使用r2pipe, capstone和Gephi进行二进制数据聚类
说明:本篇内容参照看雪论坛的一篇外文翻译所作的实验,地址:https://bbs.pediy.com/thread-258042.htm
介绍
新型恶意软件通常会依据代码相似性, 或者某些厂商所谓恶意软件DNA或基因组分析来将其归类为某种已知恶意软件。它基于代码相似性采取两个特征来对恶意软件进行聚类:
- 字符串
- 掩饰过的基本块
radare2
Windows下可以通过访问https://rada.re/r/下载安装版,双击即可安装。所有文件均放在C:\Users\UserName\AppData\目录下,同时你必须添加环境变量才可以自由使用。不过本章因为涉及到一个sh脚本,故使用Ubuntu 18环境来进行实验。项目地址:https://github.com/radareorg/radare2
radare2:十六进制编辑器和调试器的核心,通常通过它进入交互式界面。
rabin2:从可执行二进制文件中提取信息。
rasm2:汇编和反汇编。
rahash2:基于块的哈希工具。
radiff2:二进制文件或代码差异比对。
rafind2:查找字节模式。
ragg2:r_egg 的前端,将高级语言编写的简单程序编译成x86、x86-64和ARM的二进制文件。
rarun2:用于在不同环境中运行程序。
rax2:数据格式转换。
环境
- Ubuntu
- Python 3.6
- Capstone
- Radare2
- r2pipe
- Gephi
sudo apt install python3
sudo apt install python-pip3
sudo pip3 install capstone
git clone https://github.com/radare/radare2.git
cd radare2
./sys/install.sh
代码
首先, 使用以下代码通过r2pipe管道连接Radare2来提取二进制程序中的字符串:
r2 = r2pipe.open(path, flags=['-2'])
r2.cmd('aaaa') #输入aa命令用来分析所有,使用aaa或者aaaa进行更多的分析
strings_json = r2.cmdj('izj')
#管道对象包含两种执行r2命令的主要方法:第一个是pipe.cmd(<command>) 它将以字符串形式返回命令的结果,第二个是pipe.cmdj(<command>j) 它将从radare2命令的输出返回一个已解析的JSON对象。
strings = []
for s in strings_json:
# FIXME: we "loose" the encoding in s['type'] here
# so a utf-8 strings will be treated the same as the same string but in ascii
s = base64.b64decode(s['string'])
strings.append( [hashlib.sha256(s).hexdigest(), s.decode('utf-8')] )
接下来, 使用以下代码提取基本块:
results = r2.cmd('pdbj @@ *').split('\n')
results.remove('')
temp = set()
for r in results:
temp.add(r)
temp = list(temp)
bb = []
for t in temp:
tbb = json.loads(t)
offset = tbb[0]['offset']
code = b''
for b in tbb:
code += bytes.fromhex(b['bytes'])
bb.append(code)
之后, 对每个基本块进行掩饰, 即将块内的立即数和偏移量用0覆写(“掩盖”). 因为在不同二进制程序的不同偏移位置的值是不同的, 比如该值是会随着二进制程序版本而变化的内存地址, 所以这样的掩饰能确保基本块能在不同的位置下也能进行比较. 我们可以通过以下代码使用capstone:
md = Cs(CS_ARCH_X86, CS_MODE_32)
md.detail = True
md.syntax = CS_OPT_SYNTAX_INTEL
def get_masked(inst):
code = inst.bytes
for i in range(inst.imm_offset, inst.imm_offset + inst.imm_size):
code[i] = 0
for i in range(inst.disp_offset, inst.disp_offset + inst.disp_size):
code[i] = 0
return code
masked_bb = []
for b in bb:
masked_b = b''
disasm_b = ''
for i in md.disasm(b, 0):
#print("%s\t%s\t%s\t%d\t%d" %(i.mnemonic, i.op_str, i.insn_name(), i.imm_size, i.disp_size))
disasm_b += i.mnemonic + '\t' + i.op_str + '\n'
force_mask = False
for g in i.groups:
if i.group_name(g) in ['call', 'jump']:
force_mask = True
if force_mask or i.imm_size > 1 or i.disp_size > 1:
masked_b += get_masked(i)
else:
masked_b += i.bytes
