge/temptable/underfined] view viewname as select…..;
Merge是将创建视图时的语句和查询视图的语句合并成一条语句。
Temptable:是创建一张临时表,merge是一条语句,用的时候较多。
字符集和校对集
客户端—》【转换器】--》服务器
客户端使用的字符集:set character_set_client = gbk/utf8
转换器转换后的字符集:set character_set_connection = gbk/utf8
返回给客户端的字符集:set character_set_results = gbk/utf8
总和:set names gbk/utf8;
校对集:就是对排序的规则;
一种字符集对应一种或多种校对集;
Create table()charset utf8;
触发器:
学习目标:
触发器的定义:
触发器的应用场合:
掌握触发器的创建语法:
会创建简单的触发器:
- 触发器:trigger,(枪击,扳机,引线)见识某种情况,并触发某种操作。能监视增删改,触发操作:增删改
-
当向一张表中添加或删除记录时,需要在相关表中进行同步操作。比如:当一个订单产生时,订单所购的商品的库存量相应减少。
当表上某列数据的值与其他表中的数据有联系时。
比如:当某客户进行欠款消费,可以在生成订单时通过设计触发器判断该客户的累计欠款是否超过了最大限度。
当需要对某张表进行跟踪时。
比如:当有新订单产生时,需要及时通知相关人员进行处理,此时可以在订单表上设计添加触发器加以实现。
-
监视地点:table,监视事件:insert/update/delete,触发时间:after/before,触发事件:insert/update/delete
首先需要修改:
Delimiter $,遇到$结束语句开始执行。
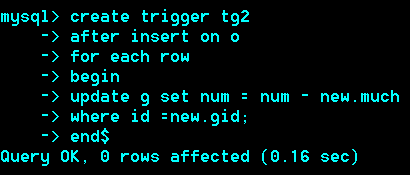
创建触发器语法:
Create trigger triggerName
After/before insert/update/delete on 表名
For each row
Begin
Sql语句
End
删除触发器的语法:
Drop trigger triggerName
如何在触发器中引用行的值,
对于insert而言,新增的行用new来表示,行中的每一列的值,用new.列名来表示。
对于delete来说,原本有一行,后来被删除想引用被删除的这一行,用old来表示,old列名就可以引用被删行中的值。
对于update来说,原本有一行,修改后还是那一行,修改前的数据用old来表示,old列名引用被修改之前行中的值,修改后的数据用new来表示,new列名引用被修改之前前行中的值,
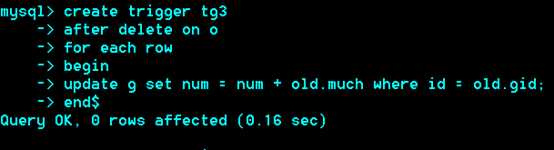
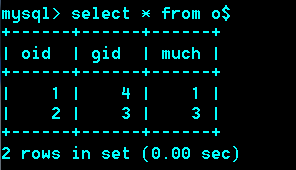
例:

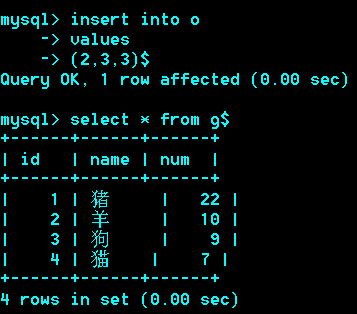
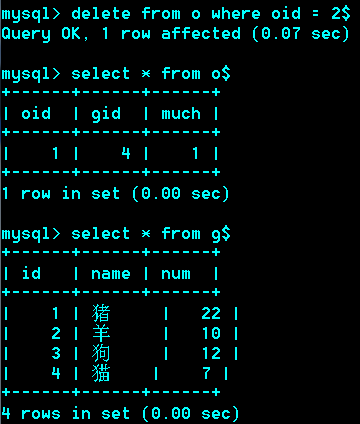
删除一个订单,库存量相应增加

