dubbo负载均衡
dubbo
一.同一个dubbo生产者服务怎么分布在不同服务器,且能进行负载均衡?
只要两个服务的id,接口,实现类一致(且dubbo:application名称一致,表示同一应用),注册到同一zookeeper。
Dubbo 定义了集群接口 Cluster 以及 Cluster Invoker。集群 Cluster 用途是将多个服务提供者合并为一个 Cluster Invoker,并将这个 Invoker 暴露给服务消费者。这样一来,服务消费者只需通过这个 Invoker 进行远程调用即可。
此时,消费者调用接口时,是一个可简单类比为 List
二.负载均衡(LoadBalance )
所有负载均衡算法继承AbstractLoadBalance。
执行过程:
1.执行select():首先会检测 invokers 集合的合法性,然后再检测 invokers 集合元素数量。如果只包含一个 Invoker,直接返回该 Inovker 即可。如果包含多个 Invoker,此时需要通过负载均衡算法doSelect()选择一个 Invoker。
2.执行doSelect():抽象方法,根据实现类的不同,实现不同方式负载均衡。
3.执行getWeight():每个抽象方法都需要获得权重(公共逻辑)。权重初始状态并非完全是配置的那样,还根据服务运行时间有关。
服务预热是一个优化手段,与此类似的还有 JVM 预热。主要目的是让服务启动后“低功率”运行一段时间,使其效率慢慢提升至最佳状态。
1.RandomLoadBalance加权随机
顾名思义,就是分配权值,随机将请求落在相应的权值区间。将Invoker按顺序排列。
int ran=Random.nextInt(allInvokeWeight);//取随机数,在权值范围
for (int i=0;i<Invoker.length;ii++{
ran-=Invoker.get(i).getWeight;
if (ran < 0){
return Invoker.get(i)//命中该区域
}
}
2.LeastActiveLoadBalance最小活跃数负载均衡
为什么是最小活跃数?每个请求服务时,活跃数就会+1,而处理完一个请求就会-1。所以最小活跃数的机器可以认为是处理能力很强,或者比较空闲的机器。但是此算法也还是跟权值有关,是基于加权最小活跃数算法实现的。算法过程:
- 遍历 invokers 列表,寻找活跃数最小的 Invoker
- 如果有多个 Invoker 具有相同的最小活跃数,此时记录下这些 Invoker 在 invokers 集合中的下标,并累加它们的权重,比较它们的权重值是否相等
- 如果只有一个 Invoker 具有最小的活跃数,此时直接返回该 Invoker 即可
- 如果有多个 Invoker 具有最小活跃数,且它们的权重不相等,此时处理方式和 RandomLoadBalance 一致
