

用DirectX12绘制一个Cube
之前一篇文章讲了DirectX12的初始化流程,现在来看看在此基础上如何绘制一个Cube。
首先,我们要为这个Cube准备一个shader,来告诉GPU绘制的具体流程,DirectX中的shader使用的是hlsl:
cbuffer cbPerObject : register(b0)
{
float4x4 gWorldViewProj;
};
struct VertexIn
{
float4 Color : COLOR;
float3 PosL : POSITION;
};
struct VertexOut
{
float4 PosH : SV_POSITION;
float4 Color : COLOR;
};
VertexOut VS(VertexIn vin)
{
VertexOut vout;
vout.PosH = mul(float4(vin.PosL, 1.0f), gWorldViewProj);
vout.Color = vin.Color;
return vout;
}
float4 PS(VertexOut pin) : SV_Target
{
return pin.Color;
}
这个shader做的事情很简单,就是单纯输出顶点设置的颜色。注意到里面有一个cbuffer,这是用来接收来自外部的参数的,例如这里需要把world-view-projection矩阵传进来计算顶点经过投影变换后的位置。为了实现这一步,我们需要创建一个const buffer用来保存传递数据:
mDevice->CreateCommittedResource(&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD),
D3D12_HEAP_FLAG_NONE, &CD3DX12_RESOURCE_DESC::Buffer(cbSize),
D3D12_RESOURCE_STATE_GENERIC_READ,
nullptr, IID_PPV_ARGS(&mConstBuffer));
这里指定了buffer的用途,是上传数据给shader读取用的。另外,根据DirectX的约定,const buffer的大小必须为256的整数倍,也即这里的cbSize是256的整数倍。可以通过下面这个函数来计算一个合法的const buffer大小值:
static UINT CalcConstantBufferByteSize(UINT byteSize)
{
return (byteSize + 255) & ~255;
}
由于buffer中的数据可能会频繁更新,这里使用Map和UnMap组合来上传数据:
mConstBuffer->Map(0, nullptr, &mConstBufferData);
XMMATRIX world = XMLoadFloat4x4(&object->mWorldMatrix);
XMMATRIX view = XMLoadFloat4x4(&camera->mViewMatrix);
XMMATRIX proj = XMLoadFloat4x4(&camera->mProjMatrix);
XMMATRIX worldViewProj = world * view * proj;
ObjectConstants objConstants;
XMStoreFloat4x4(&objConstants.WorldViewProj, XMMatrixTranspose(worldViewProj));
memcpy(mConstBufferData, &objConstants, sizeof(ObjectConstants));
mConstBuffer->Unmap(0, nullptr);
这里只需要一个矩阵给shader,因此ObjectConstants就是只包含一个矩阵的简单结构体。值得一提的是,shader读取const buffer是按列主序来读取的,所以这里要对矩阵先进行转置,再传递给shader。
有了const buffer之后,我们需要为之创建一个view和存放view的heap:
D3D12_DESCRIPTOR_HEAP_DESC cbvHeapDesc;
cbvHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV;
cbvHeapDesc.NumDescriptors = 1;
cbvHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_SHADER_VISIBLE;
cbvHeapDesc.NodeMask = 0;
mDevice->CreateDescriptorHeap(&cbvHeapDesc, IID_PPV_ARGS(&mCbvHeap));
D3D12_CONSTANT_BUFFER_VIEW_DESC cbvDesc;
cbvDesc.BufferLocation = mConstBuffer->GetGPUVirtualAddress();
cbvDesc.SizeInBytes = cbSize;
CD3DX12_CPU_DESCRIPTOR_HANDLE handle = CD3DX12_CPU_DESCRIPTOR_HANDLE(
mCbvHeap->GetCPUDescriptorHandleForHeapStart());
mDevice->CreateConstantBufferView(&cbvDesc, handle);
接下来,为了告诉CPUshader读取的位置是在register(b0),我们需要设置root signature。这里使用DescriptorTable的形式进行初始化:
CD3DX12_DESCRIPTOR_RANGE cbvTable;
cbvTable.Init(D3D12_DESCRIPTOR_RANGE_TYPE_CBV, 1, 0);
CD3DX12_ROOT_PARAMETER rootParams[1];
rootParams[0].InitAsDescriptorTable(1, &cbvTable);
CD3DX12_ROOT_SIGNATURE_DESC sigDesc(1, rootParams, 0, nullptr,
D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT);
ComPtr<ID3DBlob> signature = nullptr;
ComPtr<ID3DBlob> error = nullptr;
HRESULT hr = D3D12SerializeRootSignature(&sigDesc, D3D_ROOT_SIGNATURE_VERSION_1, &signature, &error);
if (error == nullptr)
{
mDevice->CreateRootSignature(0, signature->GetBufferPointer(), signature->GetBufferSize(),
IID_PPV_ARGS(&mRootSignature));
}
跟const buffer相关的设置就到此为止了。现在,让我们考虑要传给shader的顶点数据,根据传入vertex shader的参数类型,我们需要创建与之相匹配的顶点数据结构和input layout。这里我们对顶点数据结构进行了拆分,即一个只包含顶点的位置数据,一个则包含除此之外的其他数据,这样做一定程度可以减少带宽,可以做到只传输必要的数据给GPU。相应地,input layout里就包含了两个slot:
struct VertexPos
{
XMFLOAT3 position;
};
struct VertexProp
{
XMFLOAT4 color;
...
