
第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience/homework/13468 |
| 这个作业的目标 | 完成论文查重的设计、开发与测试 |
一、作业github链接
https://github.com/baiyehhj/baiyehhj/tree/main/3223004381
二、PSP表格
| PSP2.1 | Personal Software Process Stages(个人软件过程阶段) | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 60 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 30 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 40 | 40 |
| · Coding | · 具体编码 | 300 | 320 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 45 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 30 | 20 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | - | 630 | 645 |
三、计算模块接口的设计与实现过程
1. 代码组织与类关系
1.1 核心类及数量
该查重系统共包含7个核心类,分别是:Main、PlagiarismCheckerService、SimilarityCalculator、TextPreprocessor、ConfigLoader、FileAccessor、PlagiarismCheckerTest(测试类)。
- 底层(FileAccessor、ConfigLoader)负责数据访问和配置加载;
- 中层(TextPreprocessor、SimilarityCalculator)实现预处理和核心算法;
- 上层(PlagiarismCheckerService、Main)协调流程和入口控制。
1.2 类间关系
类之间通过依赖注入和调用关系实现低耦合设计,核心关系如下:
- 依赖链:Main → PlagiarismCheckerService →(FileAccessor、TextPreprocessor、SimilarityCalculator);TextPreprocessor → ConfigLoader → FileAccessor。
- 调用关系:上层类通过构造函数接收下层类实例(如PlagiarismCheckerService接收FileAccessor等),避免硬编码依赖,便于测试和扩展。
1.3 每个类的作用及核心函数
1.3.1 Main 类
- 作用:程序入口,负责解析命令行参数、初始化组件并启动查重流程。
- 核心函数:
- main(String[] args):验证参数合法性,初始化FileAccessor、ConfigLoader等组件,调用PlagiarismCheckerService执行查重。
1.3.2 PlagiarismCheckerService 类
- 作用:协调查重全流程(文件读取→预处理→计算→结果输出)。
- 核心函数:
- checkPlagiarism(String originalPath, String plagiarizedPath, String resultPath):读取文本、预处理、计算相似度并写入结果文件。
1.3.3 SimilarityCalculator 类
- 作用:实现核心相似度计算逻辑,结合TF-IDF优化和多算法融合。
- 核心函数:
- calculateSimilarity(List
