
分布式id
一 数据库主键自增
这种方式就比较简单直白了,就是通过关系型数据库的自增主键产生来唯一的 ID。
- 优点:实现起来比较简单、ID 有序递增、存储消耗空间小
- 缺点:支持的并发量不大、存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )、每次获取 ID 都要访问一次数据库(增加了对数据库的压力,获取速度也慢)
二 数据库号段自增
数据库主键自增这种模式,每次获取 ID 都要访问一次数据库,ID 需求比较大的时候,肯定是不行的。
如果我们可以批量获取,然后存在在内存里面,需要用到的时候,直接从内存里面拿就舒服了!这也就是我们说的 基于数据库的号段模式来生成分布式 ID。
数据库的号段模式也是目前比较主流的一种分布式 ID 生成方式。像滴滴开源的Tinyid就是基于这种方式来做的。不过,TinyId 使用了双号段缓存、增加多 db 支持等方式来进一步优化。
相比于数据库主键自增的方式,数据库的号段模式对于数据库的访问次数更少,数据库压力更小。
另外,为了避免单点问题,你可以从使用主从模式来提高可用性。
数据库号段模式的优缺点:
- 优点:ID 有序递增、存储消耗空间小
- 缺点:存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )
三 NOSQL(redis)
一般情况下,NoSQL 方案使用 Redis 多一些。我们通过 Redis 的 incr 命令即可实现对 id 原子顺序递增。
Redis 方案的优缺点:
- 优点:性能不错并且生成的 ID 是有序递增的
- 缺点:和数据库主键自增方案的缺点类似
四 UUID
UUID 是 Universally Unique Identifier(通用唯一标识符) 的缩写。UUID 包含 32 个 16 进制数字(8-4-4-4-12)。
JDK 就提供了现成的生成 UUID 的方法,一行代码就行了。
//输出示例:cb4a9ede-fa5e-4585-b9bb-d60bce986eaa UUID.randomUUID()
UUID 可以保证唯一性,因为其生成规则包括 MAC 地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素,计算机基于这些规则生成的 UUID 是肯定不会重复的。
虽然,UUID 可以做到全局唯一性,但是,我们一般很少会使用它。
比如使用 UUID 作为 MySQL 数据库主键的时候就非常不合适:
- 数据库主键要尽量越短越好,而 UUID 的消耗的存储空间比较大(32 个字符串,128 位)。
- UUID 是无顺序的,InnoDB 引擎下,数据库主键的无序性会严重影响数据库性能。
最后,我们再简单分析一下 UUID 的优缺点 (面试的时候可能会被问到的哦!) :
- 优点:生成速度比较快、简单易用
- 缺点:存储消耗空间大(32 个字符串,128 位)、 不安全(基于 MAC 地址生成 UUID 的算法会造成 MAC 地址泄露)、无序(非自增)、没有具体业务含义、需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID)
