
Spring源码分析——AnnotationConfigApplicationContext组件注册流程
工程搭建
Maven依赖:
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.3.5</version>
</dependency>
</dependencies>
在项目下新建一个byx.test包,然后在里面添加A、B、Config三个类:
public class A {
}
public class B {
}
@Component
public class Config {
}
A和B是两个普通的类(没有标注Component)注解,Config标注了Component注解,所以理论上只有Config会被注册到容器中。
然后再添加一个Main类作为启动类:
public class Main {
public static void main(String[] args) {
ApplicationContext ctx = new AnnotationConfigApplicationContext("byx.test");
// 输出容器中的所有bean的name
for (String name : ctx.getBeanDefinitionNames()) {
System.out.println(name);
}
}
}
在main函数中,创建了一个AnnotationConfigApplicationContext,然后输出容器中所有bean的name。
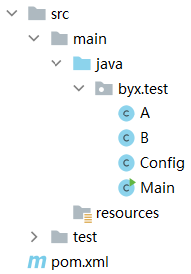
最终的项目结构是这样的:
运行Main,控制台输出如下:
org.springframework.context.annotation.internalConfigurationAnnotationProcessor
org.springframework.context.annotation.internalAutowiredAnnotationProcessor
org.springframework.context.event.internalEventListenerProcessor
org.springframework.context.event.internalEventListenerFactory
config
可以看到,容器中一共有5个bean,其中四个带internal的都是Spring内部自带的,config则是我们之前定义的Config类,下面就来探究一下这些组件是如何被注册的。
AnnotationConfigApplicationContext组件注册流程
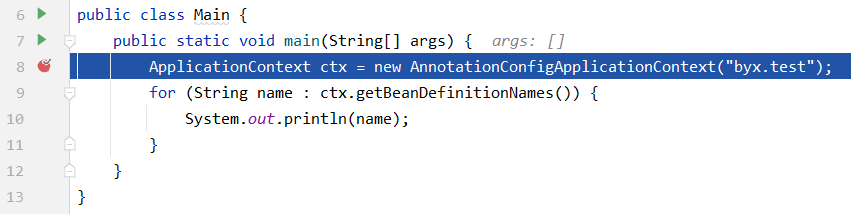
在main函数的这一行加一个断点,并启动调试:
首先step into,然后多次step over,直到进入AnnotationConfigApplicationContext的构造函数:

继续step over,执行完this()调用:

这里分享一个调试Spring的小技巧,就是通过观察BeanFactory内部的beanDefinitionMap这个成员变量来分析组件注册的时机。beanDefinitionMap是一个ConcurrentHashMap,它的键是bean的name,值是对应的BeanDefinition。通过观察这个变量,我们就可以知道当前容器中所有已注册的bean信息。
现在把注意力放在调试器的Varieables面板,找到this.beanFactory.beanDefinitionMap这个变量。

可以看到,beanDefinitionMap的大小为4,里面已经有了四个bean:
这四个bean都是Spring内部自带的组件,由此可推测,Spring内部自带的组件的注册是在this()调用中,即AnnotationConfigApplicationContext的默认构造函数中完成的,。
继续step over,执行完scan(basePackages)这行后,发现beanDefinitionMap的大小变成了5,增加了一个name为config的bean,正是我们自定义的Config类(该类被Component注解标注):


