AIOps探索:告警事件关联分析
背景
近年来互联网技术高速发展,接入监控告警的设备和业务也越来越多,不断增新的设备和业务使得告警的量级也逐级递加。各种软硬件模块每天会产生大量的告警信息,这些告警中有表象告警,有冗余告警,也有根因告警。每次故障出现都会引发一系列错综叠加的告警,从而将根因告警淹没在里面,导致故障识别异常困难。一般告警分析主要是靠运维人员进行处理,当告警出现时,常常要求运维人员必须在最短的时间内,正确地判断出告警中存在的关联性,然后根据自己的经验采取相应的措施。
关联规则生成
传统的规则关联:以网络的告警关联为例,一般是通过网管专家梳理告警关联规则后,再对一系列告警进行关联规则匹配。但这种做法由于网络的复杂性,设备变化的高频性和网元连接经常变化等特点,人工经验建立的关联关系存在规则覆盖不全,不能适应网络变化等问题。
基于机器学习的告警关联:通过算法能够从大量的、低价值密度、有噪声的数据中提取出有价值的告警关联信息,动态的获取事件的关联关系,辅助运维人员决策。
概念的区分:
故障和告警是运维场景中两个不同的概念,故障是网络运行中的异常状态,故障都需要维护人员进行及时处理。告警是网络设备发生特定事件后的事件通报,告警只是表明可能有故障发生,但并不是一定有故障发生。故障发生后会引发一系列的告警。一个故障还可能引发其他故障,从而引起告警风暴的出现。一般告警可以分为以下几类:
表象告警:故障造成的结果告警,往往看不出根源,需要运维人员进行进一步分析
冗余告警:同一告警在某一时间段内的重复告警,或者一些不重要的周期性告警
根因告警:往往是造成故障的原因的告警
波动告警:因指标波动造成的一类告警,通常不涉及到故障的发生
什么是告警关联分析:
告警关联分析就是对一次故障中产生的一系列告警进行压缩和根因识别的手段。
为什么要做告警关系分析:
对故障根因进行准确定位,提升故障处理效率,并对冗余告警进行压缩,减少故障工单派发量,从而减轻运维人员的故障处理负担。
如何去做基于机器学习的告警关联分析:
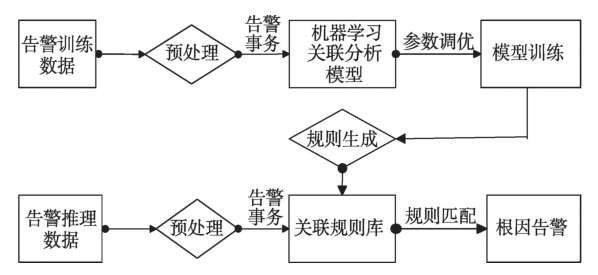
一般的做法(如下图):
- 针对告警事件的特点对历史告警数据进行预处理,生成告警事务数据;、
- 然后选择合适的告警关联分析算法,对告警事务数据进行训练,通过对模型的参数调优,生成告警关联规则并得到关联则库。
- 在推理阶段,将需要推理的告警通过预处理后与关联规则库中告警关联规则进行匹配,确定根因告警。
告警数据的特点:
- 属性多:一条告警有多达十个个乃至几十个字段,而其中很多与告警关联并没有重要联系
- 时间不同步:不同告警设备可能未同步时间,同步时间后时钟同步程序故障也会造成时钟不统一的问题
- 不完整性:由于人为或者网络设备自身的原因可能导致上报的告警数据不完整,另一方面由于备故障或者链路中断等故障,也会导致告警可能没有完整上报。
- 冗余性:故障发生时,多个设备可能产生同一种告警,引起的连锁故障也会造成一系列告警,最终形成告警风暴,很多表象告警会导致根源告警不能被及时发现。
步骤
数据预处理:
常规处理:
- 提取对告警关联分析有重要作用的关键字段
- 剔除部分次要级别的告警以及同一时间段重复类型的告警
- 去除告警时间明显异常的告警
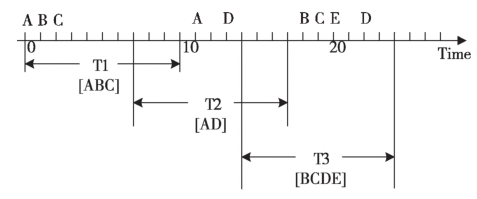