五 snowflake算法组成
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。
最高位是符号位,始终为0,不可用。
41位的时间序列,精确到毫秒级,41位的长度可以使用69年。时间位还有一个很重要的作用是可以根据时间进行排序。
10位的机器标识,10位的长度最多支持部署1024个节点。
12位的计数序列号,序列号即一系列的自增id,可以支持同一节点同一毫秒生成多个ID序号,12位的计数序列号支持每个节点每毫秒产生4096个ID序号。
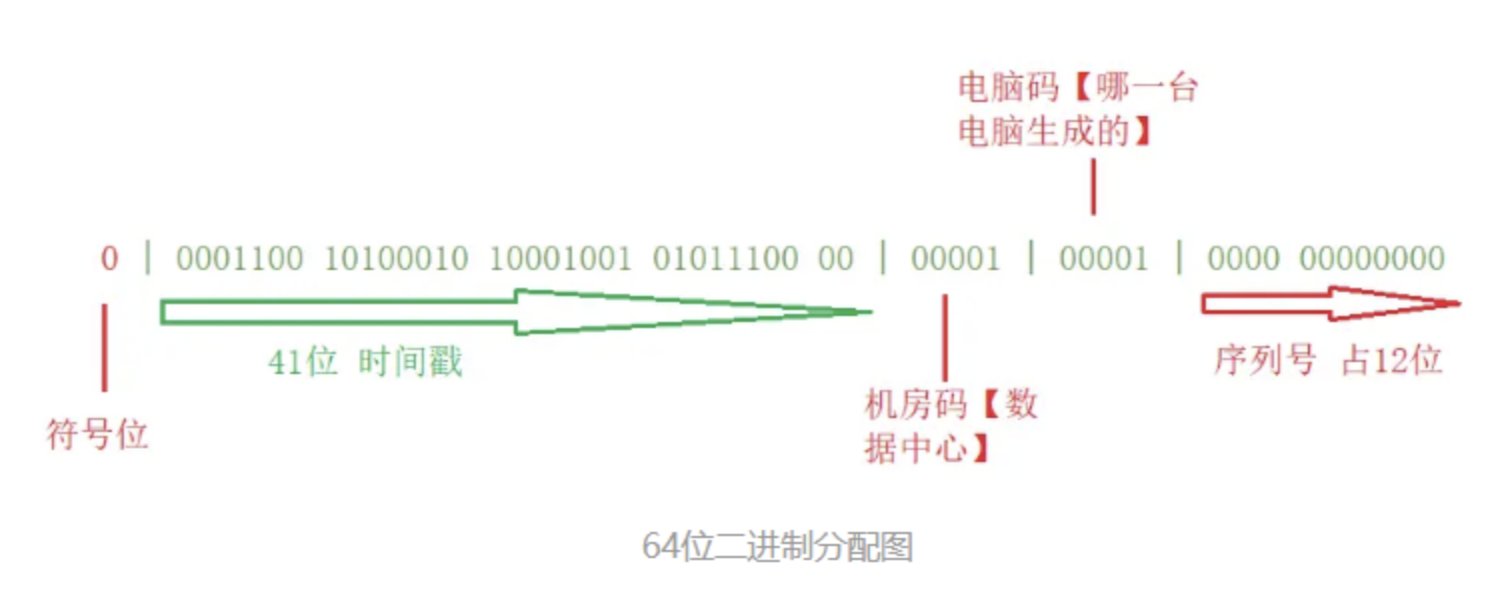

总结: 雪花算法组成结构大致分为了无效位、时间位、机器位和序列号位。其特点是自增、有序、纯数字组成查询效率高且不依赖于数据库。适合在分布式的场景中应用,可根据需求调整具体实现细节。
我们再来看看 Snowflake 算法的优缺点:
- 优点:生成速度比较快、生成的 ID 有序递增、比较灵活(可以对 Snowflake 算法进行简单的改造比如加入业务 ID)
- 缺点:需要解决重复 ID 问题(ID 生成依赖时间,在获取时间的时候,可能会出现时间回拨的问题,也就是服务器上的时间突然倒退到之前的时间,进而导致会产生重复 ID)、依赖机器 ID 对分布式环境不友好(当需要自动启停或增减机器时,固定的机器 ID 可能不够灵活)。
如果你想要使用 Snowflake 算法的话,一般不需要你自己再造轮子。有很多基于 Snowflake 算法的开源实现比如美团 的 Leaf、百度的 UidGenerator(后面会提到),并且这些开源实现对原有的 Snowflake 算法进行了优化,性能更优秀,还解决了 Snowflake 算法的时间回拨问题和依赖机器 ID 的问题。
项目中如何生成一个单据号
20181024-日期
0 - 弹性标识为master
4 - 新平台
099 - 写死的系统标识
00000000 - 8位扩展码
21 分库分表位
00 - 弹性管控位
12345678 - 8位随机sequece
六 衍生问题1 - traceId
6.1 日志跟踪
在分布式服务架构下,一个 Web 请求从网关流入,有可能会调用多个服务对请求进行处理,拿到最终结果。这个过程中每个服务之间的通信又是单独的网络请求,无论请求经过的哪个服务出了故障或者处理过慢都会对前端造成影响。
处理一个 Web 请求要调用的多个服务,为了能更方便的查询哪个环节的服务出现了问题,现在常用的解决方案是为整个系统引入分布式链路跟踪。
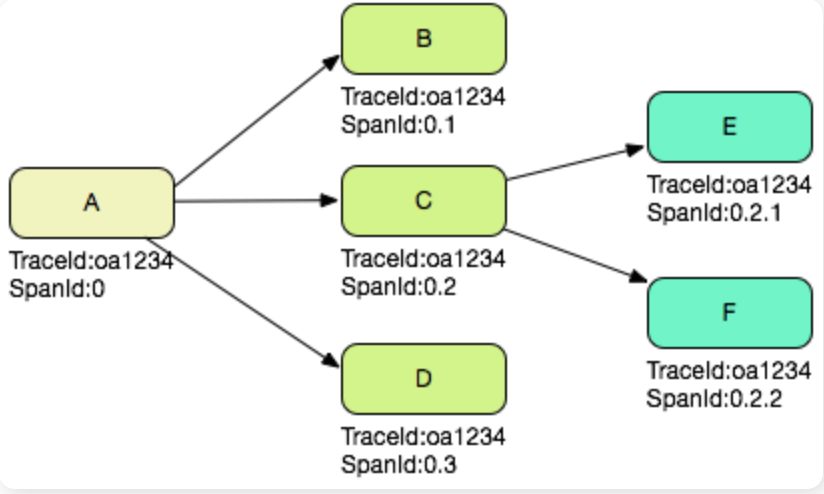
在分布式链路跟踪中有两个重要的概念:跟踪(trace)和 跨度( span)。trace 是请求在分布式系统中的整个链路视图,span 则代表整个链路中不同服务内部的视图,span 组合在一起就是整个 trace 的视图。
在整个请求的调用链中,请求会一直携带 traceid 往下游服务传递,每个服务内部也会生成自己的 spanid 用于生成自己的内部调用视图,并和 traceid 一起传递给下游服务。
6.2 TraceId 生成规则
