容器到云原生的路线:
容器 -> Kubernetes -> 微服务 ->云原生 -> 服务网格 -> 使用场景 -> 开源。
为什么使用K8S
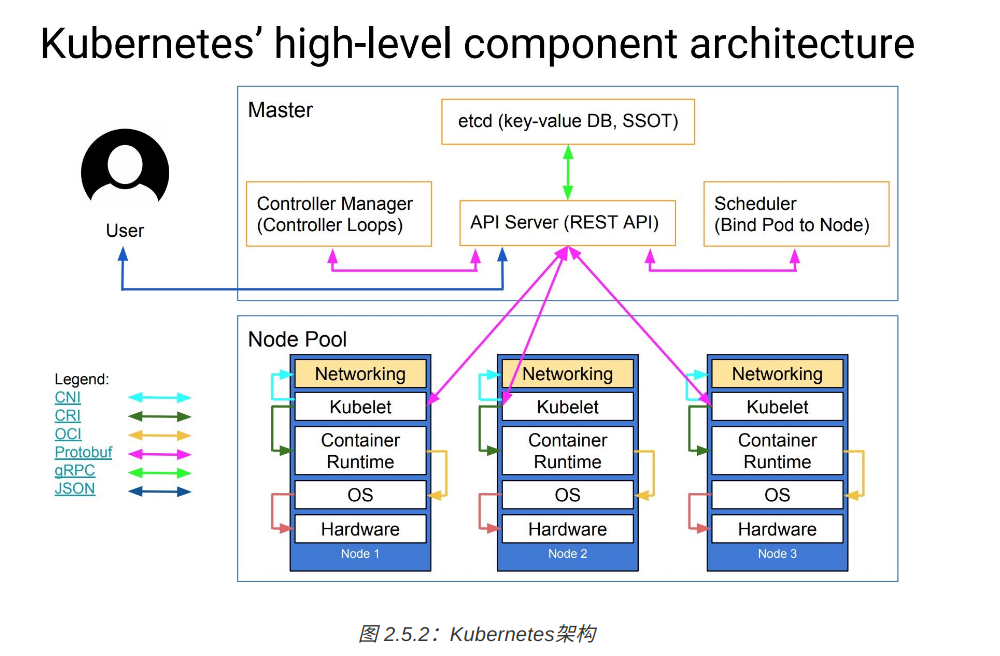
下面这张图是K8s的架构图,显示了组件间的CNI,CRI,OCI等,这些将Kubernetes 与某款具体产品解耦,给用户最大的定制程度,使得 Kubernetes 有机会成为跨云的真正的云原生应用的操作系统。
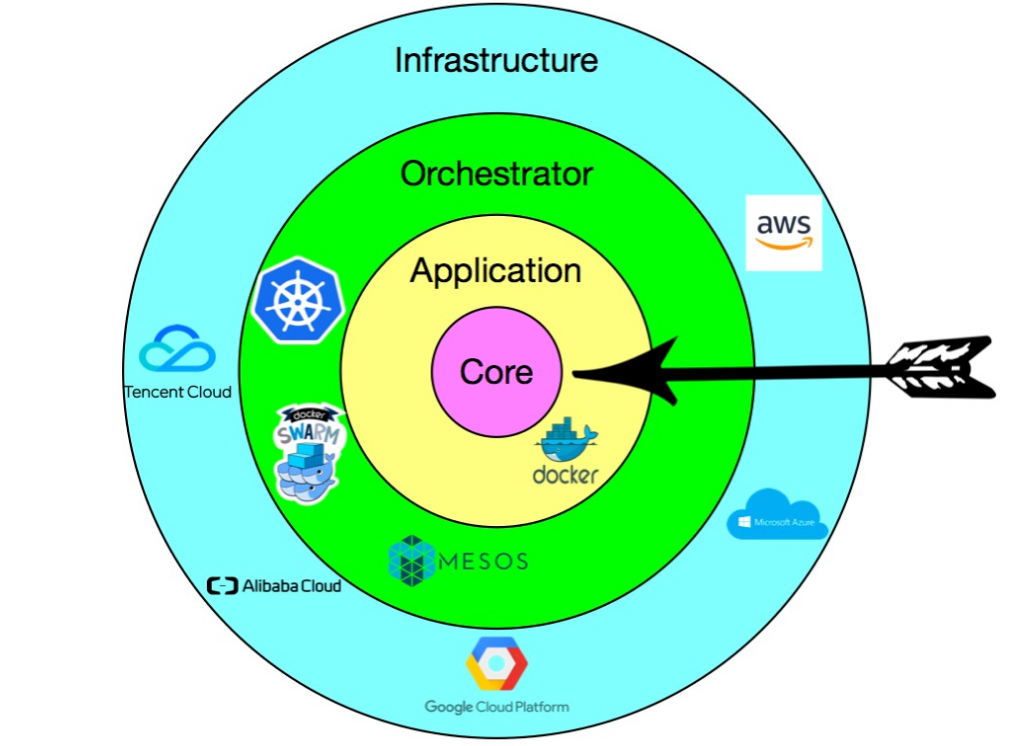
云原生的核心目标
云已经可以为我们提供稳定可以唾手可得的基础设施,但是业务上云成了一个难题,Kubernetes 的出现与其说是从最初的容器编排解决方案,倒不如说是为了解决应用上云(即云原生应用)这个难题。
包括微服务和 FaaS/Serverless 架构,都可以作为云原生应用的架构。
但就 2017 年为止,Kubernetes 的主要使用场景也主要作为应用开发测试环境、CI/CD 和运行 Web 应用这几个领域
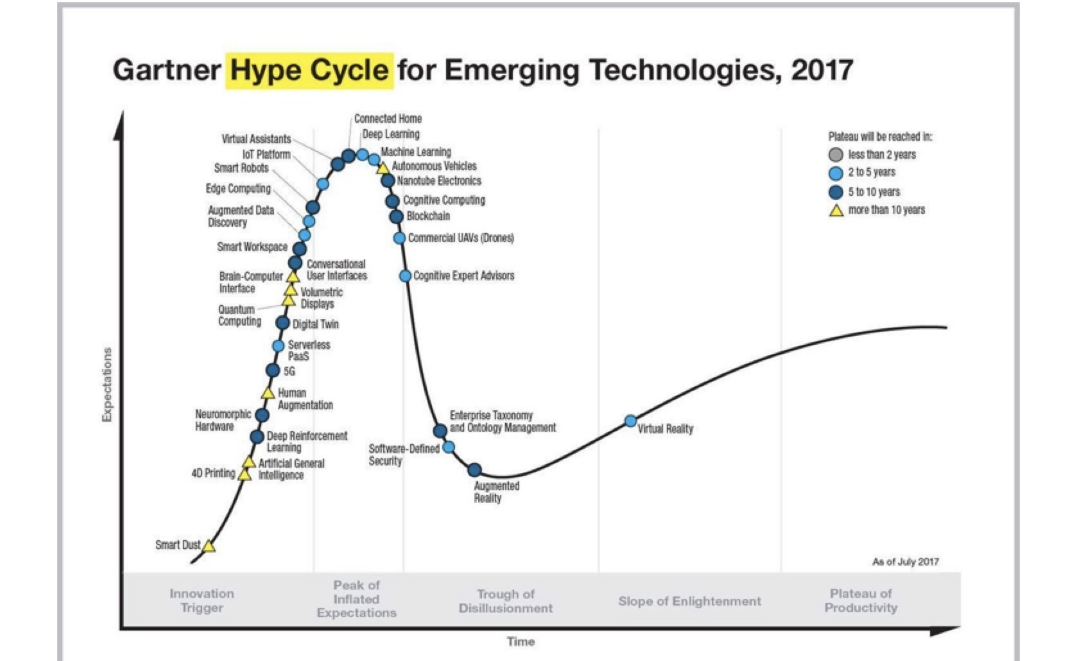
另外基于 Kubernetes 的构建 PaaS 平台和 Serverless 也处于爆发的准备的阶段,如下图中 Gartner 的报告中所示:
2017 年时各大公有云如 Google GKE、微软 Azure ACS、亚马逊 EKS(2018 年上线)、VMware、Pivotal(后被VMware 收购)、腾讯云、阿里云等都提供了 Kubernetes 服务。
微服务
下图列出了微服务所需关心的主题,图片来自RedHat Developers。
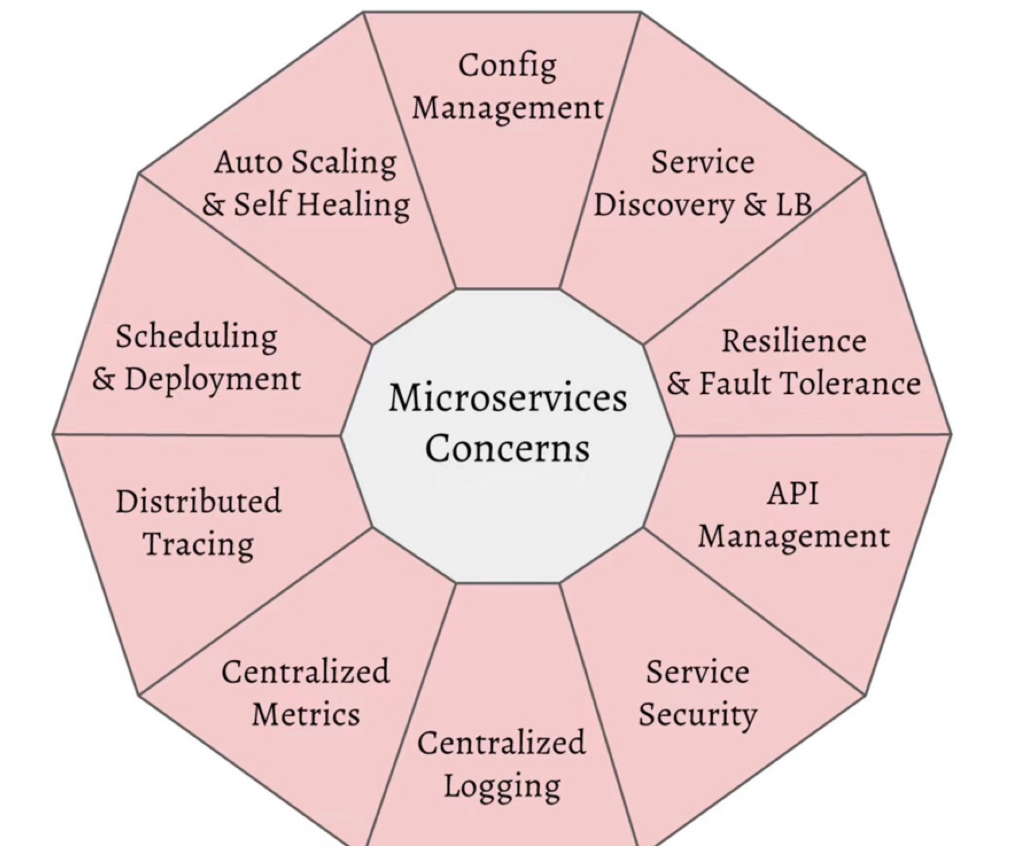
微服务带给我们很多开发和部署上的灵活性和技术多样性,但是也增加了服务调用的开销、分布式系统管理、调试与服务治理方面的难题。
当前最成熟最完整的微服务框架可以说非 Spring 莫属,而 Spring 又仅限于 Java 语言开发,其架构本身又跟 Kubernetes 存在很多重合的部分,如何探索将 Kubernetes 作为微服务架构平台就成为一个热点话题。
就拿微服务中最基础的服务注册发现功能来说,其方式分为客户端服务发现和服务端服务发现两种,Java 应用中常用的方式是使用 Eureka 和 Ribbon 做服务注册发现和负载均衡,这属于客户端服务发现,而在 Kubernetes 中则可以使用 DNS、Service 和 Ingress 来实现,不需要修改应用代码,直接从网络层面来实现。
微服务中的2种服务发现方式

服务网格