修改订单的数量时,库存相应改变
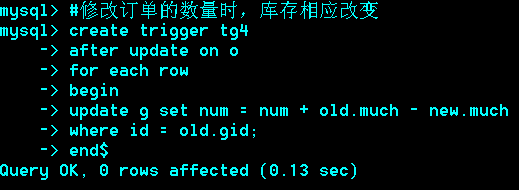
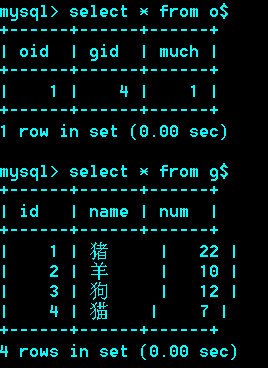
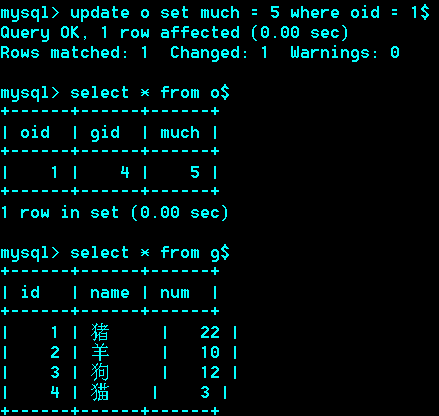
这里只是修改了订单的数量,若也要修改gid,即订单商品类别,则需要修改触发器:

触发器里after和before的区别
After是先完成数据的增删改,再触发,触发中的语句晚于增删改,不能对前面的增删改产生影响
Before是先完成触发,再增删改,触发的语句先于监视增删改,我们有机会判断,修改即将发生的操作
典型案例:
对于所下订单进行判断,如果订单数量>5就是认为恶意订单,强制把所订的商品数量改成5
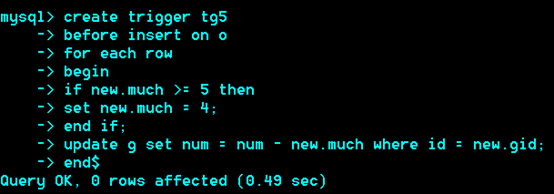
查看所有的触发器
Show triggers;
存储引擎
表里的数据存储在硬盘上,具体是如何存储的?
存储的方式有很多,同样的一张表的数据对于用户来说,无论什么样的存储引擎,用户看到的数据是一样的,对于服务器来说是不同的。
数据库对同样的数据,有不同的存储方式和管理方式,在mysql中,称为存储引擎。
常用的表的引擎有myisam和innodb
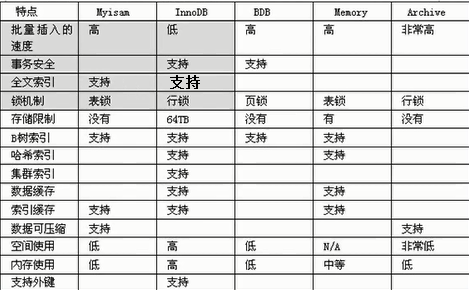
Myisam:批量插入速度快,不支持事务,锁表
innoDB:批量插入速度相对较慢,支持事务,锁行。
全文索引,目前mysql5.5都已经支持。
讨论innoDB支持事务,myisam不支持事务。
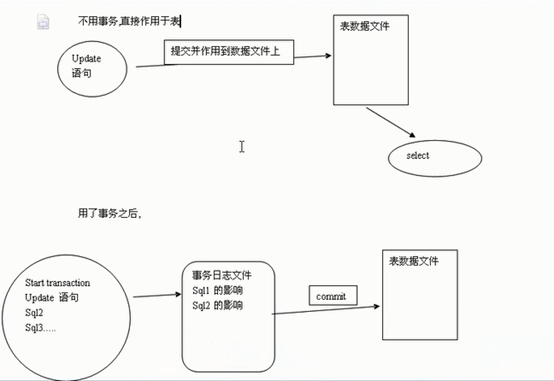
事务:
事务的acid特性
通俗的说,一组操作要么都成功执行,要么都不执行。à原子性(atomicity)
在所有操作都没有执行完毕之前,其他会话不能够看到中间改变的过程。à隔离性(isolation)
事务发生之前和发生之后数据的总额依然匹配。à一致性(consistency)
事务产生的影响不能够撤销à持久性(durability)
如果出现了错误,事务也不允许撤销,只能够"补偿事务"
原子性体现的是不可分割性,不可见性。
转账
李三 à支出500,李三-500
赵四 à收到500,赵四+500
关于事务的引擎:选用innoDB/bdb
查看mysql 服务器的模式:
Show variables like 'zmodez';
语法:
开启事务:

Sql…
Sql…
Commit提交/rollback回滚
注意:当一个事务commit或者roolback之后,事务就已经结束。
只要事务没有提交或回滚,事务处理都会看不见.

