如何用python解析mysqldump文件
一、前言
最近在做离线数据导入HBase项目,涉及将存储在Mysql中的历史数据通过bulkload的方式导入HBase。由于源数据已经不在DB中,而是以文件形式存储在机器磁盘,此文件是mysqldump导出的格式。如何将mysqldump格式的文件转换成实际的数据文件提供给bulkload作转换,是需要考虑的一个问题。
二、思路
我们知道mysqldump导出的文件主要是Insert,数据库表结构定义语句。而要解析的对象也主要是包含INSERT关键字记录,这样我们就把问题转换成如何从dmp文件解析Insert语句。接触过dmp文件的同学应该了解,其INSERT语句的结构,主要包含表名、字段名、字段值, 这里面主要包含几个关键字:INSERT INTO, VALUES。我们要做的就是把Values括号后的字段值给解析出来,这个过程需要考虑VALUES后面包含的是多少行的记录,有可能导出的记录Values后面包含多行对应mysql中存储的记录。
在解析文件过程中,我自然想到用Python来写,因为Python在处理文件方面有很多优势,也比较简单。在处理DMP文件这块,考虑到字段值间是用逗号分割的,在python中正好一个模块可以很好的来处理此类格式 ,即大家很熟悉的CSV模块,在处理CSV类型的文件有很多优势。在这里我们把CSV模块有在解析dmp文件,同时加一些解析逻辑,可以很好解决此类问题。
同时,我们要处理的dmp文件是经过压缩的,并且单个文件都比较大,都是Gigbytes的,在读取时需要注意机器内存大小,不能一次读出所有的数据,python也考虑到此类问题,采用的方法是惰性取值,即在真正使用时才从磁盘中加载相应的文件数据。如果想加块解析,还可以采集多进程或多线程的方法。
三、方法
处理流程图如下所示:
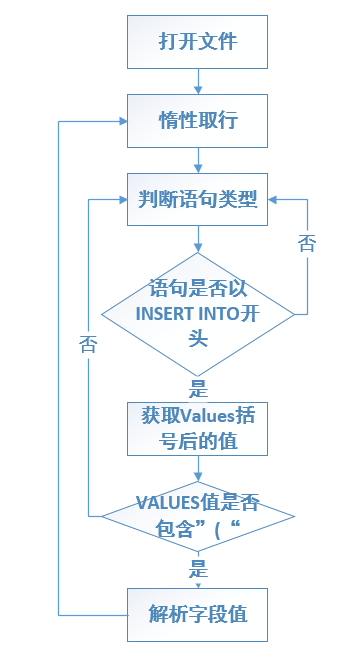
代码如下图所示:


1 #!/usr/bin/env python 2 import fileinput 3 import csv 4 import sys 5 import gzip 6 7 8 # 设定CSV读取的最大容量 9 csv.field_size_limit(sys.maxsize) 10 11 def check_insert(line): 12 """ 13 返回语句是否以insert into开头,如果是返回true,否则返回false 14 """ 15 return line.startswith('INSERT INTO') or False 16 17 18 def get_line_values(line): 19 """ 20 返回Insert语句中包含Values的部分 21 """ 22 return line.partition('VALUES ')[2] 23 24 25 def check_values_style(values): 26 """ 27 保证INSERT语句满足基本的条件,即包含(右括号 28 """ 29 30 if values and values[0] == '(': 31 return True 32 return False 33 34 def parse_line(values): 35 """ 36 创建csv对象,读取INSERT VALUES 字段值 37 """ 38 latest_row = [] 39 40 reader = csv.reader([values], delimiter=',', 41 doublequote=False, 42 escapechar='\\', 43 quotechar="'", 44 strict=True 45 ) 46 47 48 for reader_row in reader: 49 for column in reader_row: 50 # 判断字段值是否为空或为NULL 51 if len(column) == 0 or column == 'NULL': 52 latest_row.append("") 53 continue 54 55 # 判断字段开头是否以(开头,如果是则说明此VALUES后面不只包含一行数据,可能有多行,要分别解析 56 if column[0] == "(": 57 new_row = False 58 if len(latest_row) > 0: 59 #判断行是否包含),如果包含则说明一行数据完毕 60 if latest_row[-1][-1] == ")": 61 # 移除) 62 latest_row[-1] = latest_row[-1][:-1] 63 if latest_row[-1] == "NULL": 64 latest_row[-1] = "" 65 new_row = True 66 # 如果是新行,则打印该行 67 if new_row: 68 line="}}}{{{".join(latest_row) 69 print "%s<{||}>" % line 70 latest_row = [] 71 72 if len(latest_row) == 0: 73 column = column[1:] 74 75 latest_row.append(column) 76 # 判断行结束符 77 if latest_row[-1][-2:] == ");": 78 latest_row[-1] = latest_row[-1][:-2] 79 if latest_row[-1] == "NULL": 80 latest_row[-1] = "" 81 82 line="}}}{{{".join(latest_row) 83 print "%s<{||}>" % line 84 85 def main(): 86 87 filename=sys.argv[1] 88 try: 89 #惰性取行 90 with gzip.open(filename,"rb") as f: 91 for line in f: 92 if check_insert(line): 93 values = get_line_values(line) 94 if check_values_style(values): 95 parse_line(values) 96 except KeyboardInterrupt: 97 sys.exit(0) 98 99 if __name__ == "__main__": 100 main()
四、总结
总的说来,主要是利用Python的CSV模块来解析DMP文件的INSERT语句,如果DMP文件不规整,可能还是有些问题。对于dmp文件很大情况,也是需要考虑解析时间效率问题,可以考虑增加多进程或多线程机制。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号