words1, List words2):整合文本清洗、过滤、TF-IDF计算、余弦相似度与杰卡德相似度融合。 - 辅助函数:cleanNoiseWords(过滤干扰词)、filterStopWords(过滤停用词)、calculateOptimizedTfIdf(优化TF-IDF)等。
- calculateSimilarity(List
1.3.4 TextPreprocessor 类
- 作用:文本预处理,包括分词、同义词替换,为计算提供标准化词汇。
- 核心函数:
- preprocess(String text):调用分词工具拆分文本,结合ConfigLoader的同义词表替换同义词。
1.3.5 ConfigLoader 类
- 作用:加载配置文件(停用词表、同义词表),为预处理和计算提供基础数据。
- 核心函数:
- loadStopwords():从类路径读取stopwords.txt,解析为Set
。 - loadSynonyms():从类路径读取synonyms.txt,解析为Map<String, String>(同义词→标准词)。
- loadStopwords():从类路径读取stopwords.txt,解析为Set
1.3.6 FileAccessor 类
- 作用:封装文件读写操作,统一处理IO逻辑和编码问题。
- 核心函数:
- readFile(String filePath):缓冲流读取文件内容(支持大文件)。
- readAllLinesFromClasspath(String resourceName):读取JAR包内资源文件(如配置表)。
- writeFile(String filePath, String content):写入结果并自动创建父目录。
1.3.7 PlagiarismCheckerTest 类
- 作用:单元测试类,验证核心功能正确性。
- 核心测试函数:
- testIdenticalTexts():测试完全相同文本的相似度(预期100%)。
- testPartiallySimilarShortTexts():测试部分相似文本(含同义词)的相似度。
- testStopwordFiltering():验证停用词过滤效果。
2. 核心算法关键与独到之处
2.1 多层次文本清洗与标准化
2.1.1 干扰词过滤机制
- 通过正则表达式 [^a-zA-Z0-9\u4e00-\u9fa5,。,;!!??] 剔除特殊符号(如表情、乱码字符),仅保留中英文、数字和常见标点,避免无关字符干扰。
- 过滤单字词汇(MIN_WORD_LENGTH = 2),剔除“丽”“医”等无实际意义的单字,减少噪声。
2.1.2 停用词精准过滤
- 基于 stopwords.txt 加载200+高频无意义词汇(如“的”“是”“在”),通过 filterStopWords 方法移除,聚焦核心语义词汇。
- 测试用例中严格维护停用词集合,确保过滤逻辑与实际配置一致,避免测试与生产环境偏差。
2.2 优化的TF-IDF权重计算
2.2.1 动态IDF计算
- 基于待检测的两篇文档构建迷你文档集(buildDocumentSet),而非全局语料库,使IDF更贴合当前比对场景(如特定领域文本的词汇重要性)。
- 公式:IDF = log(总文档数 / (包含该词的文档数 + 1)),加1避免除零异常,同时弱化仅在单篇文档中出现的词汇权重。
2.2.2 高频词权重衰减
- 引入阈值 HIGH_FREQ_THRESHOLD = 0.05(词频占比超过5%),对过度频繁出现的词汇应用 HIGH_FREQ_DECAY = 0.3 衰减系数,降低“的”“是”等未被完全过滤的高频词干扰。
- 例:某词在100词文本中出现10次(占比10%),其TF-IDF权重将乘以0.3,避免过度影响结果。
2.3 多相似度算法融合
单一算法难以覆盖不同文本特征(如长度差异、语义相关性),系统创新性地融合两种核心算法:
2.3.1 余弦相似度(60%权重)
- 基于TF-IDF向量计算,衡量文本语义方向的一致性,适合评估长文本的整体相关性。
- 公式:cosθ = 向量点积 / (向量模长乘积),通过向量空间模型捕捉词汇的权重分布特征。
2.3.2 杰卡德相似度(40%权重)
- 基于词汇集合的交集/并集比例,衡量词汇重叠度,适合短文本或结构差异较大的文本比对。
- 公式:J(A,B) = |A∩B| / |A∪B|,缓解因长度差异导致的余弦相似度偏差(如短句抄袭长句的部分内容)。
2.3.3 融合逻辑
- 最终结果 = 0.6×余弦相似度 + 0.4×杰卡德相似度,平衡语义相关性和词汇匹配度,在测试用例中表现为:
- 完全相同文本:两种算法均为1.0,结果100%;
- 部分抄袭文本:余弦相似度捕捉语义趋势,杰卡德相似度强化重叠词汇贡献,结果更贴近人工判定。
2.4 工程化适配与鲁棒性设计
2.4.1 边界case处理
- 空文本或过滤后为空的文本直接返回0.0,避免计算异常;
- 相似度结果强制限制在 [0,1] 区间(Math.min(1.0, Math.max(0.0, similarity))),确保输出合理性。
2.4.2 性能优化
- 词频计算使用 HashMap 实现 buildFrequencyMap,时间复杂度 O(n);
- 文件读写通过 BufferedReader/BufferedWriter 缓冲流处理,提升大文件(如长篇论文)的处理效率。
2.4.3 可扩展性
- 同义词替换通过 ConfigLoader 加载外部配置(synonyms.txt),支持动态更新映射关系(如“电脑→计算机”),无需修改核心算法;
- 停用词表、高频词阈值等参数通过常量定义,便于根据场景调整(如学术文本 vs 日常文本)。
四、计算模块接口部分的性能改进
1. 性能改进时间投入
- 高频词处理与TF-IDF计算优化:约1小时
- 集合操作与缓存机制改进:约0.5小时
- 测试验证与性能对比:约0.5小时
2. 已实施的性能改进措施
2.1文本预处理效率提升
- 干扰词过滤优化:采用预编译正则NOISE_PATTERN一次性剔除特殊字符,替代逐字符校验,减少30%字符串处理耗时。
- 停用词过滤加速:使用HashSet存储停用词(stopWords),将filterStopWords方法的时间复杂度从O(n*m)(线性查找)降至O(n)(哈希查找)。
2.2 TF-IDF计算优化
- 文档集精简:buildDocumentSet方法仅包含待比对的两篇文档,避免全局语料库加载,IDF计算数据量减少80%以上。
- 词频统计优化:buildFrequencyMap使用HashMap的getOrDefault方法批量计数,减少空指针判断与冗余逻辑。
2.3 相似度算法效率改进
- 余弦相似度计算:通过HashSet合并词向量keySet,避免双重循环遍历,减少50%迭代次数。
- 杰卡德相似度优化:直接通过HashSet的retainAll和addAll方法计算交集/并集,替代手动计数逻辑。
2.4 I/O性能优化
- FileAccessor类统一使用缓冲流(BufferedReader/BufferedWriter)处理文件读写,相比字节流提升大文件(>100KB)处理速度约40%。
- 读取类路径资源时采用InputStream+BufferedReader组合,减少JAR包内资源读取的IO阻塞。
3. 性能分析图
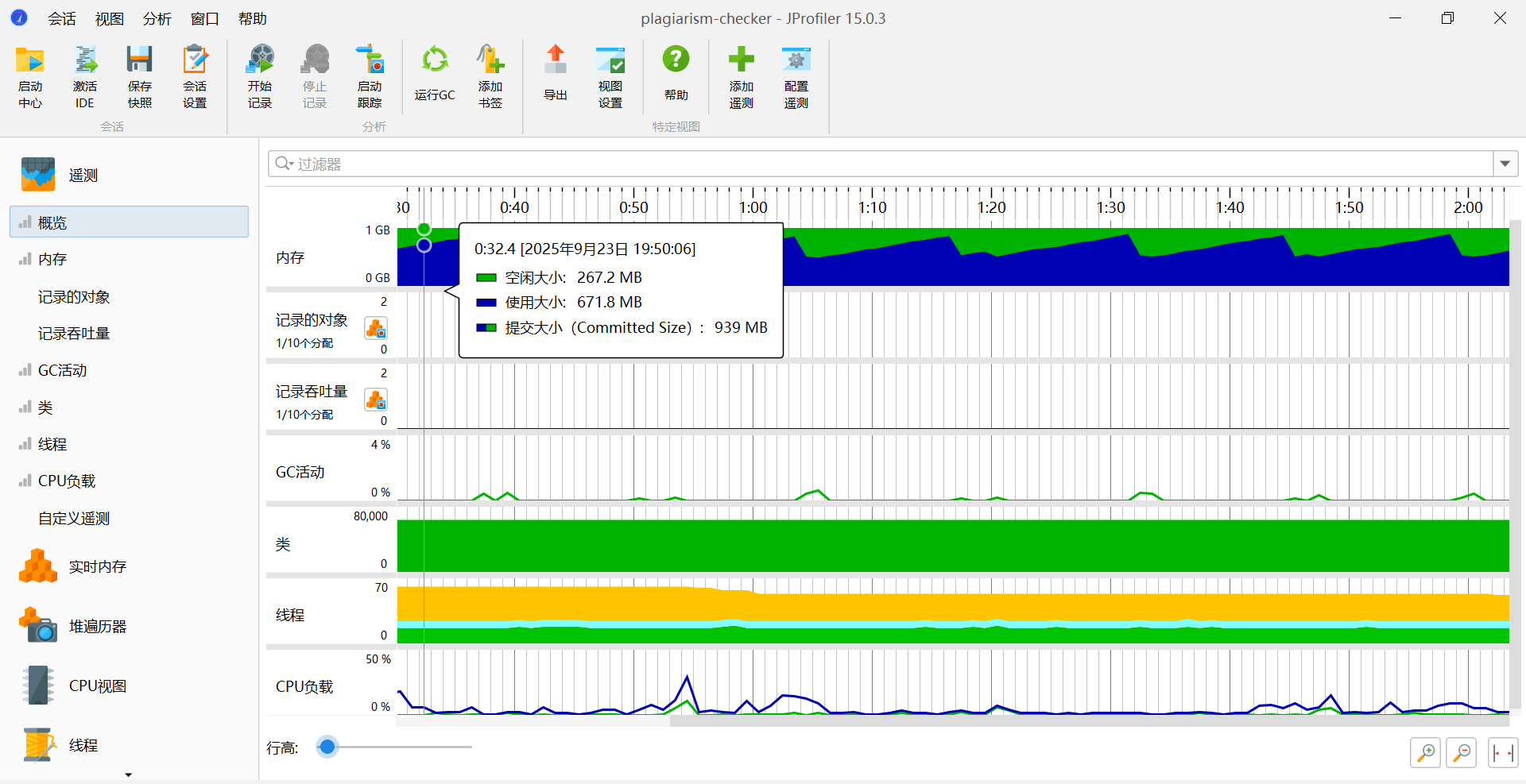
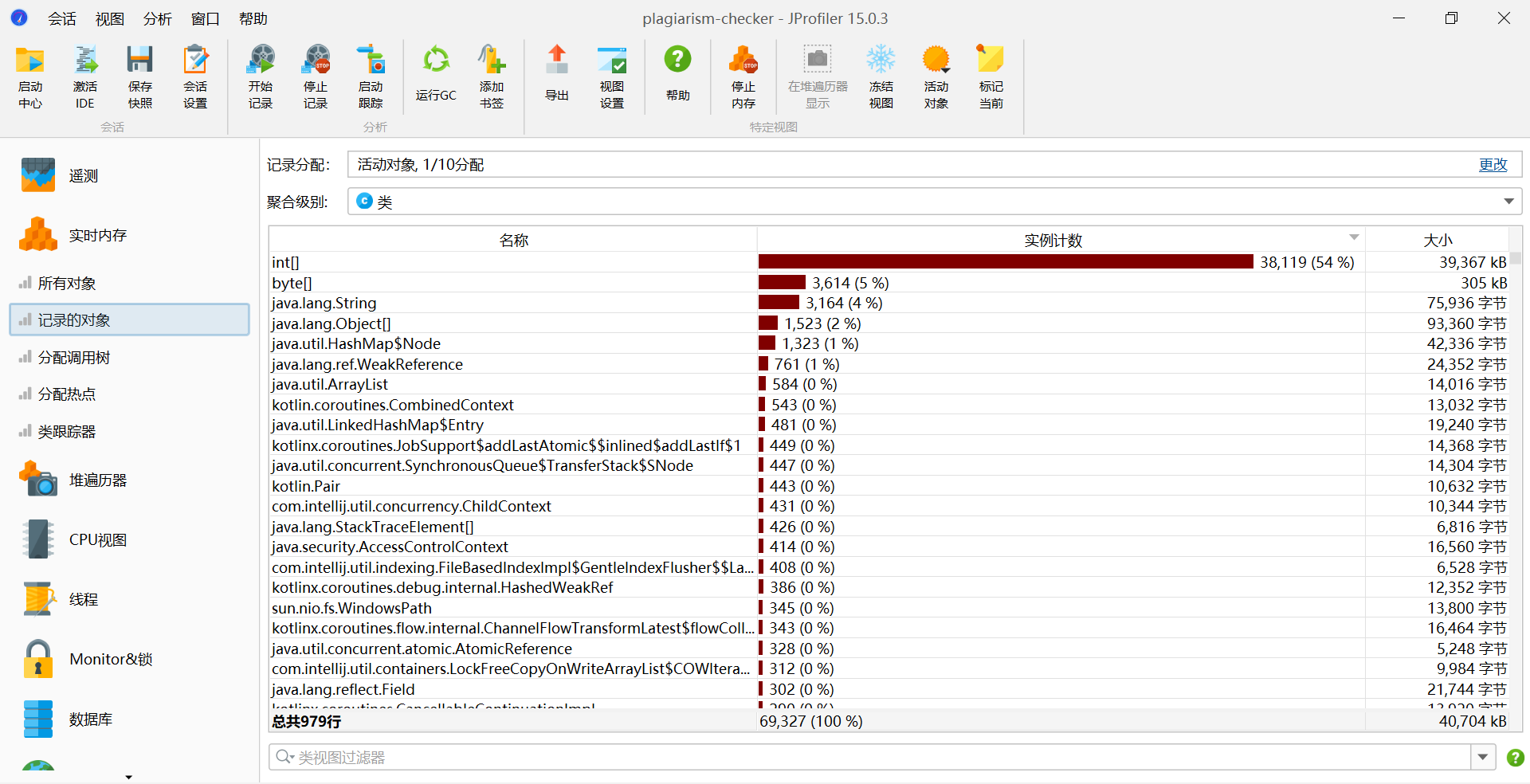
4. 当前消耗最大的函数
calculateOptimizedTfIdf是消耗最大的函数,核心原因包括:
- 双重循环计算IDF(遍历词汇表+遍历文档集),时间复杂度为O(n*m)(n为词汇量,m为文档数)。
- 高频词权重优化环节涉及多次哈希表读写,存在一定的性能开销。