这种场景下,生成的 ID 除了要求唯一之外,还要求生成的效率高、吞吐量大。traceid 需要具备接入层的服务器实例自主生成的能力,如果每个 trace 中的 ID 都需要请求公共的 ID 服务生成,纯纯的浪费网络带宽资源。且会阻塞用户请求向下游传递,响应耗时上升,增加了没必要的风险。所以需要服务器实例最好可以自行计算 tracid,spanid,避免依赖外部服务。
产生规则:服务器 IP + ID 产生的时间 + 自增序列 + 当前进程号 ,比如:
0ad1348f1403169275002100356696
前 8 位 0ad1348f 即产生 TraceId 的机器的 IP,这是一个十六进制的数字,每两位代表 IP 中的一段,我们把这个数字,按每两位转成 10 进制即可得到常见的 IP 地址表示方式 10.209.52.143,您也可以根据这个规律来查找到请求经过的第一个服务器。
后面的 13 位 1403169275002 是产生 TraceId 的时间。之后的 4 位 1003 是一个自增的序列,从 1000 涨到 9000,到达 9000 后回到 1000 再开始往上涨。最后的 5 位 56696 是当前的进程 ID,为了防止单机多进程出现 TraceId 冲突的情况,所以在 TraceId 末尾添加了当前的进程 ID。
6.3 SpanId 生成规则
span 是层的意思,比如在第一个实例算是第一层, 请求代理或者分流到下一个实例处理,就是第二层,以此类推。通过层,SpanId 代表本次调用在整个调用链路树中的位置。
假设一个 服务器实例 A 接收了一次用户请求,代表是整个调用的根节点,那么 A 层处理这次请求产生的非服务调用日志记录 spanid 的值都是 0,A 层需要通过 RPC 依次调用 B、C、D 三个服务器实例,那么在 A 的日志中,SpanId 分别是 0.1,0.2 和 0.3,在 B、C、D 中,SpanId 也分别是 0.1,0.2 和 0.3;如果 C 系统在处理请求的时候又调用了 E,F 两个服务器实例,那么 C 系统中对应的 spanid 是 0.2.1 和 0.2.2,E、F 两个系统对应的日志也是 0.2.1 和 0.2.2。
根据上面的描述可以知道,如果把一次调用中所有的 SpanId 收集起来,可以组成一棵完整的链路树。
spanid 的生成本质:在跨层传递透传的同时,控制大小版本号的自增来实现的。
七 衍生问题2 - 短链
短网址主要功能包括网址缩短与还原两大功能。相对于长网址,短网址可以更方便地在电子邮件,社交网络,微博和手机上传播,例如原来很长的网址通过短网址服务即可生成相应的短网址,避免折行或超出字符限制。
常用的 ID 生成服务比如:MySQL ID 自增、 Redis 键自增、号段模式,生成的 ID 都是一串数字。短网址服务把客户的长网址转换成短网址,
实际是在域名后面拼接新产生的数字类型 ID,直接用数字 ID,网址长度也有些长,服务可以通过数字 ID 转更高进制的方式压缩长度。这种算法在短网址的技术实现上越来越多了起来,它可以进一步压缩网址长度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号