Kubernetes 中的应用将作为微服务运行,但是 Kubernetes 本身并没有给出微服务治理的解决方案,比如服务的限流、熔断、良好的灰度发布支持等。
Service Mesh 可以用来做什么
- Traffic Management:API 网关
- Observability:服务调用和性能分析
- Policy Enforcment:控制服务访问策略
- Service Identity and Security:安全保护
Service Mesh 的特点
- 专用的基础设施层
- 轻量级高性能网络代理
- 提供安全的、快速的、可靠地服务间通讯
- 扩展 kubernetes 的应用负载均衡机制,实现灰度发布
- 完全解耦于应用,应用可以无感知,加速应用的微服务和云原生转型
都有哪些Service Mesh
使用 Service Mesh 将可以有效的治理 Kubernetes 中运行的服务,当前开源的流行的 Service Mesh 有:
- Linkerd:由最早提出 Service Mesh 的公司 Buoyant 开源,创始人来自 Twitter
- Envoy:由 Lyft 开源,可以在 Istio 中使用 Sidecar 模式运行以作为数据平面,也可以基于它来构建自己的服务网格
- Istio:由 Google、IBM、Lyft 联合开发并开源
Istio VS Linkerd
Linkerd 和 Istio 是最早开源的 Service Mesh,它们都支持 Kubernetes,下面是它们之间的一些特性对比。
| Feature | Istio | Linkerd |
|---|---|---|
| 部署架构 | Envoy/Sidecar | DaemonSets |
| 易用性 | 复杂 | 简单 |
| 支持平台 | Kubernetes | Kubernetes/Mesos/Istio/Local |
| 是否已有生产部署 | 是 | 是 |
Istio 的组件复杂,可以分别部署在 Kubernetes 集群中,但是作为核心路由组件 Envoy 是以 Sidecar 形式与应用运行在同一个 Pod 中的,所有进入该 Pod 中的流量都需要先经过 Envoy。
Linker 的部署十分简单,本身就是一个镜像,使用 Kubernetes 的 DaemonSet 方式在每个 node 节点上运行。
使用场景
GitOps
我们知道 Kubernetes 中的所有应用的部署都是基于YAML文件的,这实际上就是一种 Infrastructure as code,完全可以通过 Git 来管控基础设施和部署环境的变更。
大数据
Spark 现在已经非官方支持了基于 Kubernetes 的原生调度,其具有以下特点:
- Kubernetes 原生调度:与 yarn、mesos 同级
