Python中结巴分词使用手记
手记实用系列文章:
3 自然语言处理手记
结巴分词方法封装类
from __future__ import unicode_literals
import sys
sys.path.append("../")
import jieba
import jieba.posseg
import jieba.analyse
print('='*40)
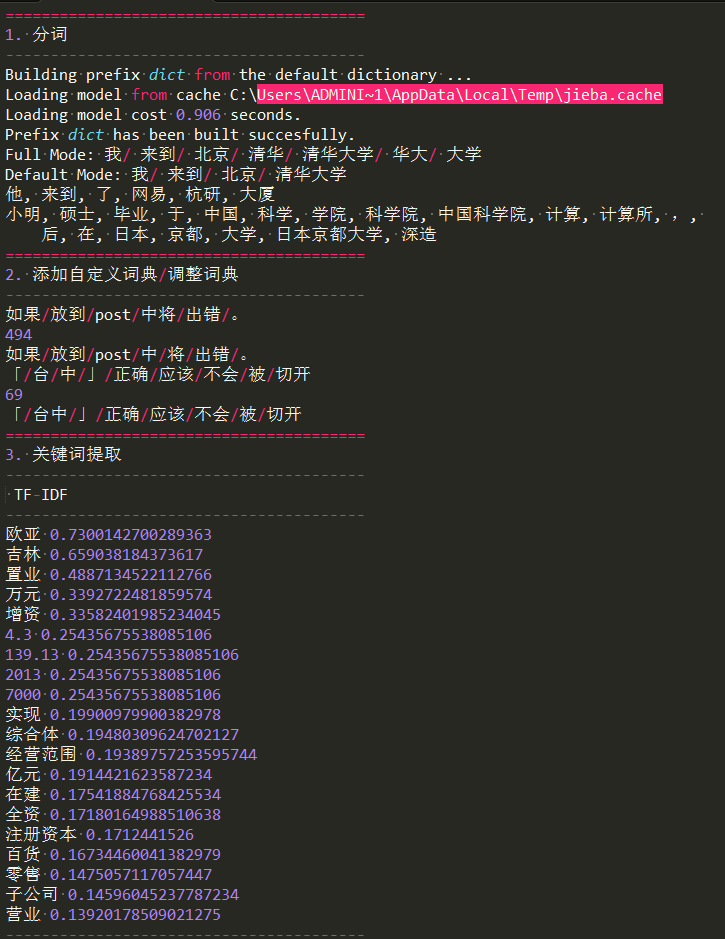
print('1. 分词')
print('-'*40)
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 默认模式
seg_list = jieba.cut("他来到了网易杭研大厦")
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
print('='*40)
print('2. 添加自定义词典/调整词典')
print('-'*40)
print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
#如果/放到/post/中将/出错/。
print(jieba.suggest_freq(('中', '将'), True))
#494
print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
#如果/放到/post/中/将/出错/。
print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
#「/台/中/」/正确/应该/不会/被/切开
print(jieba.suggest_freq('台中', True))
#69
print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
#「/台中/」/正确/应该/不会/被/切开
print('='*40)
print('3. 关键词提取')
print('-'*40)
print(' TF-IDF')
print('-'*40)
s = "此外,公司拟对全资子公司吉林欧亚置业有限公司增资4.3亿元,增资后,吉林欧亚置业注册资本由7000万元增加到5亿元。吉林欧亚置业主要经营范围为房地产开发及百货零售等业务。目前在建吉林欧亚城市商业综合体项目。2013年,实现营业收入0万元,实现净利润-139.13万元。"
for x, w in jieba.analyse.extract_tags(s, withWeight=True):
print('%s %s' % (x, w))
print('-'*40)
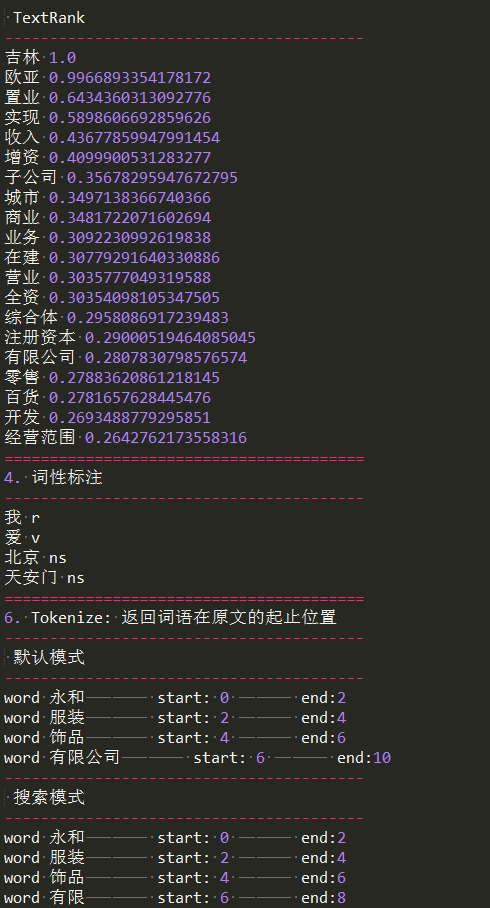
print(' TextRank')
print('-'*40)
for x, w in jieba.analyse.textrank(s, withWeight=True):
print('%s %s' % (x, w))
print('='*40)
print('4. 词性标注')
print('-'*40)
words = jieba.posseg.cut("我爱北京天安门")
for word, flag in words:
print('%s %s' % (word, flag))
print('='*40)
print('6. Tokenize: 返回词语在原文的起止位置')
print('-'*40)
print(' 默认模式')
print('-'*40)
result = jieba.tokenize('永和服装饰品有限公司')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
print('-'*40)
print(' 搜索模式')
print('-'*40)
result = jieba.tokenize('永和服装饰品有限公司', mode='search')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
结巴分词的运行结果
作者:白宁超,工学硕士,现工作于四川省计算机研究院,研究方向是自然语言处理和机器学习。曾参与国家自然基金项目和四川省科技支撑计划等多个省级项目。著有《自然语言处理理论与实战》一书。 自然语言处理与机器学习技术交流群号:436303759 。
出处:http://www.cnblogs.com/baiboy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号