事物的基本原理(了解)
数据库的备份和恢复

Mysql索引
设有N条随机记录,不用索引,平均查找N/2次,那么用了索引之后?
Btree索引,Log2N
Hash索引,1
索引与优化之索引的好处与坏处
好处:加快了查询速度
坏处:降低了增删改的速度
增大了表的文件大小(索引文件甚至可能比数据文件还大)
大数据量导入时,应先去掉索引,再导入,最后统一加索引。
索引的使用原则:
不过度索引、索引条件列(where后面最频繁的条件比较适合索引)、索引散列值,过于集中的值不要索引。例如:给性别男女加索引意义不大。
索引类型:普通索引,主键索引,唯一索引,全文索引。
.frm是结构文件
.myd是数据文件
.myi是索引文件
索引文件比数据文件大是一种很常见的事情
- 普通索引 index 仅仅是加快查询速度
- 唯一索引 unique index行上的值不能重复
- 主键索引 primary key不能重复,主键索引必唯一,但是唯一索引不一定是主键,一张表上只能有一个主键,但是可以用一个或者多个索引。
-
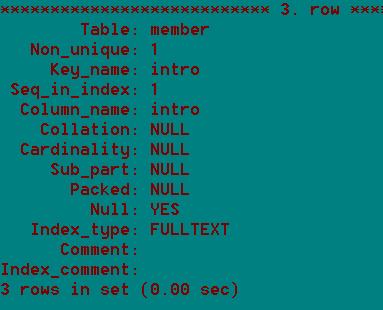
全文索引:fulltext index
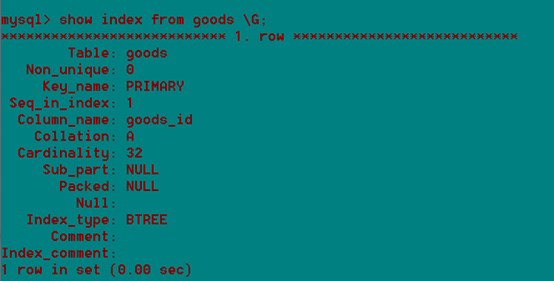
查看一张表上的所有索引:
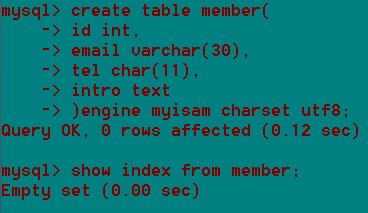
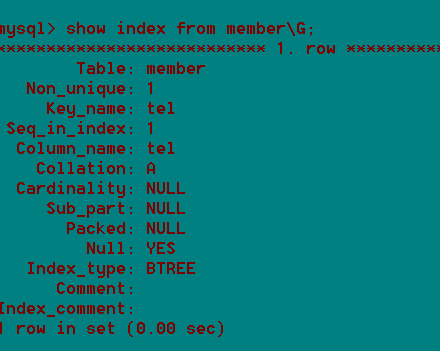
Show index from 表名;
建立索引:(索引名和索引在哪个列上发挥作用)
Alter table 表名 add index/unique/fulltext[索引名](列名);

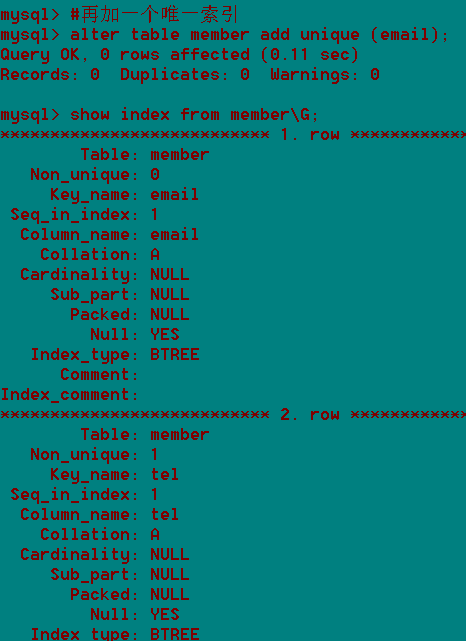

主键索引有一点区别:
Alter table 表名 primary key (列名);