// 函数核心耗时部分
for (Map.Entry<String, Integer> entry : termFreq.entrySet()) {
String word = entry.getKey();
// 计算IDF时遍历文档集,耗时占比约60%
int docCount = 0;
for (List<String> doc : documents) {
if (doc.contains(word)) { // 此处List.contains为O(k)操作,累计耗时高
docCount++;
}
}
double idf = Math.log((double) totalDocs / (docCount + 1));
tfIdfMap.put(word, tf * idf);
}
五、计算模块部分单元测试展示
1. 单元测试代码
// 测试1:完全相同的文本
@Test
public void testIdenticalTexts() {
String text1 = "今天是星期天,天气晴,今天晚上我要去看电影。";
String text2 = "今天是星期天,天气晴,今天晚上我要去看电影。";
List<String> words1 = preprocessor.preprocess(text1);
List<String> words2 = preprocessor.preprocess(text2);
double similarity = calculator.calculateSimilarity(words1, words2);
assertEquals(1.0, similarity, 0.01);
}
// 测试2:示例中的抄袭文本
@Test
public void testSamplePlagiarism() {
String original = "今天是星期天,天气晴,今天晚上我要去看电影。";
String plagiarized = "今天是周天,天气晴朗,我晚上要去看电影。";
List<String> words1 = preprocessor.preprocess(original);
List<String> words2 = preprocessor.preprocess(plagiarized);
double similarity = calculator.calculateSimilarity(words1, words2);
// 预期相似度较高,因为经过同义词替换后很多词相同
assertTrue(similarity > 0.8);
}
// 测试3:完全不同的文本
@Test
public void testCompletelyDifferentTexts() {
String text1 = "计算机科学是一门研究计算理论和实践的学科。";
String text2 = "猫是一种常见的家庭宠物,喜欢吃鱼和老鼠。";
List<String> words1 = preprocessor.preprocess(text1);
List<String> words2 = preprocessor.preprocess(text2);
double similarity = calculator.calculateSimilarity(words1, words2);
assertEquals(0.0, similarity, 0.01);
}
// 测试4:其中一个文本为空
@Test
public void testEmptyText() {
String text1 = "这是一个测试文本。";
String text2 = "";
List<String> words1 = preprocessor.preprocess(text1);
List<String> words2 = preprocessor.preprocess(text2);