- 资源隔离,粒度更细:以 namespace 来划分用户
- 监控的变革:单次任务资源计量
- 日志的变革:pod 的日志收集
| 特性 | Yarn | Kubernetes |
|---|---|---|
| 队列 | queue | namespace |
| 实例 | ExcutorContainer | Executor Pod |
| 网络 | host | plugin |
| 异构 | no | yes |
| 安全 | RBAC | ACL |
下图是在 Kubernetes 上运行三种调度方式的 spark 的单个节点的应用部分对比:

从上图中可以看到在 Kubernetes 上使用 YARN 调度、standalone 调度和 Kubernetes 原生调度的方式,每个 node 节点上的 Pod 内的 Spark Executor 分布,毫无疑问,使用 Kubernetes 原生调度的 Spark 任务才是最节省资源的。
开源
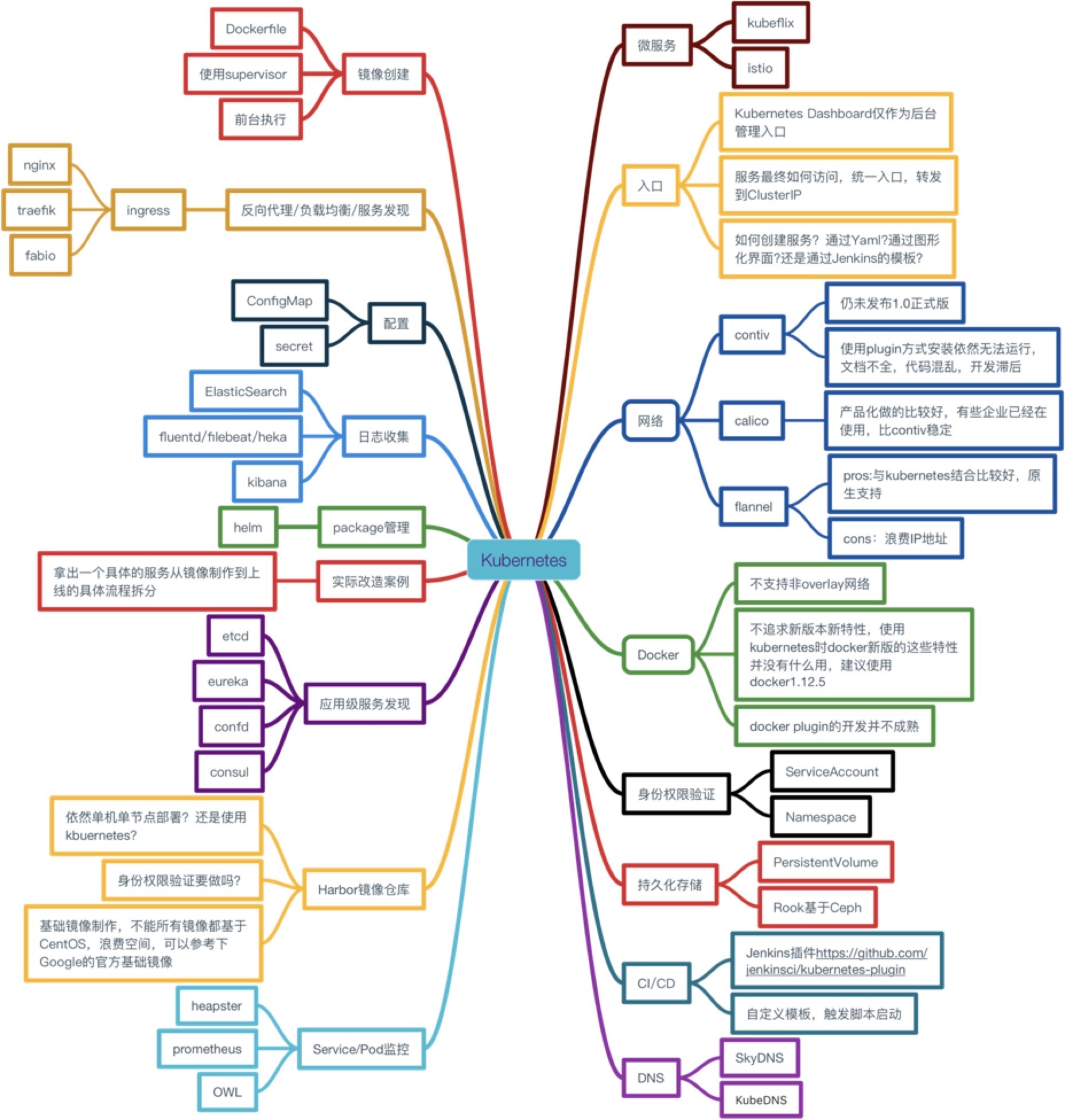
对于一个初次接触 Kubernetes 的人来说,看到这样一个庞大的架构选型时会望而生畏,但是 Kubernetes 的开源社区帮助了我们很多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号