


时间序列分析模型——ARIMA模型
一、研究目的
传统的经济计量方法是以经济理论为基础来描述变量关系的模型。但经济理论通常不足以对变量之间的动态联系提供一个严密的说明,而且内生变量既可以出现在方程的左端又可以出现在方程的右端使得估计和推断变得更加复杂。为了解决这些问题而出现了一种用非结构方法来建立各个变量之间关系的模型,如向量自回归模型(vector autoregression,VAR)和向量误差修正模型(vector error correction model,VEC)。
在经典的回归模型中,主要是通过回归分析来建立不同变量之间的函数关系(因果关系),以考察事物之间的联系。本案例要讨论如何利用时间序列数据本身建立模型,以研究事物发展自身的规律,并据此对事物未来的发展做出预测。研究时间序列数据的意义:在现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。在现实中很多问题,如利率波动、收益率变化、反映股市行情的各种指数等通常都可以表达为时间序列数据,通过研究这些数据,发现这些经济变量的变化规律(对于某些变量来说,影响其发展变化的因素太多,或者是主要影响变量的数据难以收集,以至于难以建立回归模型来发现其变化发展规律,此时,时间序列分析模型就显现其优势——因为这类模型不需要建立因果关系模型,仅需要其变量本身的数据就可以建模),这样的一种建模方式就属于时间序列分析的研究范畴。而时间序列分析中,ARIMA模型是最典型最常用的一种模型。
二、ARIMA模型的原理
1、ARIMA的含义。ARIMA包含3个部分,即AR、I、MA。AR——表示auto regression,即自回归模型;I——表示integration,即单整阶数,时间序列模型必须是平稳性序列才能建立计量模型,ARIMA模型作为时间序列模型也不例外,因此首先要对时间序列进行单位根检验,如果是非平稳序列,就要通过差分来转化为平稳序列,经过几次差分转化为平稳序列,就称为几阶单整;MA——表示moving average,即移动平均模型。可见,ARIMA模型实际上是AR模型和MA模型的组合。
ARIMA模型与ARMA模型的区别:ARMA模型是针对平稳时间序列建立的模型。ARIMA模型是针对非平稳时间序列建模。换句话说,非平稳时间序列要建立ARMA模型,首先需要经过差分转化为平稳时间序列,然后建立ARMA模型。
2、ARIMA模型的原理。正如前面介绍,ARIMA模型实际上是AR模型和MA模型的组合。
AR模型的形式如下:
其中:参数为常数,是阶自回归模型的系数;为自回归模型滞后阶数;是均值为0,方差为的白噪声序列。模型记做——表示阶自回归模型。
MA模型的形式如下:
其中:参数为常数;参数是阶移动平均模型的系数;为移动平均模型滞后阶数;是均值为0,方差为的白噪声序列。模型记做——表示阶移动平均模型。
ARIMA模型的形式如下:
模型记做。为自回归模型滞后阶数,为时间序列单整阶数,为阶移动平均模型滞后阶数。当时,,此时ARIMA模型退化为MA模型;当时,,ARIMA模型退化为AR模型。
3、建立ARIMA模型需要解决的3个问题。由以上分析可知,建立一个ARIMA模型需要解决以下3个问题:
(1)将非平稳序列转化为平稳序列。
(2)确定模型的形式。即模型属于AR、MA、ARMA中的哪一种。这主要是通过模型识别来解决的。
(3)确定变量的滞后阶数。即和的数字。这也是通过模型识别完成的。
4、ARIMA模型的识别
ARIMA模型识别的工具为自相关系数(AC)和偏自相关系数(PAC)。
自相关系数:时间序列滞后k阶的自相关系数由下式估计:
其中是序列的样本均值,这是相距k期值的相关系数。称为时间序列的自相关系数,自相关系数可以部分的刻画一个随机过程的形式。它表明序列的邻近数据之间存在多大程度的相关性。
偏自相关系数:偏自相关系数是在给定的条件下,之间的条件相关性。其相关程度用偏自相关系数度量。在k阶滞后下估计偏自相关系数的计算公式为:
其中是在k阶滞后时的自相关系数估计值。称为偏相关是因为它度量了k期间距的相关而不考虑k-1期的相关。如果这种自相关的形式可由滞后小于k阶的自相关表示,那么偏相关在k期滞后下的值趋于0。
识别:
AR(p)模型的自相关系数是随着k的增加而呈现指数衰减或者震荡式的衰减,具体的衰减形式取决于AR(p)模型滞后项的系数;AR(p)模型的偏自相关系数是p阶截尾的。因此可以通过识别AR(p)模型的偏自相关系数的个数来确定AR(p)模型的阶数p。
MA(q)模型的自相关系数在q步以后是截尾的。MA(q)模型的偏自相关系数一定呈现出拖尾的衰减形式。
ARMA(p,q)模型是AR(p)模型和MA(q)模型的组合模型,因此ARMA(p,q)的自相关系数是AR(p)自相关系数和MA(q)的自相关系数的混合物。当p=0时,它具有截尾性质;当q=0时,它具有拖尾性质;当p,q都不为0,它具有拖尾性质。
通常,ARMA(p,q)过程的偏自相关系数可能在p阶滞后前有几项明显的尖柱,但从p阶滞后项开始逐渐趋于0;而它的自相关系数则是在q阶滞后前有几项明显的尖柱,从q阶滞后项开始逐渐趋于0。
三、数据和变量的选择
本案例选取我国实际GDP的时间序列建立ARIMA模型,样本区间为1978—2001。数据来源于国家统计局网站上各年的统计年鉴,GDP数据均通过GDP指数换算为以1978年价格计算的值。见表1:
表1:我国1978—2003年GDP(单位:亿元)
|
年度 |
GDP |
年度 |
GDP |
年度 |
GDP |
|
1978 |
3605.6 |
1986 |
10132.8 |
1994 |
46690.7 |
|
1979 |
4074 |
1987 |
11784.7 |
1995 |
58510.5 |
|
1980 |
4551.3 |
1988 |
14704 |
1996 |
68330.4 |
|
1981 |
4901.4 |
1989 |
16466 |
1997 |
74894.2 |
|
1982 |
5489.2 |
1990 |
18319.5 |
1998 |
79003.3 |
|
1983 |
6076.3 |
1991 |
21280.4 |
1999 |
82673.1 |
|
1984 |
7164.4 |
1992 |
25863.7 |
2000 |
89340.9 |
|
1985 |
8792.1 |
1993 |
34500.7 |
2001 |
98592.9 |
四、ARIMA模型的建立步骤
1、单位根检验,确定单整阶数。
由单位根检验的案例分析可知,GDP时间序列为2阶单整的。即d=2。通过2次差分,将GDP序列转化为平稳序列 。利用序列来建立ARMA模型。
2、模型识别
确定模型形式和滞后阶数,通过自相关系数(AC)和偏自相关系数(PAC)来完成识别。
首先将GDP数据输入Eviews软件,查看其二阶差分的AC和PAC。打开GDP序列窗口,点击View按钮,出现下来菜单,选择Correlogram(相关图),如图:
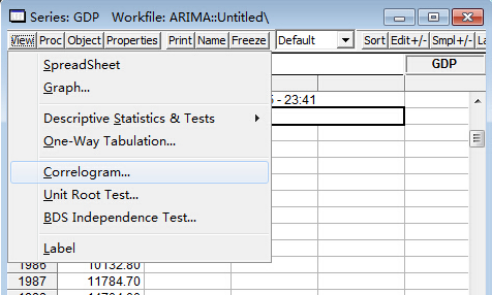
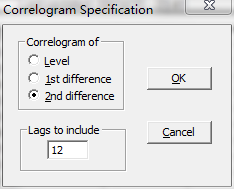
打开相关图对话框,选择二阶差分(2nd difference),点击OK,得到序列的AC和PAC。(也可以将GDP序列先进行二阶差分,然后在相关图中选择水平(Level))