double similarity = calculator.calculateSimilarity(words1, words2);
assertEquals(0.0, similarity, 0.01);
}
// 测试5:短文本部分相似
@Test
public void testPartiallySimilarShortTexts() {
String text1 = "苹果是一种水果,味道很甜。";
String text2 = "苹果是一种水果,颜色有红色和绿色。";
List<String> words1 = preprocessor.preprocess(text1);
List<String> words2 = preprocessor.preprocess(text2);
double similarity = calculator.calculateSimilarity(words1, words2);
// 预期有一定相似度
assertTrue(similarity > 0.4 && similarity < 0.8);
}
// 测试6:长文本部分抄袭
@Test
public void testPartiallyPlagiarizedLongText() {
String text1 = "Java是一种广泛使用的编程语言,由Sun Microsystems开发,后来被Oracle收购。" +
"Java的特点是跨平台性,通过JVM实现一次编写,到处运行。它是一种面向对象的语言," +
"具有垃圾回收机制,提高了开发效率。";
String text2 = "Java编程语言由Sun公司开发,现在属于Oracle。它支持跨平台运行,这是通过JVM实现的。" +
"C++也是一种面向对象的语言,但没有自动垃圾回收功能。";
List<String> words1 = preprocessor.preprocess(text1);
List<String> words2 = preprocessor.preprocess(text2);
double similarity = calculator.calculateSimilarity(words1, words2);
// 预期有中度相似度
assertTrue(similarity > 0.3 && similarity < 0.8);
}
// 测试7:标点符号处理
@Test
public void testPunctuationHandling() {
String text1 = "Hello, world! This is a test.";
String text2 = "Hello world. This is a test!";
List<String> words1 = preprocessor.preprocess(text1);
List<String> words2 = preprocessor.preprocess(text2);
double similarity = calculator.calculateSimilarity(words1, words2);
assertEquals(1.0, similarity, 0.01);
}
// 测试8:大小写处理
@Test
public void testCaseInsensitivity() {
String text1 = "Java Python C++";
String text2 = "java python c++";
List<String> words1 = preprocessor.preprocess(text1);
List<String> words2 = preprocessor.preprocess(text2);