- 如果有多个 Invoker 具有最小活跃数,但它们的权重相等,此时随机返回一个即可
(简单来说找活跃最小的,活跃一致且权重不一致按随机权重,活跃一致权重一致则随机一个)
3.ConsistentHashLoadBalance一致性 hash 算法
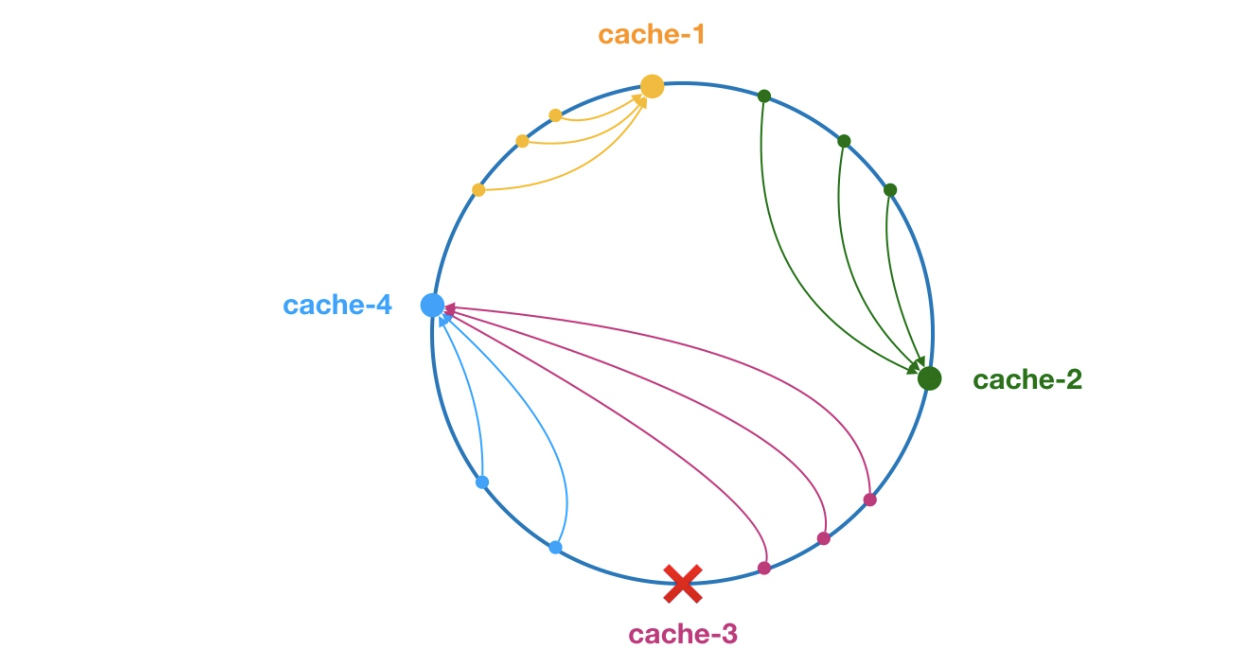
每个Invoke生成(根据ip或者其他信息)一个hash值,落在一个环形区域。每个消费者请求也会生成一个hash值,对于每个请求hash都会被大于他们的invoke的hash值命中。如果当前节点挂了,则在下一次查询或写入缓存时,为缓存项查找另一个大于其 hash 值的缓存节点即可。这样就可以完成负载分配了,但是还有一个问题,均衡?这样生成的invoke的hash值,并不能控制谁的区域大,谁的区域小。出现数据倾斜。
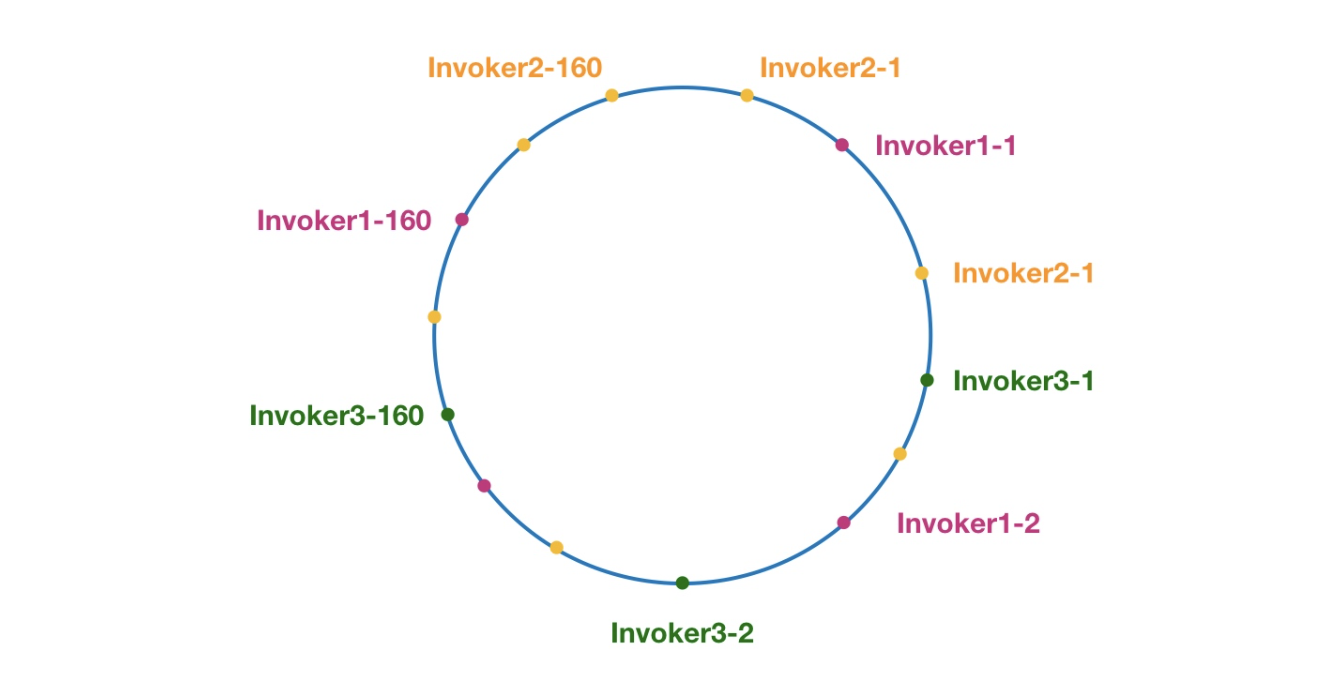
这里相同颜色的节点均属于同一个服务提供者,比如 Invoker1-1,Invoker1-2,……, Invoker1-160。这样做的目的是通过引入虚拟节点,让 Invoker 在圆环上分散开来,避免数据倾斜问题。(相当于通过增加多个虚拟节点,来控制命中范围)
4.RoundRobinLoadBalance加权轮询负载均衡
比如服务器 A、B、C 权重比为 5:2:1。那么在8次请求中,服务器 A 将收到其中的5次请求,服务器 B 会收到其中的2次请求,服务器 C 则收到其中的1次请求。(和随机不一样,这里就相当于明确了每个机器的命中,按顺序进行)
三.网络协议
长连接:避免频繁创建线程进行连接。
| 协议名称 | 实现描述 | 连接 | 使用场景 |
|---|---|---|---|
| dubbo | 传输:mina、netty、grizzy 序列化:dubbo、hessian2、java、json | dubbo缺省采用单一长连接和NIO异步通讯 | 1.适合于小数据量大并发的服务调用 2.消费者 比提供者多 3.不适合传送大数据量的服务,比如文件、传视频 |
| rmi | 传输:java rmi 序列化:java 标准序列化 | 连接个数:多连接 连接方式:短连接 传输协议:TCP/IP 传输方式:BIO | 1.常规RPC调用 2.与原RMI客户端互操作 3.可传文件 4.不支持防火墙穿透 |
| hessian | 传输:Serverlet容器 序列化:hessian二进制序列化 | 连接个数:多连接 连接方式:短连接 传输协议:HTTP 传输方式:同步传输 | 1.提供者比消费者多 2.可传文件 3.跨语言传输 |
| http | 传输:servlet容器 序列化:表单序列化 | 连接个数:多连接 连接方式:短连接 传输协议:HTTP 传输方式:同步传输 | 1.提供者多余消费者 2.数据包混合 |