};
mInputLayout =
{
{"POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0},
{"COLOR", 0, DXGI_FORMAT_R32G32B32A32_FLOAT, 1, 0, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0}
};
有了数据结构之后,我们就可以根据数据结构去创建顶点缓存和索引缓存了。我们预先创建一个全局的顶点缓存和索引缓存,以及对应的view,之后就可以将能合并的object数据拷贝过去:
mDevice->CreateCommittedResource(&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD),
D3D12_HEAP_FLAG_NONE, &CD3DX12_RESOURCE_DESC::Buffer(
mVertexBufferSize * sizeof(VertexPos)),
D3D12_RESOURCE_STATE_GENERIC_READ, nullptr, IID_PPV_ARGS(&mPosVertexBufferGPU)));
mVertexBufferViews[0].BufferLocation = mPosVertexBufferGPU->GetGPUVirtualAddress();
mVertexBufferViews[0].SizeInBytes = mVertexBufferSize * sizeof(VertexPos);
mVertexBufferViews[0].StrideInBytes = sizeof(VertexPos);
mDevice->CreateCommittedResource(&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD),
D3D12_HEAP_FLAG_NONE, &CD3DX12_RESOURCE_DESC::Buffer(
mVertexBufferSize * sizeof(VertexProp)),
D3D12_RESOURCE_STATE_GENERIC_READ, nullptr, IID_PPV_ARGS(&mPropVertexBufferGPU)));
mVertexBufferViews[1].BufferLocation = mPropVertexBufferGPU->GetGPUVirtualAddress();
mVertexBufferViews[1].SizeInBytes = mVertexBufferSize * sizeof(VertexProp);
mVertexBufferViews[1].StrideInBytes = sizeof(VertexProp);
mDevice->CreateCommittedResource(&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD),
D3D12_HEAP_FLAG_NONE, &CD3DX12_RESOURCE_DESC::Buffer(mIndexBufferSize * sizeof(UINT)),
D3D12_RESOURCE_STATE_GENERIC_READ, nullptr, IID_PPV_ARGS(&mIndexBufferGPU)));
mIndexBufferView.BufferLocation = mIndexBufferGPU->GetGPUVirtualAddress();
mIndexBufferView.Format = DXGI_FORMAT_R32_UINT;
mIndexBufferView.SizeInBytes = mIndexBufferSize * sizeof(UINT);
拷贝object数据时,需要记住全局buffer当前可写入位置的指针偏移,以及对应的偏移index,例如:
ThrowIfFailed(mPosVertexBufferGPU->Map(0, nullptr, &mPosVertexBufferData));
memcpy((BYTE *)mPosVertexBufferData + mPosVertexBufferOffset, data, byteWidth);
mPosVertexBufferGPU->Unmap(0, nullptr);
mBaseVertexLocation = mPosVertexBufferOffset / sizeof(VertexPos);
mPosVertexBufferOffset += byteWidth;
这些偏移量是用来后面绘制不同object时找到正确的读取数据位置用的。具体描述一个cube的vertex和index数据这里就不贴了。