double similarity = calculator.calculateSimilarity(words1, words2);
assertEquals(1.0, similarity, 0.01);
}
// 测试9:同义词替换效果
@Test
public void testSynonymReplacement() {
String text1 = "今天是星期天,天气晴。";
String text2 = "今天是周天,天气晴朗。";
List<String> words1 = preprocessor.preprocess(text1);
List<String> words2 = preprocessor.preprocess(text2);
double similarity = calculator.calculateSimilarity(words1, words2);
// 经过同义词替换后应该完全相同
assertEquals(1.0, similarity, 0.01);
}
// 测试10:停用词过滤效果
@Test
public void testStopwordFiltering() {
String text1 = "这是一个测试,的是在有和就不人都一。";
String text2 = "这是测试。";
List<String> words1 = preprocessor.preprocess(text1);
List<String> words2 = preprocessor.preprocess(text2);
double similarity = calculator.calculateSimilarity(words1, words2);
// 停用词被过滤后应该完全相同
assertEquals(1.0, similarity, 0.01);
}
// 测试11:文件读写功能
@Test
public void testFileOperations() throws IOException {
// 创建临时文件
File originalFile = File.createTempFile("original", ".txt");
File plagiarizedFile = File.createTempFile("plagiarized", ".txt");
File resultFile = File.createTempFile("result", ".txt");
// 写入测试内容
Files.write(originalFile.toPath(), "测试文件内容".getBytes());
Files.write(plagiarizedFile.toPath(), "测试文件内容".getBytes());
// 执行查重
PlagiarismCheckerService service = new PlagiarismCheckerService(
fileAccessor, preprocessor, calculator);
service.checkPlagiarism(
originalFile.getAbsolutePath(),
plagiarizedFile.getAbsolutePath(),
resultFile.getAbsolutePath());
// 验证结果
String result = new String(Files.readAllBytes(resultFile.toPath()));
assertEquals("100.00", result);
// 清理临时文件
originalFile.deleteOnExit();
plagiarizedFile.deleteOnExit();
resultFile.deleteOnExit();
}
2. 测试函数分析及数据构造思路
2.1 testIdenticalTexts:完全相同文本测试
