Kotlin 朱涛-25 源码 集合操作符 总结
目录
目录
25 | 集合操作符
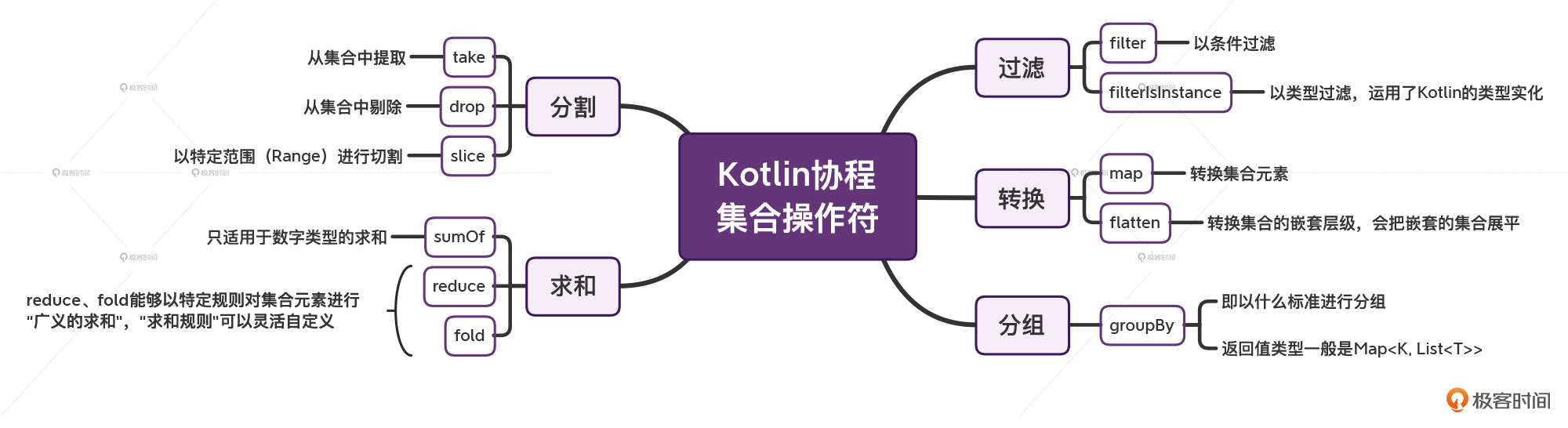
Kotlin 的集合 API,本质上是一种数据处理的模式。可以分为几个大类:过滤、转换、分组、分割、求和。
场景模拟
为了研究 Kotlin 集合 API 的使用场景,我们先来模拟一个实际的生活场景:统计学生成绩。
data class Student(val name: String = "", val score: Int = 0, var tag: Any = "")
val class1: List<Student> = listOf(
Student("小明", 83),
Student("小红", 92),
Student("小李", 50),
Student("小白", 67),
Student("小琳", 72),
Student("小刚", 97),
Student("小强", 57),
Student("小林", 86)
)
val class2: List<Student> = listOf(
Student("大明", 80),
Student("大红", 97),
Student("大李", 53),
Student("大白", 64),
Student("大琳", 76),
Student("大刚", 92),
Student("大强", 58),
Student("大林", 88)
)
过滤
注意,这里的过滤是指,过滤掉不符合条件的元素,而不是过滤掉符合条件的元素。
filter
最基础的过滤操作。
val result: List<Student> = class1.filter { it.score < 60 } // 过滤(筛选出)不及格的学生
public inline fun <T> Iterable<T>.filter(predicate: (T) -> Boolean): List<T> { // 扩展方法
return filterTo(ArrayList<T>(), predicate) // 创建了一个新的 ArrayList<T>
}
public inline fun <T, C : MutableCollection<in T>> Iterable<T>.filterTo( // 扩展方法
destination: C, // 目标集合
predicate: (T) -> Boolean, // 筛选条件
): C {
for (element in this) // 遍历当前集合
if (predicate(element)) destination.add(element) // 仅把符合条件的元素添加到目标集合
return destination // 返回的是目标集合
}
filterIndexed
作用、源码实现和 filter 基本一样,只是会额外带上集合元素的 index。
val result: List<Student> = class1.filterIndexed { index, student ->
student.tag = index + 1 // 过滤(筛选出)不及格的学生,并记录其序号
student.score < 60
}
filterIsInstance
过滤集合中特定类型的元素,运用了 Kotlin 的类型实化。
// inline + reified = 类型实化,作用就是让 Kotlin 的 伪泛型 变成 真泛型
public inline fun <reified R> Iterable<*>.filterIsInstance(): List<@NoInfer R> {
return filterIsInstanceTo(ArrayList<R>()) // 创建了一个新的 ArrayList<R>
}
public inline fun <reified R, C : MutableCollection<in R>> Iterable<*>.filterIsInstanceTo(destination: C): C {
for (element in this) if (element is R) destination.add(element) // 符合条件的留下
return destination
}
转换
map
map 是转换、映射的意思,类似 HashMap 中 map 的含义。
val result: List<String> = class1.map { "${it.name} - ${it.score} " } // 将 Student 转换成 String
public inline fun <T, R> Iterable<T>.map(transform: (T) -> R): List<R> {
return mapTo(ArrayList<R>(collectionSizeOrDefault(10)), transform) // 创建了一个新的集合
}
public inline fun <T, R, C : MutableCollection<in R>> Iterable<T>.mapTo(
destination: C,
transform: (T) -> R, // 注意,类型变了
): C {
for (item in this) destination.add(transform(item)) // 对集合中的每个元素,都进行一次转换
return destination
}
flatten
flatten 的作用是将嵌套的集合展开、铺平成为一个非嵌套的集合。
val list: List<List<Student>> = listOf(class1, class2)
val result: List<Student> = list.flatten() // 将嵌套的集合展开
public fun <T> Iterable<Iterable<T>>.flatten(): List<T> {
val result = ArrayList<T>() // 创建了一个新的集合
for (element in this) { // 遍历集合中的集合
result.addAll(element) // 注意用的是 addAll
}
return result
}
分组
groupBy
以什么标准进行分组。
val result: Map<Int, List<Student>> = class1.groupBy { it.score / 10 * 10 } // 分组
val students: List<Student>? = result[80] // 获取 80 - 89 分的学生
public inline fun <T, K> Iterable<T>.groupBy(keySelector: (T) -> K): Map<K, List<T>> {
return groupByTo(LinkedHashMap<K, MutableList<T>>(), keySelector) // 创建了一个 LinkedHashMap
}
public inline fun <T, K, M : MutableMap<in K, MutableList<T>>> Iterable<T>.groupByTo(destination: M, keySelector: (T) -> K): M {
for (element in this) { // 遍历元素
val key = keySelector(element) // 使用传入的方法,计算 Map 的 Key