由此可推测,被Component注解标注的类是在scan(basePackages)调用中被注册的。从方法名可以推测,其内部执行了一个包扫描的操作。
Spring内置组件的注册
回到AnnotationConfigApplicationContext的构造函数:
public AnnotationConfigApplicationContext(String... basePackages) {
this();
scan(basePackages);
refresh();
}
从上面的分析可以知道,AnnotationConfigApplicationContext在它的默认构造函数中注册内部组件,即this()调用,实现如下:
public AnnotationConfigApplicationContext() {
StartupStep createAnnotatedBeanDefReader = this.getApplicationStartup().start("spring.context.annotated-bean-reader.create");
this.reader = new AnnotatedBeanDefinitionReader(this);
createAnnotatedBeanDefReader.end();
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
使用调试器跟踪,同时注意beanDefinitionMap的变化,发现注册操作发生在this.reader = new AnnotatedBeanDefinitionReader(this)这行代码中,所以直接查看AnnotatedBeanDefinitionReader的构造函数:
public AnnotatedBeanDefinitionReader(BeanDefinitionRegistry registry) {
this(registry, getOrCreateEnvironment(registry));
}
继续进入另一个构造函数:
public AnnotatedBeanDefinitionReader(BeanDefinitionRegistry registry, Environment environment) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
Assert.notNull(environment, "Environment must not be null");
this.registry = registry;
this.conditionEvaluator = new ConditionEvaluator(registry, environment, null);
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
真正的注册操作发生在AnnotationConfigUtils的registerAnnotationConfigProcessors方法中:
public static void registerAnnotationConfigProcessors(BeanDefinitionRegistry registry) {
registerAnnotationConfigProcessors(registry, null);
}
继续进入registerAnnotationConfigProcessors重载方法,终于看到了核心代码(省略了一部分无关紧要的内容):
public static Set<BeanDefinitionHolder> registerAnnotationConfigProcessors(
BeanDefinitionRegistry registry, @Nullable Object source) {
...
Set<BeanDefinitionHolder> beanDefs = new LinkedHashSet<>(8);
// 注册org.springframework.context.annotation.internalConfigurationAnnotationProcessor
// ConfigurationClassPostProcessor用来处理Configuration注解
if (!registry.containsBeanDefinition(CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(ConfigurationClassPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME));
}
// 注册org.springframework.context.annotation.internalAutowiredAnnotationProcessor
// AutowiredAnnotationBeanPostProcessor用来处理Autowired注解
if (!registry.containsBeanDefinition(AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(AutowiredAnnotationBeanPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME));
}
...
// 注册org.springframework.context.event.internalEventListenerProcessor
// 与EventListener有关
if (!registry.containsBeanDefinition(EVENT_LISTENER_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(EventListenerMethodProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, EVENT_LISTENER_PROCESSOR_BEAN_NAME));
}
// 注册org.springframework.context.event.internalEventListenerFactory
// 还是与EventListener有关
if (!registry.containsBeanDefinition(EVENT_LISTENER_FACTORY_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(DefaultEventListenerFactory.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, EVENT_LISTENER_FACTORY_BEAN_NAME));
}
return beanDefs;
}
registerAnnotationConfigProcessors方法内部注册了我们在控制台输出中看到的四个Spring内置组件。
Component注解的处理
回到AnnotationConfigApplicationContext的构造函数:
public AnnotationConfigApplicationContext(String... basePackages) {
this();
scan(basePackages);
refresh();
}
从上面的分析可以知道,scan(basePackages)这个调用负责扫描并注册被Component标注的bean,该方法的实现如下:
public void scan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
StartupStep scanPackages = this.getApplicationStartup().start("spring.context.base-packages.scan")
.tag("packages", () -> Arrays.toString(basePackages));
this.scanner.scan(basePackages);
scanPackages.end();
}
真正干活的是this.scanner.scan(basePackages)这个调用,其中this.scanner是一个ClassPathBeanDefinitionScanner的实例,它在AnnotationConfigApplicationContext的默认构造函数中被初始化:
public AnnotationConfigApplicationContext() {
StartupStep createAnnotatedBeanDefReader = this.getApplicationStartup().start("spring.context.annotated-bean-reader.create");
this.reader = new AnnotatedBeanDefinitionReader(this);
createAnnotatedBeanDefReader.end();
this.scanner = new ClassPathBeanDefinitionScanner(this); // 初始化scanner
}
ClassPathBeanDefinitionScanner的scan方法实现如下:
public int scan(String... basePackages) {
int beanCountAtScanStart = this.registry.getBeanDefinitionCount();
doScan(basePackages);
// Register annotation config processors, if necessary.
if (this.includeAnnotationConfig) {
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
return (this.registry.getBeanDefinitionCount() - beanCountAtScanStart);
}
scan方法内部调用了doScan方法,同时还记录了bean数量的改变量。doScan方法实现如下:
// basePackages就是我们在main函数中构造AnnotationConfigApplicationContext时传入的包名
// 从这里也可以看出,我们可以同时传入多个包名
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
// 遍历每个包名
for (String basePackage : basePackages) {
// 寻找每个包下符合条件的类,并包装成BeanDefinition
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
// 遍历找到的每个BeanDefinition
for (BeanDefinition candidate : candidates) {
// 设置scope属性
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
// 生成beanName
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
// 设置一些默认属性
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
// 处理Lazy、Primary、DependsOn、Role、Description这些注解
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
// 把BeanDefinition包装成BeanDefinitionHolder
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
// 真正执行注册操作
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
// 返回所有BeanDefinitionHolder
return beanDefinitions;
}
doScan方法是注册bean的核心逻辑,它遍历每个传入的包名,通过调用findCandidateComponents方法来获取每个包下满足条件的bean,然后进行一些必要的设置,最后调用registerBeanDefinition方法完成注册操作。
findCandidateComponents方法的实现如下:
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
return scanCandidateComponents(basePackage);
}
}
scanCandidateComponents方法的实现如下:
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
// 将包名转换成一个资源url
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// 读取资源
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
// 遍历所有资源,每个资源表示一个.class文件
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
if (resource.isReadable()) {
try {
// 获取class的元数据,包括注解的信息
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
// 判断是否满足条件
if (isCandidateComponent(metadataReader)) {
// 构造BeanDefinition
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + resource);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not matching any filter: " + resource);
}
}
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not readable: " + resource);
}
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
// 返回所有满足条件的BeanDefinition
return candidates;
}
scanCandidateComponents方法使用Spring内置的资源读取机制读取指定包下的所有class文件,然后转换成MetadataReader,并传入isCandidateComponent方法判断是否满足要求,如果满足要求则加入isCandidateComponent集合。
isCandidateComponent方法的实现如下:
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {
for (TypeFilter tf : this.excludeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return false;
}
}
for (TypeFilter tf : this.includeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return isConditionMatch(metadataReader);
}
}
return false;
}
isCandidateComponent方法通过excludeFilters和includeFilters两个集合来对MetadataReader进行过滤。在调试中可以发现,includeFilters包含了一个Component注解的过滤器,所以可以过滤出标注了Component的类。
如果使用调试器调试程序,可以发现,isCandidateComponent方法只会对Config类返回true,而对其他类(A、B、Main)都返回false。
includeFilters的初始化是在org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#registerDefaultFilters方法中被初始化的(ClassPathScanningCandidateComponentProvider是ClassPathBeanDefinitionScanner的父类):
protected void registerDefaultFilters() {
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
...
}
到此,Component注解的处理过程就分析完了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号