告警事件提取:告警事件,即每次故障事件所产生的一系列告警的集合,这是算法输入的必要形式,一般采取滑动时间窗的形式生成告警事件,滑动时间窗步长的取值可以根据告警的实际情况按告警事件的时间分布,取90分位数。告警事件的质量和数量与滑动窗口宽度和步长的设置息息相关,而告警事件作为算法的输入则对算法的效果起到重要的作用。如下图示例:ABCDE为告警数据,滑动窗口宽度为12,步长为7 ,通过3个滑动窗口分别得到了 3个告警事件[T1,T2,T3]。
告警权重评估:一般而言,重要的告警发生的频率较低,而不重要的告警发生频率很高。因此在进行告警关联分析时不能将告警看作平等的对象,需要对重要性不同的告警设置不同的权重,这里按照告警级别、告警节点重要程度对告警进行加权求和。当然该方法具有较强的主观性,需要结合人工经验去设定。
告警拓扑分布:在进行告警事务提取时不仅需要考虑时间的因素,还需要考虑空间或者网络拓扑的限制条件,比如根据地域或者子网范围等,同一地域/范围内的告警才可能是一类告警事件。进行此类过滤可以使后续的关联分析结果更加准确,但同时也会增加算法的复杂度。
告警关系挖掘:
本文采用的是主流的无序关联分析算法:FP-Growth,该算法的作用是找到项集数据中的频繁项,并生成关联规则,较于Apriori算法具有更高的效率。项集就是同时出现的一组项目的集合,在告警关联分析中,一个告警事件就可以看作是一个项集,项集的频率就是支持度,项集A的支持度与项集B的支持度的比值叫做置信度,它定义了关联规则的可靠程度。提升度能够反映关联规则的相关性程度,提升度大于1表示正相关,越大表示正相关性程度越高,提升度小于1表示负相关,越小负相关度程度越高,提升度等于1表示不相关。
支持度:(X→Y) = P(X,Y) / P(I) = P(X∪Y) / P(I) = num(XUY) / num(I)
置信度:(X→Y) = P(Y|X) = P(X,Y) / P(X) = P(XUY) / P(X)
提升度:(X→Y) = P(Y|X) / P(Y)
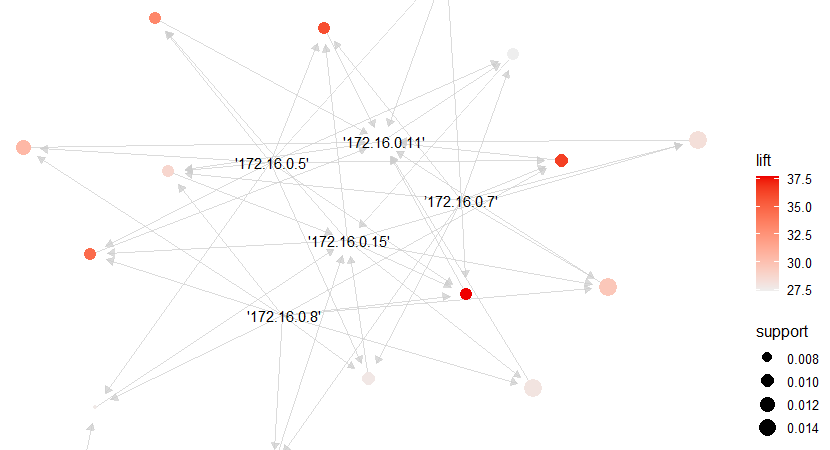
离线挖掘关联关系:当我们将历史告警事件输入算法后,按照这三个指标进行关联关系的过滤,最终形成一个强相关的图。再通过社区发现算法(如Louvain、LPA、Infomap等)将关联图划分为不同社区。
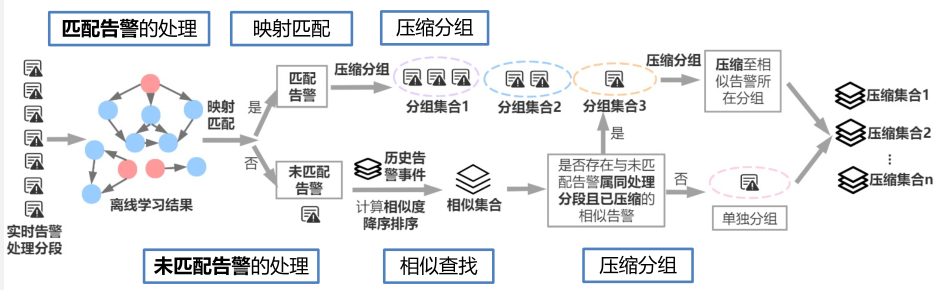
在线推断压缩告警:我们同样将待推断的告警生成告警事件,通过PR方法来计算各个告警的得分,推断出此告警事件的根因告警。通过遍历与每个社区告警事件的相似度,将此类告警划入社区,实现告警压缩。
补充
对于关联规则的生成需要对大量的历史告警进行预处理和算法生成的步骤,这通常会花费不少时间,影响实际使用时对算法实时性的要求,通过蓝鲸计算平台的大数据分布式处理方法,我们可以快速处理海量告警数据,满足实际应用的实时需求,快速生成最新最全的关联规则。
对于设备变化没有那么频繁,或者每次设备变化都能及时更新到CMDB中的运维系统而言,可以省略离线的关联挖掘,直接使用最新的设备关联拓扑进行在线的告警压缩和根因推断,同样也可以取得不错的效果。蓝鲸统一告警中心实现了对接CMDB设备拓扑的关联分析,告警可以在通过设备的拓扑图进行查看,辅助运维人员快速找到根因告警。【插入统一告警中心的介绍】
总结
告警来源的设备十分复杂,每天都可能产生大量的告警,其中有根源告警也有表象告警。通过基于AIOps的告警关联分析对告警进行关系挖掘,可以帮助运维人员对告警进行压缩并快速定位根因,对于故障的排查和管理具有十分重要的意义。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号