Python内置模块(hashlib模块、ligging模块)与第三方模块
Python内置模块(hashlib模块、ligging模块)与第三方模块
- hashlib模块
- hashlib模块详细操作
- logging日志模块
- 日志模块详细介绍
- 日志模块配置字典
- 第三方模块
一、hashlib模块
加密:将明文数据通过一系列算法变成密文数据(目的是为了数据的安全)
加密算法:md系列、sha系列、base系列、hmac系列
基本使用
import hashlib # 1.先确定算法类型(md5普遍使用) md5 = hashlib.md5() # 2.将明文数据传递给md5算法(update只能接受bytes类型数据) # md5.update('123'.encode('utf8')) md5.update(b'123') # 3.获取加密之后的密文数据(没有规则的一串随机字符串) res = md5.hexdigest() print(res)
加密之后的密文数据是没有办法反解密成明文数据的
市面上所谓的破解其实就是提前算出一系列明文对应的密文之后对比密文再获取明文
二、hashlib模块详细操作
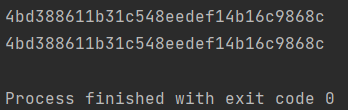
1. 明文数据只要是相同的,那么无论如何传递和加密结果肯定是一样的
import hashlib # 1.先确定算法类型(md5普遍使用) md5 = hashlib.md5() # 2.将明文数据传递给md5算法(update只能接受bytes类型数据) md5.update(b'hellojason123') res = md5.hexdigest() print(res) md5 = hashlib.md5() md5.update(b'hello') md5.update(b'jason') md5.update(b'123') # 3.获取加密之后的密文数据(没有规则的一串随机字符串) res = md5.hexdigest() print(res)
2. 密文数据越长表示内部对应的算法越复杂,越难被正向破解
import hashlib # 1.先确定算法类型(md5普遍使用) md5 = hashlib.sha256() # 2.将明文数据传递给md5算法(update只能接受bytes类型数据) md5.update(b'hello') md5.update(b'jason') md5.update(b'123') # 3.获取加密之后的密文数据(没有规则的一串随机字符串) res = md5.hexdigest() print(res)

密文越长表示算法越复杂,对应的破解算法的难度越高
但是越复杂的算法所需要消耗的资源也就越多,密文越长基于网络发送需要占据的数据也就越大
具体使用什么算法取决于项目的要求,一般情况下md5足够了
3. 涉及到用户密码存储其实都是密文,只有用户自己知道密文是什么
这样做的优点是:
1)内部程序员无法得知明文数据
2)数据泄露也无法得知明文数据
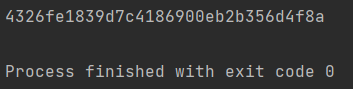
4. 加盐处理
在对明文数据做加密处理的过程前添加一些干扰项
import hashlib # 1.先确定算法类型(md5普遍使用) md5 = hashlib.md5() # 2.将明文数据传递给md5算法(update只能接受bytes类型数据) # 加盐(干扰项) md5.update('公司内部自己定义的盐'.encode('utf8')) # 真实数据 md5.update(b'hellojason123') # 3.获取加密之后的密文数据(没有规则的一串随机字符串) res = md5.hexdigest() print(res)
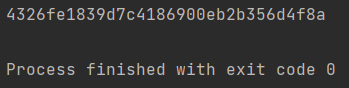
5. 动态加盐
import hashlib import time # 1.先确定算法类型(md5普遍使用) md5 = hashlib.md5() # 2.将明文数据传递给md5算法(update只能接受bytes类型数据) # 动态加盐(干扰项) 当前时间 用户名的部分 uuid(随机字符串(永远不会重复)) res1 = str(time.time()) md5.update(res1.encode('utf8')) # 真实数据 md5.update(b'hellojason123') # 3.获取加密之后的密文数据(没有规则的一串随机字符串) res = md5.hexdigest() print(res)
在IT互联网领域,没有绝对的安全可言,只有更安全
原因在于互联网的本质就是通过网线(网卡)连接计算机
6. 校验文件一致性
将文件做加密处理,与用户下载的文件做加密处理后进行对比
文件不是很大的情况下,可以将所有文件内部全部加密处理
但是如果文件特别大,全部加密处理相当的耗费资源
所以针对大文件可以使用切片读取的方式
import hashlib md5 = hashlib.md5() with open(r'a.txt', 'rb') as f: for line in f: md5.update(line) real_data = md5.hexdigest() print(real_data) md5 = hashlib.md5() with open(r'a.txt', 'rb') as f: for line in f: md5.update(line) error_data = md5.hexdigest() print(error_data) import os # 读取文件总大小 res = os.path.getsize(r'a.txt') # 指定分片读取策略(读几段 每段几个字节) 10 f.seek() read_method = [0, res // 4, res // 2, res]
比特流技术、断点续传技术
三、logging日志模块
知识点很多,但是需要掌握的很少(会用即可)
1. 日志有五个等级(从上往下重要程度不一样)
import logging logging.debug('debug级别') # 10 logging.info('info级别') # 20 logging.warning('warning级别') # 30 logging.error('error级别') # 40 logging.critical('critical级别') # 50
默认记录的级别在30及以上
2. 简单使用
import logging file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf-8', ) logging.basicConfig( format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', handlers=[file_handler, ], level=logging.ERROR ) logging.error('这是日志')

3. 日志模块详细介绍
1)如何控制日志输出位置?