masked_bb.append([hashlib.sha256(masked_b).hexdigest(),disasm_b])
最后但同样重要的是, 我们输出以tab分隔的字符串和基本块:
for s in strings:
print(path +'\t'+ s[0] +'\t'+ s[1])
for b in masked_bb:
print(path +'\t'+ b[0] +'\t'+ b[1].replace('\n','; '))
完整的Python代码:
#!/usr/bin/python3.6
import r2pipe
import sys
import os
import hashlib
import json
import base64
from capstone import *
path = sys.argv[1]
payload = open(path,'rb').read()
payload_sha256 = hashlib.sha256(payload).hexdigest()
r2 = r2pipe.open(path, flags=['-2'])
r2.cmd('aaaa')
strings_json = r2.cmdj('izj')
strings = []
for s in strings_json:
# FIXME: we "loose" the encoding in s['type'] here
# so a utf-8 strings will be treated the same as the same string but in ascii
s = base64.b64decode(s['string'])
strings.append( [hashlib.sha256(s).hexdigest(), s.decode('utf-8')] )
results = r2.cmd('pdbj @@ *').split('\n')
results.remove('')
temp = set()
for r in results:
temp.add(r)
temp = list(temp)
bb = []
for t in temp:
tbb = json.loads(t)
offset = tbb[0]['offset']
code = b''
for b in tbb:
code += bytes.fromhex(b['bytes'])
bb.append(code)
md = Cs(CS_ARCH_X86, CS_MODE_32)
md.detail = True
md.syntax = CS_OPT_SYNTAX_INTEL
def get_masked(inst):
code = inst.bytes
for i in range(inst.imm_offset, inst.imm_offset + inst.imm_size):
code[i] = 0
for i in range(inst.disp_offset, inst.disp_offset + inst.disp_size):
code[i] = 0
return code
masked_bb = []
for b in bb:
masked_b = b''
disasm_b = ''
for i in md.disasm(b, 0):
#print("%s\t%s\t%s\t%d\t%d" %(i.mnemonic, i.op_str, i.insn_name(), i.imm_size, i.disp_size))
disasm_b += i.mnemonic + '\t' + i.op_str + '\n'
force_mask = False
for g in i.groups:
if i.group_name(g) in ['call', 'jump']:
force_mask = True
if force_mask or i.imm_size > 1 or i.disp_size > 1:
masked_b += get_masked(i)
else:
masked_b += i.bytes
masked_bb.append([hashlib.sha256(masked_b).hexdigest(),disasm_b])
for s in strings:
print(path +'\t'+ s[0] +'\t'+ s[1])
for b in masked_bb:
print(path +'\t'+ b[0] +'\t'+ b[1].replace('\n','; '))
为了能输入大量样本并将输出格式化为Gephi的可用格式, 我们可以使用 extract_all.sh:
#!/bin/bash
mkdir -p features
ls samples/* | while read input; do
output="$(echo "${input}" | sed 's/samples/features/g').csv"
python3 extract_features.py "${input}" > "${output}"
done
cat features/*.csv | awk -F'\t' '{print $1";basic-block-"$2}' > for_gephi.csv
使用
将extract_features.py和extract_all.sh以及一个包含有你样本的samples文件夹放置在同一目录下. 目录结构如下所示:
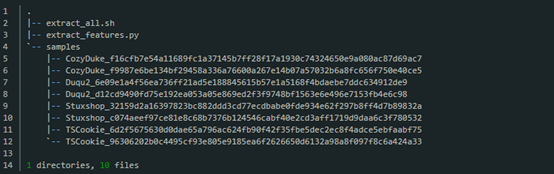
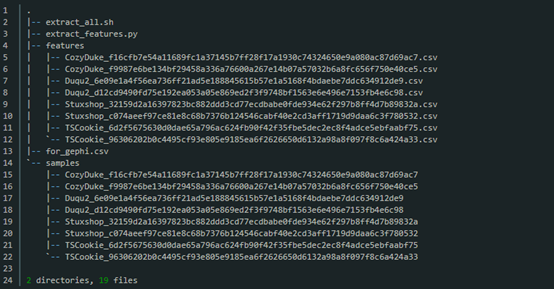
运行./extract_all.sh你的文件结构现在应该会像下面这样:
在Gephi中打开for_gephi.csv(依次点击File -> Import spreadsheet…)并作为邻接表导入.