删除索引:
Alter table 表名 drop index 索引名;


索引是根据数据建立的目录。
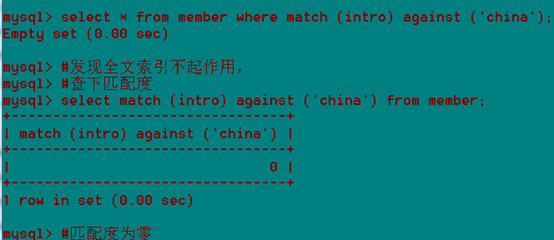
全文索引在mysql的默认情况下,对中文的意义不大。
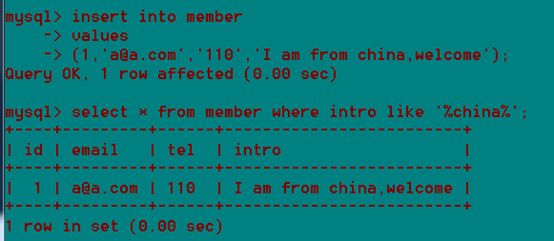
这么查是一行一行查,效率低。针对每一个单词建立一个索引,
停止词的问题:(一会讲)
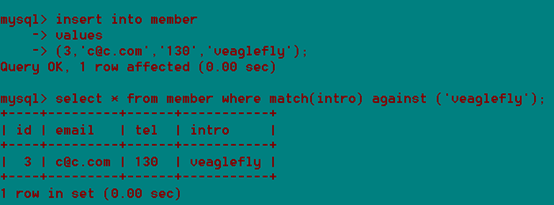
停止词是种非常常见的词,是不会加索引的。
关于全文索引的用法:
Match(全文索引名)against('keyword');
关于全文索引的停止词:
全文索引不针对非常频繁的词做索引,如,this,is等
全文索引对中文的意义不大因为英文有空格,标点符号来拆成单词,进而对单词进行索引,而对于中文,没有空格来隔开单词mysql无法识别每个中文词。
存储过程:
类似于函数,就是把一段代码封装起来,当要执行这一段代码时
可以调用该存储过程来实现。
在封装语句体里面,可以用if/else,case,while
等控制结构,可以进行sql编程。
查看现有的存储过程
Show procedure status
删除存储过程
Drop procedure 存储过程的名字
调用存储过程
Call 存储过程的名字();(括号内可以放参数)
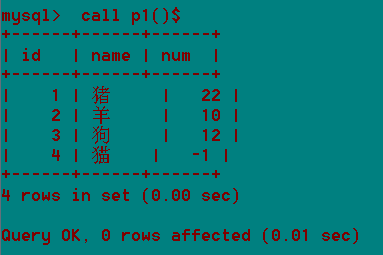
第一个存储过程,体会封装sql的用法。

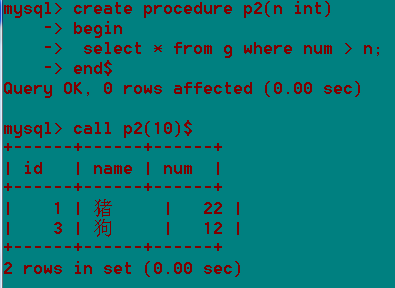
第二个存储过程,体会控制结构。
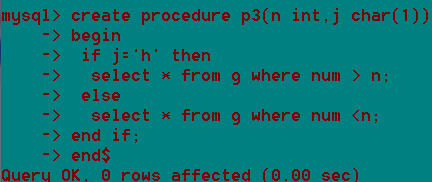

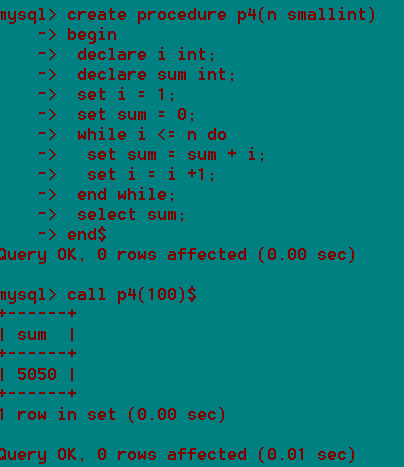
在mysql中,存储过程和函数的区别:
一是名称不同
二是存储过程没有返回值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号