例如在文件和终端中同时打印
2)不同位置如何做到不同日志格式
例如在文件中详细一些,在终端中简单一些
import logging # 1.logger对象:负责产生日志 logger = logging.getLogger('转账记录') # 2.filter对象:负责过滤日志(直接忽略) # 3.handler对象:负责日志产生的位置 hd1 = logging.FileHandler('a1.log', encoding='utf8') # 产生到文件的 hd2 = logging.FileHandler('a2.log', encoding='utf8') # 产生到文件的 hd3 = logging.StreamHandler() # 产生在终端的 # 4.formatter对象:负责日志的格式 fm1 = logging.Formatter( fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', ) fm2 = logging.Formatter( fmt='%(asctime)s - %(name)s %(message)s', datefmt='%Y-%m-%d', ) # 5.绑定handler对象 logger.addHandler(hd1) logger.addHandler(hd2) logger.addHandler(hd3) # 6.绑定formatter对象 hd1.setFormatter(fm1) hd2.setFormatter(fm2) hd3.setFormatter(fm1) # 7.设置日志等级 logger.setLevel(10) # 8.记录日志 logger.debug('这是日志')
四、日志模块配置字典
# 核心就在于CV import logging import logging.config standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \ '[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' logfile_path = 'a3.log' # log配置字典 LOGGING_DIC = { 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'standard': { 'format': standard_format }, 'simple': { 'format': simple_format }, }, 'filters': {}, # 过滤日志 'handlers': { #打印到终端的日志 'console': { 'level': 'DEBUG', 'class': 'logging.StreamHandler', # 打印到屏幕 'formatter': 'simple' }, #打印到文件的日志,收集info及以上的日志 'default': { 'level': 'DEBUG', 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件 'formatter': 'standard', 'filename': logfile_path, # 日志文件 'maxBytes': 1024*1024*5, # 日志大小 5M 'backupCount': 5, 'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了 }, }, 'loggers': { #logging.getLogger(__name__)拿到的logger配置 空字符串作为键 能够兼容所有的日志 '': { 'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 'level': 'DEBUG', 'propagate': True, # 向上(更高level的logger)传递 }, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置 }, } # 使用配置字典 logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置 logger1 = logging.getLogger('xxx') logger1.debug('好好的 不要浮躁 努力就有收获')
五、第三方模块
第三方模块并不是python自带的,需要基于网络下载!!!
pip所在的路径需要添加环境变量
1. 下载第三方模块的方式1:
命令行借助于pip工具
pip3 install 模块名 # 不知道版本默认是最新版 pip3 install 模块名==版本号 # 指定版本下载 pip3 install 模块名 -i 仓库地址 # 临时切换
命令行形式永久修改需要修改python解释器源文件
2. 下载第三方模块的方式2:
pycharm快捷方式
File >>> settings >>> project >>> project interprter >>> 双击或者点击加号
点击左下方的manage管理添加源地址即可
下载完第三方模块之后,还是使用 import 或 from...import... 句式导入使用
3. 第三方模块下载地址
pip命令默认下载的渠道是国外的python官网(有时候会非常的慢)
我们可以切换下载的源(仓库)
(1)阿里云 http://mirrors.aliyun.com/pypi/simple/ (2)豆瓣 http://pypi.douban.com/simple/ (3)清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/ (4)中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/ (5)华中科技大学http://pypi.hustunique.com/ pip3 install openpyxl -i http://mirrors.aliyun.com/pypi/simple/
4. 下载第三方模块可能报错的情况及解决措施
1)报错的提示信息中含有关键字timeout
原因:网络不稳定
措施:再次尝试 或者切换更加稳定的网络
2)找不到pip命令
环境变量问题
3)没有任何的关键字 不同的模块报不同的错
原因:模块需要特定的计算机环境
措施:拷贝报错信息 打开浏览器 百度搜索即可
pip下载某个模块报错错误信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号