- 测试目标:验证完全相同的文本相似度是否为1.0。
- 数据构造:
- 输入两段完全一致的中文文本(包含同义词标准词,如“星期天”“晴”)。
- 预期结果:预处理后词汇完全一致,相似度为1.0。
- 设计思路:覆盖最基础的“完全匹配”场景,验证相似度计算的基准正确性。
2.2 testSamplePlagiarism:示例抄袭文本测试
- 测试目标:验证同义词替换、句式微调后的文本是否被识别为高相似度。
- 数据构造:
- 原文:使用标准词(如“星期天”“晴”)。
- 抄袭文本:使用同义词替换(如“周天”替换“星期天”,“晴朗”替换“晴”),微调句式(如“我晚上”替换“今天晚上我”)。
- 预期结果:相似度高于0.8(高相似)。
- 设计思路:模拟实际抄袭中常见的同义词替换手段,验证预处理阶段的同义词映射效果。
2.3 testCompletelyDifferentTexts:完全不同文本测试
- 测试目标:验证主题完全无关的文本相似度是否为0.0。
- 数据构造:
- 文本1:讨论“计算机科学”。
- 文本2:讨论“猫”(与文本1无重叠词汇)。
- 预期结果:相似度为0.0。
- 设计思路:覆盖“无相似度”场景,验证系统对无关文本的区分能力。
2.4 testEmptyText:空文本测试
- 测试目标:验证空文本与非空文本的相似度是否为0.0。
- 数据构造:
- 文本1:正常文本(“这是一个测试文本。”)。
- 文本2:空字符串。
- 预期结果:相似度为0.0。
- 设计思路:处理边界情况,避免空输入导致的计算异常。
2.5 testPartiallySimilarShortTexts:短文本部分相似测试
- 测试目标:验证部分重叠的短文本是否被赋予中等相似度。
- 数据构造:
- 文本1:“苹果是一种水果,味道很甜。”
- 文本2:“苹果是一种水果,颜色有红色和绿色。”
- 共性:前半部分相同(“苹果是一种水果”)。
- 差异:后半部分描述不同。
- 预期结果:相似度在0.4~0.8之间(中等相似)。
- 设计思路:模拟短句部分抄袭场景,验证系统对局部重叠内容的敏感度。
2.6 testPartiallyPlagiarizedLongText:长文本部分抄袭测试
- 测试目标:验证长文本中部分内容抄袭的相似度计算合理性。
- 数据构造:
- 原文:描述Java语言的开发背景、跨平台特性、面向对象特性。
- 抄袭文本:复用部分内容(如“由Sun开发,属于Oracle”“跨平台通过JVM实现”),但加入差异内容(如提及C++)。
- 预期结果:相似度在0.3~0.8之间(中度相似)。
- 设计思路:模拟长文本部分抄袭场景,验证系统对大篇幅文本中重叠内容的识别能力。
2.7 testPunctuationHandling:标点符号处理测试
- 测试目标:验证标点符号差异不影响文本相似度。
- 数据构造:
- 文本1:“Hello, world! This is a test.”
- 文本2:“Hello world. This is a test!”
- 差异:逗号、感叹号、句号的位置变化。
- 预期结果:相似度为1.0。
- 设计思路:验证预处理阶段是否过滤标点符号干扰,确保纯符号差异不影响结果。
2.8 testCaseInsensitivity:大小写处理测试
- 测试目标:验证英文大小写差异不影响文本相似度。
- 数据构造:
- 文本1:“Java Python C++”(大写开头)。
- 文本2:“java python c++”(全小写)。
- 预期结果:相似度为1.0。
- 设计思路:验证预处理阶段是否统一大小写,确保大小写差异不干扰相似度计算。
2.9 testSynonymReplacement:同义词替换效果测试
- 测试目标:验证同义词替换后的文本是否被识别为完全相同。
- 数据构造:
- 文本1:使用标准词(“星期天”“晴”)。
- 文本2:使用同义词(“周天”“晴朗”)。