val list = destination.getOrPut(key) { ArrayList<T>() } // 获取对应的 key 的集合
list.add(element)
}
return destination // 返回的是目标集合 LinkedHashMap
}
public inline fun <K, V> MutableMap<K, V>.getOrPut(key: K, defaultValue: () -> V): V {
val value = get(key) // 获取 Map 中对应的 key 的值
return if (value == null) { // 如果不存在
val answer = defaultValue() // 就使用传入的默认值,即一个新的 ArrayList
put(key, answer) // 将这个键值对塞到 Map 中
answer
} else {
value
}
}
分割
take、takeLast
val first3: List<Student> = class1.sortedByDescending { it.score }.take(3) // 取前三个数据
val last3: List<Student> = class1.sortedByDescending { it.score }.takeLast(3) // 取后三个数据
val third = class1.sortedByDescending { it.score }.take(3).takeLast(1) // 取第三个数据
sortedByDescending降序排序
drop、dropLast
val left = class1.sortedByDescending { it.score }.drop(3).dropLast(3) // 剔除前三个、后三个数据
val third = class1.sortedByDescending { it.score }.drop(2).take(1) // 取第三个数据
slice
slice:片;
部分; 薄片; 份额; 锅铲; (餐桌用)小铲; 削球;
val first3 = class1.sortedByDescending { it.score }.slice(0..2) // 取前三个数据
val size = class1.size
val last3 = class1.sortedByDescending { it.score }.slice(size - 3 until size) // 取后三个数据
求和
- sumOf:仅可以用于
数字类型的数据进行求和的场景 - reduce:使用传进来的规则进行广义求和,不局限于数字类型,也不局限于求和,比如也可以进行字符串拼接
- fold:对比 reduce 来说,只是多了一个初始值,其他都跟 reduce 一样
sumOf
val sum1: Int = class1.sumOf { it.score } // 计算全班学生的总分
val sum2: Int = class1.sumOf { it.score % 10 } // 求指定规则的总和
public inline fun <T> Iterable<T>.sumOf(selector: (T) -> Int): Int {
var sum: Int = 0.toInt() // 有多个重载方法,包括 Int、Long、Double、UInt、ULong
for (element in this) {
sum += selector(element) // 累加指定规则的数据
}
return sum // 仅可以用于数字类型的数据进行求和
}
reduce
reduce:
减少; 缩小(尺寸、数量、价格等); (使)蒸发; 减轻体重; 节食; 使还原;
val sum1: Int = class1.map { it.score }.reduce { acc, score -> acc + score } // 成绩求和
val sum2: String = class1.map { it.name }.reduce { acc, name -> "$acc - $name" } // 姓名累加
val sum3: Student = class1.reduce { acc, student -> Student("QT", acc.score + student.score) }
println(sum1) // 604
println(sum2) // 小明 - 小红 - 小李 - 小白 - 小琳 - 小刚 - 小强 - 小林
println(sum3) // Student(name=QT, score=604, tag=)
public inline fun <S, T : S> Iterable<T>.reduce(operation: (acc: S, T) -> S): S {
val iterator = this.iterator()
if (!iterator.hasNext()) throw UnsupportedOperationException("Empty collection can't be reduced.")
var accumulator: S = iterator.next() // accumulator:累加器
while (iterator.hasNext()) {
accumulator = operation(accumulator, iterator.next()) // 重复操作指定的规则
}
return accumulator // 不局限于数字类型,也不局限于求和
}
fold
fold 对比 reduce 来说,只是多了一个初始值,其他都跟 reduce 一样。所以,不需要初始值的时候,可以直接用 reduce。
val sum1: Int = class1.map { it.score }.fold(10000) { acc, score -> acc + score } // 成绩求和
val sum2: String = class1.map { it.name }.fold("QT") { acc, name -> "$acc - $name" } // 姓名累加
println(sum1) // 10604
println(sum2) // QT - 小明 - 小红 - 小李 - 小白 - 小琳 - 小刚 - 小强 - 小林
public inline fun <T, R> Iterable<T>.fold(initial: R, operation: (acc: R, T) -> R): R {
var accumulator = initial // 初始值
for (element in this) accumulator = operation(accumulator, element)
return accumulator
}
小结
经过前面的学习,分析 Kotlin 集合的源码是非常轻松的,它们无非就是高阶函数与 for 循环的简单结合。
需要特别注意的是,以上所有的操作符,都不会修改原本的集合,它们返回的集合是一个全新的集合。这也体现出了 Kotlin 推崇的不变性和无副作用这两个特性。
2017-07-12
本文来自博客园,作者:白乾涛,转载请注明原文链接:https://www.cnblogs.com/baiqiantao/p/7157710.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号