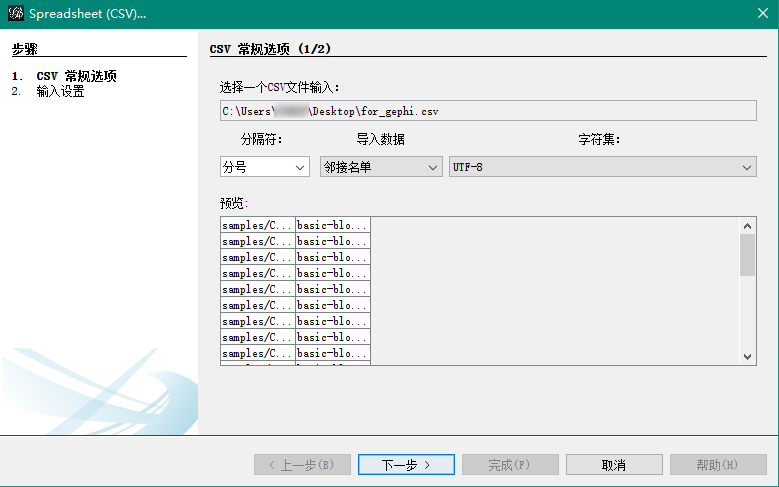
在导入设置界面上只需点击“Finish”,导入报告中应该不会有错误警告
接下来转到“Data Laboratory”, 选取所有的节点, 右击并选择“Edit node”。在属性窗口设置大小为1.0以及颜色为浅灰色。
接下来, 仅选择样本节点并将它的大小设置为20.0以及颜色为红色。
转到概要(“Overview”)视图, 并选取“ForceAtlas 2”布局, 随后点击“Play”,过一段时间后点击停止。
你也可以花些时间来给每个样本节点设置不同颜色并应用“Yifan Hu”布局, 以及短暂播放一下“ForceAtlas 2”以防重叠, 就能得到非常酷的聚类图像。当聚类结束时点击“Stop”, 然后转到“Preview”点击“Refresh”。 随后导出你的聚类图。
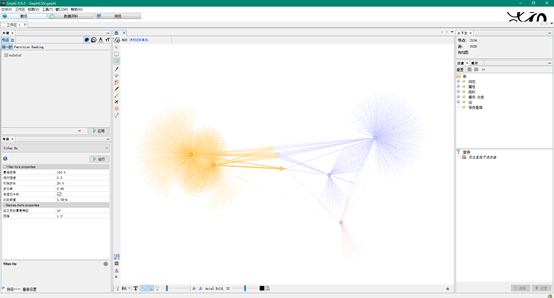
技巧:可以先用ForceAtlas 2布局算法快速跑一下,然后用Yifan Hu布局算法跑一段时间,然后转到预览,选择黑色背景,然后按照下图调整参数即可。
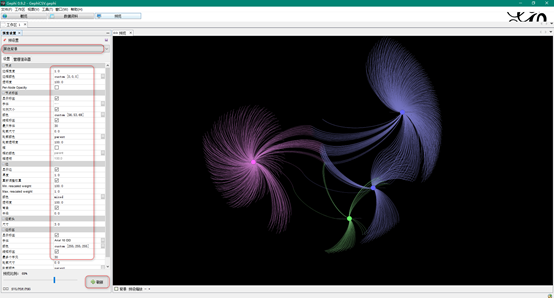
最终导出图片效果如下:

结论
从结果图像可以看出, 两两相关的恶意样本都聚类在了一起,即力导向图里通过基本块和字符串而拉在一起。代码和字符串的相似性匹配是准确的。因此,如果掩饰后的基本块在两个样本均存在,那么这意味着两个样本共享了某份代码,至少共享了该基本块。这里重要的是共享代码十分有意义,例如许多二进制文件共享库代码。虽然仅有少量指令的基本块显然也并不代表着有意义的代码共享,但如果你在样本之间的关键函数中找到了一些共享的基本块代码,那么它们很有可能就是相关的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号