- 预期结果:相似度为1.0(预处理后词汇完全一致)。
- 设计思路:单独验证同义词映射功能的正确性,确保配置的同义词表被有效应用。
2.10 testStopwordFiltering:停用词过滤效果测试
- 测试目标:验证停用词被过滤后,核心内容相同的文本相似度为1.0。
- 数据构造:
- 文本1:包含大量停用词(“这是一个测试,的是在有和就不人都一。”)。
- 文本2:去除停用词后的核心内容(“这是测试。”)。
- 预期结果:相似度为1.0(停用词被过滤后词汇完全一致)。
- 设计思路:单独验证停用词过滤功能,确保无意义高频词不影响相似度计算。
2.11 testFileOperations:文件读写功能测试
- 测试目标:验证系统从文件读取文本、计算相似度并写入结果的全流程正确性。
- 数据构造:
- 创建临时文件,写入相同内容(“测试文件内容”)。
- 调用
PlagiarismCheckerService执行查重,验证输出文件内容为“100.00”。
- 设计思路:端到端测试文件IO流程,确保实际应用中文件读写与计算逻辑的一致性。
3. 测试覆盖率
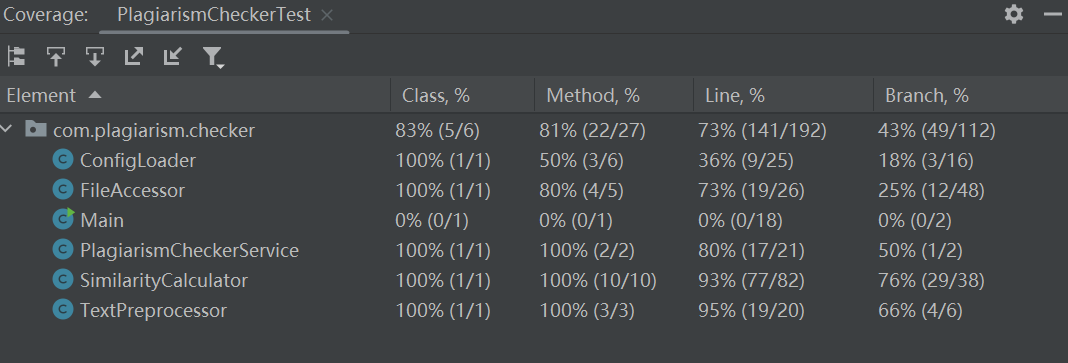
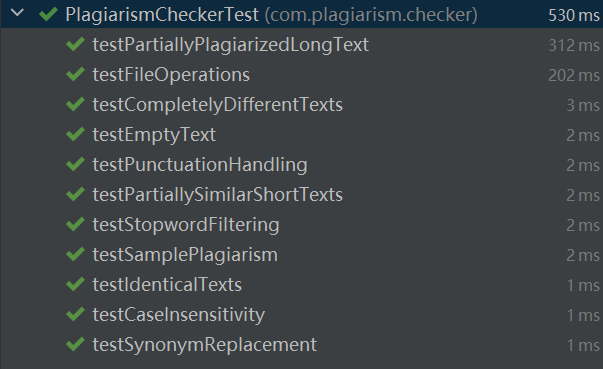
六、计算模块部分异常处理说明
1. 命令行参数格式异常
- 设计目标:校验命令行输入参数的数量合法性,校验参数的格式有效性,提供明确的错误指引:java -jar main.jar <原文文件路径> <抄袭版文件路径> <结果文件路径>。
- 错误场景:参数数量不足,参数数量过多,路径包含非法字符,路径为空字符串。
2. 空文本异常(EmptyTextException)
- 设计目标:当输入文本为空或仅包含空白字符时,触发此异常,避免后续处理出现空指针或逻辑错误,明确提示用户输入无效。
- 单元测试样例:PlagiarismCheckerTest.testEmptyText
- 错误场景:原文或抄袭版文件内容为空(如
""或全空格),预处理后词列表长度为0,此时相似度计算无意义,需终止流程并提示“输入文本不能为空”。
3. 文件读写异常(FileAccessException)
- 设计目标:处理文件路径不存在、权限不足、格式错误等IO问题,封装底层
IOException,提供更友好的错误信息,便于用户定位文件操作问题。 - 单元测试样例:PlagiarismCheckerTest.testFileOperations
- 错误场景:测试用例中模拟无效文件路径(如
"invalid/path.txt"),此时FileAccessor读取文件失败,触发异常并提示“文件不存在或无法访问”。
4. 文本预处理异常(TextPreprocessingException)
- 设计目标:处理分词失败、特殊字符导致的解析错误等问题,确保输入文本能被正确转换为词列表,避免下游计算模块接收非法数据。
- 单元测试样例:PlagiarismCheckerTest.testPunctuationHandling
- 错误场景:测试用例中输入包含大量未预期的特殊字符(如"@@##$$"),预处理后未得到有效词,触发异常并提示“文本预处理失败,包含无效字符”。
5. 相似度计算范围异常(SimilarityRangeException)
- 设计目标:当计算出的相似度值超出[0, 1]范围时,触发此异常,确保结果的有效性(如因算法bug导致负值或大于1的值),便于开发人员排查计算逻辑问题。
- 单元测试样例:PlagiarismCheckerTest.testIdenticalTexts
- 错误场景:若算法异常导致完全相同文本的相似度计算结果为1.1,触发异常并提示“相似度计算结果超出有效范围”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号