| webservice | 传输:HTTP 序列化:SOAP文件序列化 | 连接个数:多连接 连接方式:短连接 传输协议:HTTP 传输方式:同步传输 | 1.系统集成 2.跨语言调用 |
| thrift | 与thrift RPC实现集成,并在基础上修改了报文头 | 长连接、NIO异步传输 |
一直有个疑问?啥叫序列化?
序列化是指,将对象进行某种格式(二进制,json等)序列化,在网络上进行传输,然后进行反序列化成对象。
实现了Serizalible接口,并不能序列化,仅仅只是标记了你可以序列化。真正的序列化还是需要自己实现,如java序列化:
通过ObjectOutputStream,ObjectInputStream,进行java类的序列化。
所以dubbo支持的序列化,就是在传输的时候,使用配置好的序列化协议,例如hessian2。
三. Dubbo SPI 示例(增强javaSPI)
Dubbo 并未使用 Java SPI,而是重新实现了一套功能更强的 SPI 机制。Dubbo SPI 的相关逻辑被封装在了 ExtensionLoader 类中,通过 ExtensionLoader,我们可以加载指定的实现类。Dubbo SPI 所需的配置文件需放置在 META-INF/dubbo 路径下,配置内容如下。
optimusPrime = org.apache.spi.OptimusPrime
bumblebee = org.apache.spi.Bumblebee
与 Java SPI 实现类配置不同,Dubbo SPI 是通过键值对的方式进行配置,这样我们可以按需加载指定的实现类。另外,在测试 Dubbo SPI 时,需要在 Robot 接口上标注 @SPI 注解。下面来演示 Dubbo SPI 的用法:
public class DubboSPITest {
@Test
public void sayHello() throws Exception {
ExtensionLoader<Robot> extensionLoader =
ExtensionLoader.getExtensionLoader(Robot.class);
Robot optimusPrime = extensionLoader.getExtension("optimusPrime");//可以获得明确的实现类
optimusPrime.sayHello();
Robot bumblebee = extensionLoader.getExtension("bumblebee");
bumblebee.sayHello();
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号