
基于pytorch实现word2vec
一、介绍
- word2vec是Google于2013年推出的开源的获取词向量word2vec的工具包。它包括了一组用于word embedding的模型,这些模型通常都是用浅层(两层)神经网络训练词向量。
- Word2vec的模型以大规模语料库作为输入,然后生成一个向量空间(通常为几百维)。词典中的每个词都对应了向量空间中的一个独一的向量,而且语料库中拥有共同上下文的词映射到向量空间中的距离会更近。
- word2vec目前普遍使用的是Google2013年发布的C语言版本,现在也有Java、C++、python版本的实现,但是从效果和速度上还是C的更胜一筹,速度很快。
二、Word2Vec中的两种模型、两种加速方法
1、CBOW model 和 Skip-Gram model
- CBOW 是 Continuous Bag-of-Words Model 的缩写,CBOW是通过上下文预测中间词的模型
- Skip-Gram model与CBOW正好相反,是通过中间词来预测上下文,一般可以认为位置距离接近的词之间的联系要比位置距离较远的词的联系紧密。两种model如下图所示。
![]()

2、Hierarchical Softmax 和 Negative sampling
-
Negative sampling:负采样,目的是减少分母的规模,随机采样几个词,仅计算这几个词和预测词的分类问题,这样就将一个规模庞大的多元分类转换成了几个二分类问题。负采样用在Skip-Gram model上就是增加共线的词对出现的频率,而负采样不出现的额词随机抽样,降低他们的概率。
-
Hierarchical Softmax:层次化Softmax,将所有的词放在树的叶子节点上,构造Huffman树,使⽤哈夫曼编码,将计算复杂度较⾼的Softmax过程转化为多次⼆元分类任
务 。 -
![]()

三、Code 和 测试
1、Code
- 地址:https://github.com/bamtercelboo/pytorch_word2vec
- 目前的demo简单的实现了Skip-Gram + Hierarchical Softmax 、Skip-Gram + Negative sampling、CBOW + Hierarchical Softmax、CBOW + Negative sampling四种方法。
2、测试
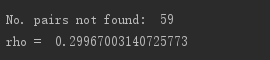
- 测试是基于C版本的Word2vec跑出来的词向量与pytorch跑出来的词向量进行了简单的测试,当然两种都是在相同模型以及相同方法上的测试。
- 评分测试:C版本与pytorch版本的测试结果很接近(结果很低,是因为语料不是很大)
- 测试结果说明,pytortch跑出来的词向量效果和C版本跑出来的词向量版本效果是相近的,但是在速度方面C明显高于pytorch。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号