从图中可以看出,序列的自相关系数(AC)在1阶截尾,偏自相关系数(PAC)在2阶截尾。因此判断模型为ARMA模型,且,。即:
3、建模
由以上分析可知,建立模型。首先将GDP序列进行二次差分,得到序列。然后在Workfile工作文件簿中新建一个方程对话框,采用列表法的方法对方程进行定义。自回归滞后项用ar表示,移动平均项用ma表示。本例中自回归项有两项,因此用ar(1)、ar(2)表示,移动平均项有一项,用ma(1)表示,如图:
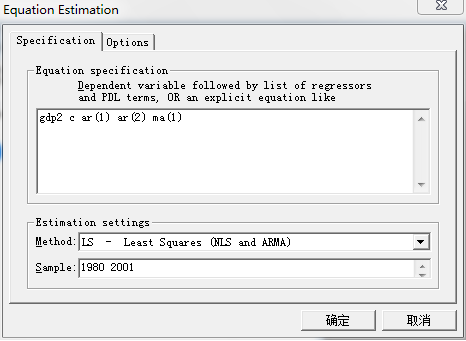
点击确定,得到模型估计结果:

从拟合优度看,,模型拟合效果较好,DW统计量为2.43,各变量t统计量也通过显著性检验,模型较为理想。对残差进行检验,也是平稳的,因此判断模型建立正确。
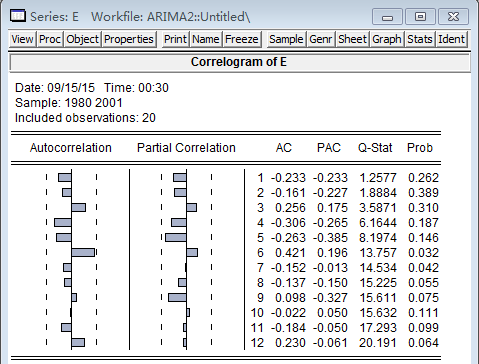
残差的自相关系数(AC)和偏自相关系数(PAC)
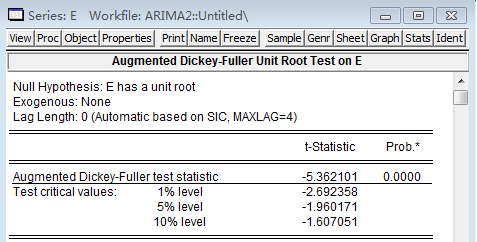
残差单位根检验结果
最终确定GDP时间序列的ARIMA模型为:
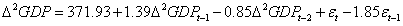
文章我是下载的,觉得写得特别详细,就粘过来了,嘿嘿

 浙公网安备 33010602011771号
浙公网安备 33010602011771号