

小白学 Python 爬虫(7):HTTP 基础

人生苦短,我用 Python
前文传送门:
小白学 Python 爬虫(2):前置准备(一)基本类库的安装
小白学 Python 爬虫(3):前置准备(二)Linux基础入门
小白学 Python 爬虫(4):前置准备(三)Docker基础入门
小白学 Python 爬虫(6):前置准备(五)爬虫框架的安装
网络的起源
这个其实是一个冷知识,各位同学可以猜测一下计算机网络的起源是在哪里。
硅谷?大学?实验室?有点接近了,但还不够准确。
准确的答案是在美苏冷战背景下的美国国防部 。
对的,你没看错,是美国军方 ,最先进的技术总是先应用于军事领域,随着时间的推移才会慢慢的民用化。
1968年,在美国国防部高级计划局的领导下,阿帕网( ARPANET )诞生了。
ARPANET只有四个节点,连接起加利福尼亚州大学洛杉矶分校、加州大学圣巴巴拉分校、斯坦福大学、犹他州大学这四所学校的大型计算机。
阿帕网 ,是全球公认的计算机网络的始祖。

URI 、 URL 和 URN
爬虫是一个模拟浏览器进行 HTTP 请求的过程。这就需要我们了解从浏览器输入 URL 到获取到网页中间究竟发生了什么。
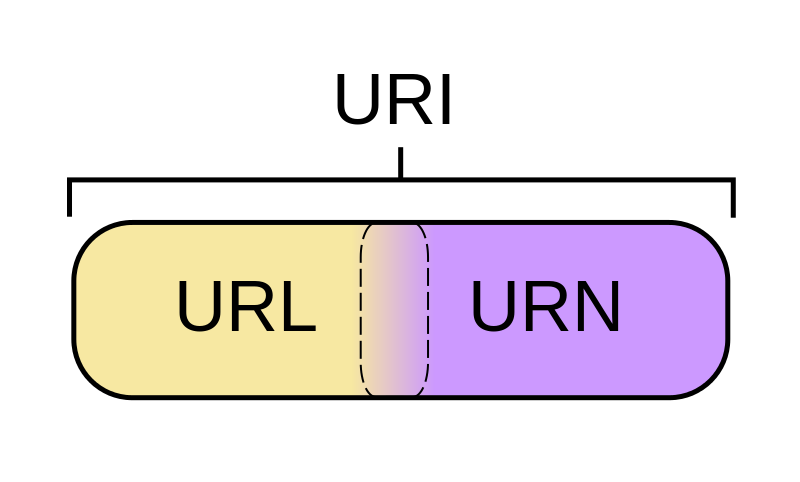
先介绍一组概念, URI 和 URL :
- URI = Universal Resource Identifier 统一资源标志符,用来标识抽象或物理资源的一个紧凑字符串。
- URL = Universal Resource Locator 统一资源定位符,一种定位资源的主要访问机制的字符串,一个标准的URL必须包括:protocol、host、port、path、parameter、anchor。
- URN = Universal Resource Name 统一资源名称,通过特定命名空间中的唯一名称或ID来标识资源。
没看懂是吧,没事儿,不需要懂,了解一下就好了,我们来举例子。
比如上面这张图片的地址:https://cdn.geekdigging.com/python-spider/uri-url-urn.png ,它是一个 URL 同时也是一个 URI , URL 是 URI 的子集,也就是说每个 URL 都是 URI ,但不是每个 URI 都是 URL ,因为 URI 还包括一个子类叫 URN 。在目前的网络中 URN 的使用非常少,所以几乎所有的 URI 都是 URL ,一般的网页链接我们既可以称为 URL ,也可以称为 URI ,完全看个人喜好。
超文本
什么是超文本?
超文本是指可以链接到另一个文档或文本的单词,短语或大块文本。超文本涵盖了文本超链接和图形超链接。
我们在浏览器中访问的网页是由 HTML 编写而成,而 HTML 则被称作为“超文本标记语言”。在 HTML 代码中,包含了一系列的标签,包括图片等的超链接。
我们来看一下一个真实的网站的源代码是怎么样的,在 Chrome 浏览器中,使用 F12 打开开发者工具。
HTTP 和 HTTPS
什么是 HTTP ?
超文本传输协议,是一个基于请求与响应,无状态的,应用层的协议,常基于TCP/IP协议传输数据,互联网上应用最为广泛的一种网络协议,所有的WWW文件都必须遵守这个标准。设计HTTP的初衷是为了提供一种发布和接收HTML页面的方法。
什么是HTTPS?
