hadoop高可用
前言
hdfs元数据是保存在namenode节点的,由于元数据有一定的格式,写入元数据比较慢,所以使用了追加的方式,即将操作记录都写在一个文件中,然后由别的机器进进程行将记录转换成元数据(合并元数据),这样对于namenode来讲,只需要写入操作记录即可,速度便快了很多,而这个合并元数据的进程为secondaryNameNode
secondaryNamenode的工作原理如链接:https://www.cnblogs.com/yinzhengjie/p/10679254.html
即便这样,还是由一些问题
1.单点问题 当namenode 挂掉之后,整个集群就挂了
解决方案:多个namenode,借助zookeeper实现leader选举,namenode所在的节点会有一个DFSZKFailvoerCotroller进程,同时为了让两台namenode之间的元数据一致,namenode节点会启动JournalNode服务
处于Ativity状态的节点,将日志写入共享文件系统,处于Standby的NameNode读取日志文件。

2.元数据太多了,启动一次太浪费时间
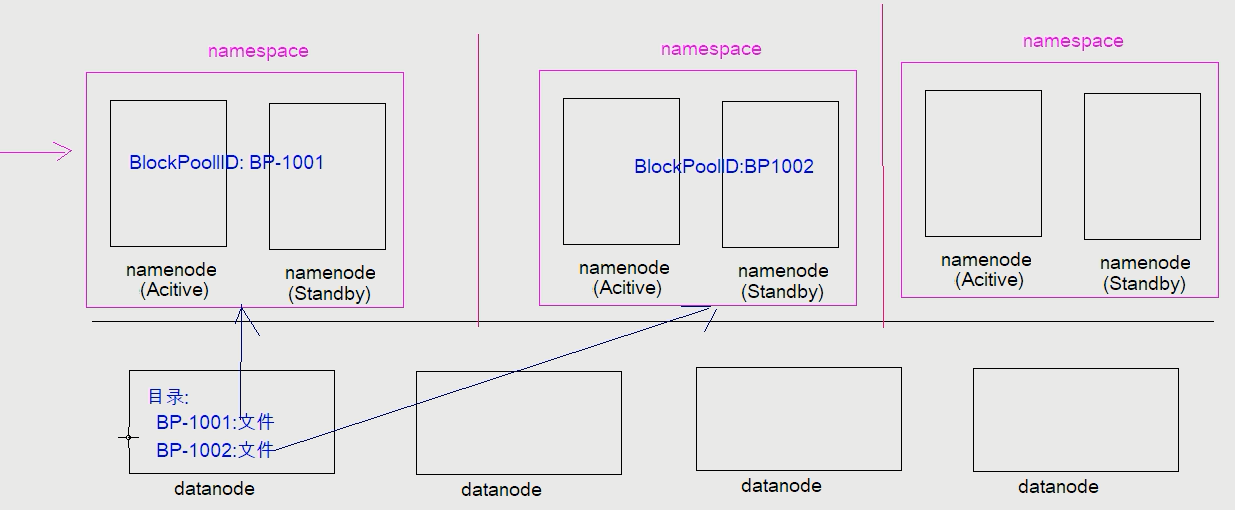
解决方案:联邦机制
将NameNode划分成不同的命名空间并进行编号。不同的命名空间之间相互隔离互不干扰。在DataNode中创建目录,此目录对应命名空间的编号。由此,编号相同的数据由对应的命名空间进行管理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号