如果为每个object单独创建一份顶点缓存和索引缓存的话,可以在创建的时候就把数据塞进去。这样只需要初始化一次,后面就只有读取的操作了,满足这样条件的buffer需要设置为D3D12_HEAP_TYPE_DEFAULT。为default buffer拷贝数据需要使用一个额外的upload buffer来完成:
ID3DBlob *bufferCPU = nullptr;
D3DCreateBlob(byteWidth, &bufferCPU);
CopyMemory(bufferCPU->GetBufferPointer(), data, byteWidth);
mDevice->CreateCommittedResource(&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD),
D3D12_HEAP_FLAG_NONE, &CD3DX12_RESOURCE_DESC::Buffer(byteWidth),
D3D12_RESOURCE_STATE_GENERIC_READ,
nullptr, IID_PPV_ARGS(uploadBuffer));
mDevice->CreateCommittedResource(&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT),
D3D12_HEAP_FLAG_NONE, &CD3DX12_RESOURCE_DESC::Buffer(byteWidth), D3D12_RESOURCE_STATE_COMMON,
nullptr, IID_PPV_ARGS(defaultBuffer));
mCommandAlloc->Reset();
mCommandList->Reset(mCommandAlloc.Get(), nullptr);
mCommandList->ResourceBarrier(1,
&CD3DX12_RESOURCE_BARRIER::Transition(*defaultBuffer,
D3D12_RESOURCE_STATE_COMMON, D3D12_RESOURCE_STATE_COPY_DEST));
D3D12_SUBRESOURCE_DATA subResourceData;
subResourceData.pData = data;
subResourceData.RowPitch = byteWidth;
subResourceData.SlicePitch = byteWidth;
UpdateSubresources<1>(mCommandList.Get(), *defaultBuffer, *uploadBuffer, 0, 0, 1, &subResourceData);
mCommandList->ResourceBarrier(1,
&CD3DX12_RESOURCE_BARRIER::Transition(*defaultBuffer,
D3D12_RESOURCE_STATE_COPY_DEST, D3D12_RESOURCE_STATE_GENERIC_READ));
mCommandList->Close();
ID3D12CommandList *cmdList[] = { mCommandList.Get() };
mCommandQueue->ExecuteCommandLists(_countof(cmdList), cmdList);
至此,和顶点缓存索引缓存相关的操作就完成了。下面让我们回到最开始提到的shader,编写完shader之后还需要去编译它,这里我们选择在线编译的模式:
UINT compileFlags = 0;
#if defined(DEBUG) || defined(_DEBUG)
compileFlags = D3DCOMPILE_DEBUG | D3DCOMPILE_SKIP_OPTIMIZATION;
#endif
ID3DBlob *error = nullptr;
HRESULT hr;
hr = D3DCompileFromFile(srcFile.c_str(), nullptr,
D3D_COMPILE_STANDARD_FILE_INCLUDE, "VS", "vs_5_0",
compileFlags, 0, vs, &error);
error = nullptr;
hr = D3DCompileFromFile(srcFile.c_str(), nullptr,
D3D_COMPILE_STANDARD_FILE_INCLUDE, "PS", "ps_5_0",
compileFlags, 0, ps, &error);
得到编译后的shader之后,我们需要创建pipeline state object进行具体的绘制设置,这个object相当于一个大的集合体,包含了各种参数的设置:
D3D12_GRAPHICS_PIPELINE_STATE_DESC psoDesc;
ZeroMemory(&psoDesc, sizeof(D3D12_GRAPHICS_PIPELINE_STATE_DESC));