《图解HTTP》这本书中曾提过HTTPS是身披SSL外壳的HTTP。HTTPS是一种通过计算机网络进行安全通信的传输协议,经由HTTP进行通信,利用SSL/TLS建立全信道,加密数据包。HTTPS使用的主要目的是提供对网站服务器的身份认证,同时保护交换数据的隐私与完整性。
PS:TLS是传输层加密协议,前身是SSL协议,由网景公司1995年发布,有时候两者不区分。
现在越来越多的网站和App都已经向HTTPS方向发展,例如:
- 苹果公司强制所有iOS App在2017年1月1日前全部改为使用HTTPS加密,否则App就无法在应用商店上架;
- 谷歌从2017年1月推出的Chrome 56开始,对未进行HTTPS加密的网址链接亮出风险提示,即在地址栏的显著位置提醒用户“此网页不安全”;
- 腾讯微信小程序的官方需求文档要求后台使用HTTPS请求进行网络通信,不满足条件的域名和协议无法请求。
HTTP协议
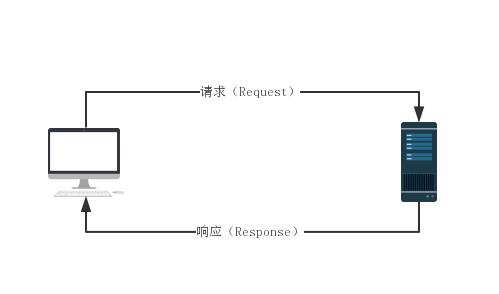
HTTP 协议本身是非常简单的。它规定,只能由客户端主动发起请求,服务器接收请求处理后返回响应结果,同时 HTTP 是一种无状态的协议,协议本身不记录客户端的历史请求记录。
为了比较直观的展示这个过程,我们依然打开 Chrome 浏览器,按 F12 开启开发者模式。
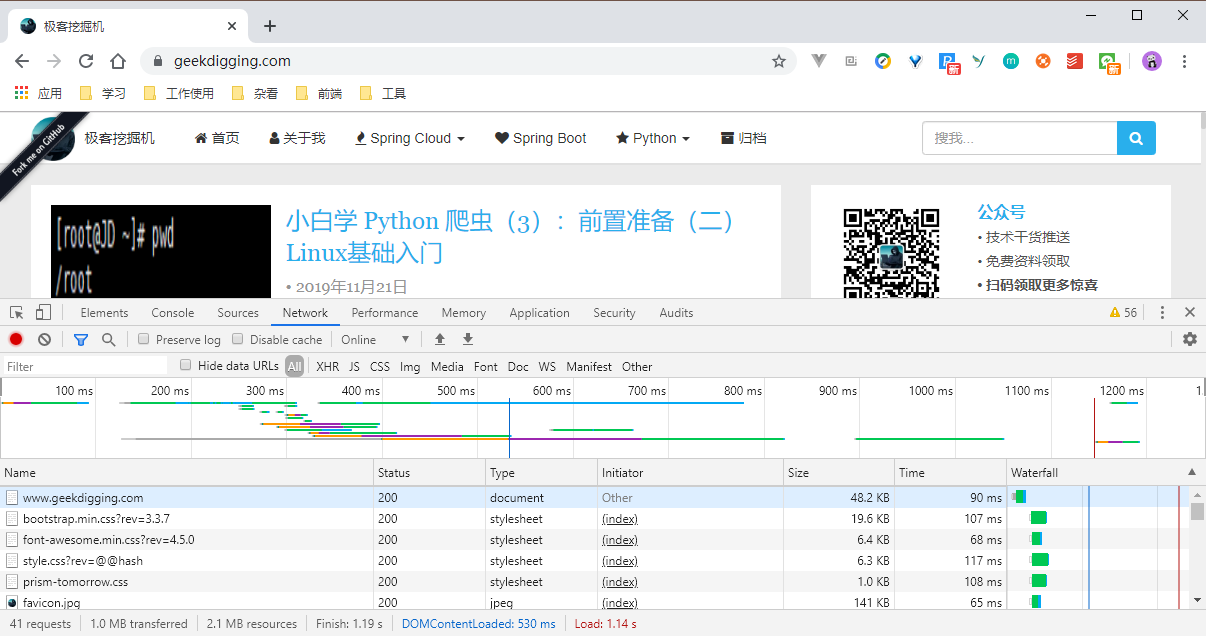
看第一行,www.geekdigging.com 那一行:
- Name:请求的名称。
- Status:状态码, 200 代表正常响应。
- Type:文旦类型,这里我们是请求了一个 HTML 文档。
- Initiator:请求源。用来标记请求是由哪个对象或进程发起的。
- Size:资源大小,这个标识了我们请求的资源的大小。
- Time:消耗的时间,单位是 ms 。
- Watefall:网络请求的可视化瀑布流。
我们点击一下那一行,可以看到更加详细的内容:
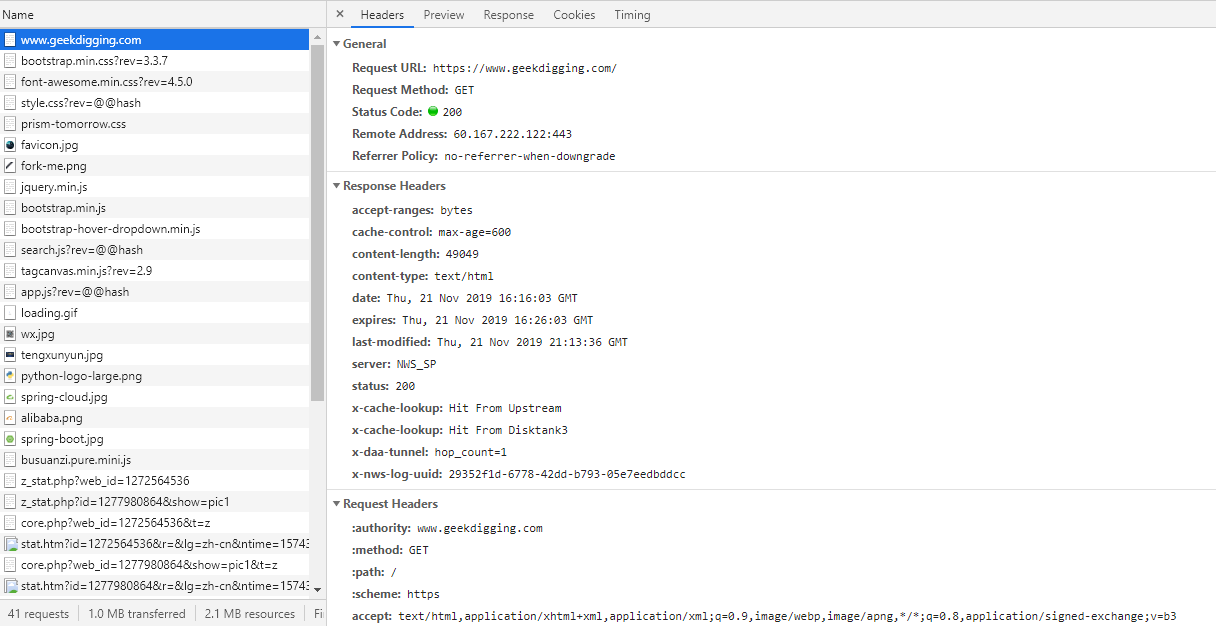
包含了 Header 头信息, Preview (Response Preview) 响应信息预览, Response 响应具体的 HTML 代码, Cookies ,Timing 整个请求周期耗时。
General部分: Request URL 为请求的URL, Request Method 为请求的方法, Status Code 为响应状态码, Remote Address 为远程服务器的地址和端口, Referrer Policy 为Referrer判别策略。
Request 请求
一个HTTP请求报文由请求行(request line)、请求头部(headers)、空行(blank line)和请求数据(request body)4个部分组成。

请求行
分为三个部分:请求方法、请求地址URL和HTTP协议版本,它们之间用空格分割。
例如,GET /index.html HTTP/1.1。
HTTP/1.1 定义的请求方法有8种:
- GET :请求页面,并返回页面内容。
- POST :大多用于提交表单或上传文件,数据包含在请求体中。
- PUT :从客户端向服务器传送的数据取代指定文档中的内容。
- DELETE :请求服务器删除指定的页面。
- PATCH :是对 PUT 方法的补充,用来对已知资源进行局部更新 。
- HEAD:类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头。
- OPTIONS:允许客户端查看服务器的性能。
- TRACE:回显服务器收到的请求,主要用于测试或诊断。
- CONNECT :HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。
常用的有 GET 和 POST 。
GET
在浏览器中直接输入URL并回车,这就发起了一个 GET 请求,请求的参数会直接包含在 URL 里,请求参数和对应的值附加在URL后面,利用一个问号 ? 代表URL的结尾与请求参数的开始,传递参数长度受限制。由于不同的浏览器对地址的字符限制也有所不同,一般最多只能识别1024个字符,所以如果需要传送大量数据的时候,也不适合使用GET方式。
POST
允许客户端给服务器提供信息较多。POST方法将请求参数封装在HTTP请求数据中,以名称/值的形式出现,可以传输大量数据,这样POST方式对传送的数据大小没有限制,而且也不会显示在URL中。
请求头
因为请求行所携带的信息量非常有限,以至于客户端还有很多想向服务器要说的事情不得不放在请求首部(Header),请求首部用于给服务器提供一些额外的信息,比如 User-Agent 用来表明客户端的身份,让服务器知道你是来自浏览器的请求还是爬虫,是来自 Chrome 浏览器还是 FireFox。HTTP/1.1 规定了47种首部字段类型。 HTTP 首部字段的格式很像 Python 中的字典类型,由键值对组成,中间用冒号隔开。
下面简要说明一些常用的头信息。
- Accept:请求报头域,用于指定客户端可接受哪些类型的信息。
- Accept-Language:指定客户端可接受的语言类型。
- Accept-Encoding:指定客户端可接受的内容编码。
Host:用于指定请求资源的主机IP和端口号,其内容为请求URL的原始服务器或网关的位置。从HTTP 1.1版本开始,请求必须包含此内容。 - Cookie:也常用复数形式 Cookies,这是网站为了辨别用户进行会话跟踪而存储在用户本地的数据。它的主要功能是维持当前访问会话。例如,我们输入用户名和密码成功登录某个网站后,服务器会用会话保存登录状态信息,后面我们每次刷新或请求该站点的其他页面时,会发现都是登录状态,这就是Cookies的功劳。Cookies里有信息标识了我们所对应的服务器的会话,每次浏览器在请求该站点的页面时,都会在请求头中加上Cookies并将其发送给服务器,服务器通过Cookies识别出是我们自己,并且查出当前状态是登录状态,所以返回结果就是登录之后才能看到的网页内容。
- Referer:此内容用来标识这个请求是从哪个页面发过来的,服务器可以拿到这一信息并做相应的处理,如作来源统计、防盗链处理等。
- User-Agent:简称UA,它是一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本、浏览器及版本等信息。在做爬虫时加上此信息,可以伪装为浏览器;如果不加,很可能会被识别出为爬虫。