psoDesc.BlendState = CD3DX12_BLEND_DESC(D3D12_DEFAULT);
psoDesc.DepthStencilState = CD3DX12_DEPTH_STENCIL_DESC(D3D12_DEFAULT);
psoDesc.DSVFormat = mDepthStencilBufferFormat;
psoDesc.Flags = D3D12_PIPELINE_STATE_FLAG_NONE;
psoDesc.IBStripCutValue = D3D12_INDEX_BUFFER_STRIP_CUT_VALUE_DISABLED;
psoDesc.InputLayout = { mInputLayout.data(), mInputLayout.size() };
psoDesc.NodeMask = 0;
psoDesc.NumRenderTargets = 1;
psoDesc.PrimitiveTopologyType = D3D12_PRIMITIVE_TOPOLOGY_TYPE_TRIANGLE;
psoDesc.pRootSignature = mRootSignature.Get();
CD3DX12_RASTERIZER_DESC rastDesc = CD3DX12_RASTERIZER_DESC(D3D12_DEFAULT);
rastDesc.FillMode = mFillMode;
rastDesc.CullMode = mCullMode;
psoDesc.RasterizerState = rastDesc;
psoDesc.RTVFormats[0] = mBackBufferFormat;
psoDesc.SampleDesc.Count = mEnableMsaa ? mMsaaCount : 1;
psoDesc.SampleDesc.Quality = mEnableMsaa ? mMsaaQuality - 1 : 0;
psoDesc.SampleMask = UINT_MAX;
psoDesc.PS = { ps->GetBufferPointer(), ps->GetBufferSize() };
psoDesc.VS = { vs->GetBufferPointer(), vs->GetBufferSize() };
mDevice->CreateGraphicsPipelineState(&psoDesc,
IID_PPV_ARGS(pipelineStateObject)));
最后终于进入到正式的绘制阶段,所谓绘制,简单来说就是设置好各种参数,准备好buffer,将顶点数据使用对应的shader最终输出到视口上,相比之前初始化的流程,这次需要多设置一些参数:
ID3D12DescriptorHeap* descriptorHeaps[] = { mCbvHeap.Get() };
mCommandList->SetDescriptorHeaps(_countof(descriptorHeaps), descriptorHeaps);
mCommandList->SetGraphicsRootSignature(mRootSignature.Get());
mCommandList->SetGraphicsRootDescriptorTable(0,
mCbvHeap->GetGPUDescriptorHandleForHeapStart());
mCommandList->SetPipelineState(object->mPipelineState.Get());
mCommandList->IASetPrimitiveTopology(D3D_PRIMITIVE_TOPOLOGY_TRIANGLELIST);
这里,通过调用SetGraphicsRootDescriptorTable,我们将const buffer和shader中的register(b0)关联起来。具体的绘制代码比较简单:
mCommandList->IASetVertexBuffers(0, 2, mVertexBufferViews.data());
mCommandList->IASetIndexBuffer(&mIndexBufferView);
mCommandList->DrawIndexedInstanced(object->mIndexCount, 1,
object->mStartIndexLocation, object->mBaseVertexLocation, 0);
这里的StartIndexLocation和BaseVertexLocation是用来告诉GPU从哪里读取索引缓存,如何读取顶点缓存(假如一个缓存中包含了多个object的数据)。最后的绘制效果如图:
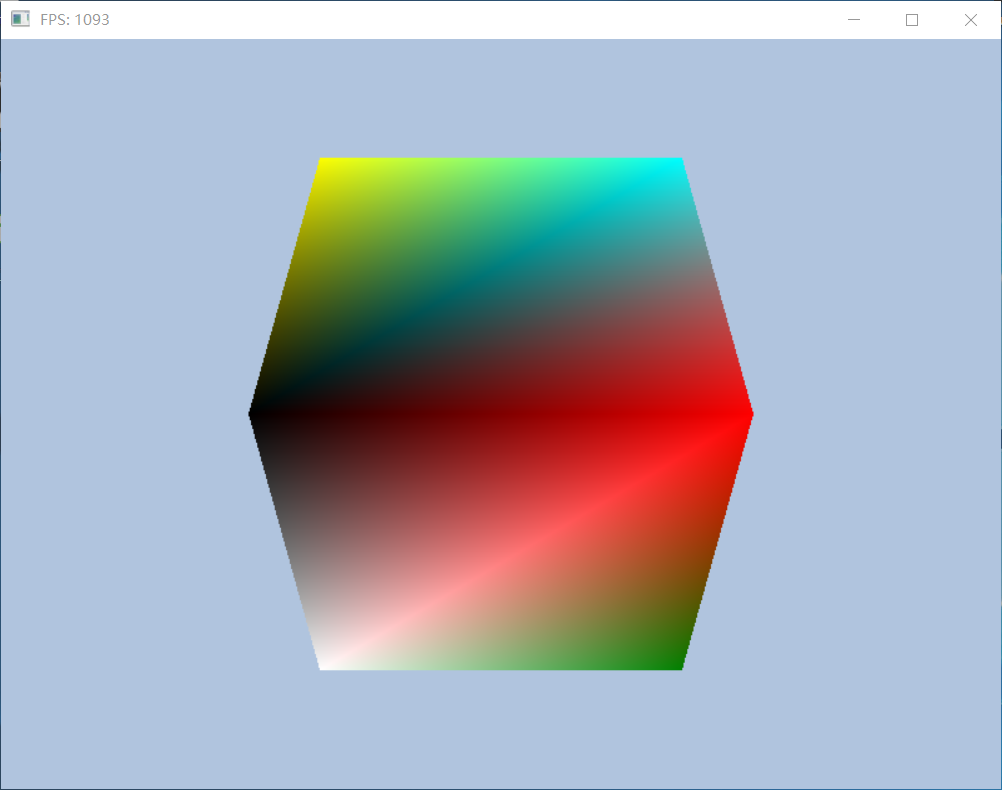
如果你觉得我的文章有帮助,欢迎关注我的微信公众号(大龄社畜的游戏开发之路)-


 浙公网安备 33010602011771号
浙公网安备 33010602011771号