- Content-Type:也叫互联网媒体类型(Internet Media Type)或者MIME类型,在HTTP协议消息头中,它用来表示具体请求中的媒体类型信息。例如,text/html代表HTML格式,image/gif代表GIF图片,application/json代表JSON类型,更多对应关系可以查看此对照表:http://tool.oschina.net/commons。
请求数据
请求体一般承载的内容是POST请求中的表单数据,而对于GET请求,请求体则为空。
注意这里提交数据的方式和请求头设置的 Content-Type 息息相关。
Response 响应
服务端接收请求并处理后,返回响应内容给客户端,同样地,响应内容也必须遵循固定的格式浏览器才能正确解析。HTTP 响应也由3部分组成,分别是:响应行、响应首部、响应体,与 HTTP 的请求格式是相对应的。
响应行
响应行同样也是3部分组成,由服务端支持的 HTTP 协议版本号、状态码、以及对状态码的简短原因描述组成。
状态码
响应状态码表示服务器的响应状态,常见的如200代表服务器正常响应,404代表页面未找到,500代表服务器内部发生错误。
响应头
响应头包含了服务器对请求的应答信息,如Content-Type、Server、Set-Cookie等。下面简要说明一些常用的头信息。
- Date:标识响应产生的时间。
- Last-Modified:指定资源的最后修改时间。
- Content-Encoding:指定响应内容的编码。
- Server:包含服务器的信息,比如名称、版本号等。
- Content-Type:文档类型,指定返回的数据类型是什么,如text/html代表返回HTML文档,application/x-javascript则代表返回JavaScript文件,image/jpeg则代表返回图片。
- Set-Cookie:设置Cookies。响应头中的Set-Cookie告诉浏览器需要将此内容放在Cookies中,下次请求携带Cookies请求。
- Expires:指定响应的过期时间,可以使代理服务器或浏览器将加载的内容更新到缓存中。如果再次访问时,就可以直接从缓存中加载,降低服务器负载,缩短加载时间。
响应体
最重要的当属响应体的内容了。响应的正文数据都在响应体中,比如请求网页时,它的响应体就是网页的HTML代码;请求一张图片时,它的响应体就是图片的二进制数据。
在做爬虫时,我们主要通过响应体得到网页的源代码、JSON数据等,然后从中做相应内容的提取。
参考
https://blog.csdn.net/koflance/article/details/79635240
https://blog.csdn.net/xiaoming100001/article/details/81109617
作者:极客挖掘机
定期发表作者的思考:技术、产品、运营、自我提升等。
本文版权归作者极客挖掘机和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
如果您觉得作者的文章对您有帮助,就来作者个人小站逛逛吧:极客挖掘机

 浙公网安备 33010602011771号
浙公网安备 33010602011771号