MySQL crash-safe 的功臣 —— redo log!
InnoDB 的事务是基于事务日志 undo log 和 redo log 实现的。
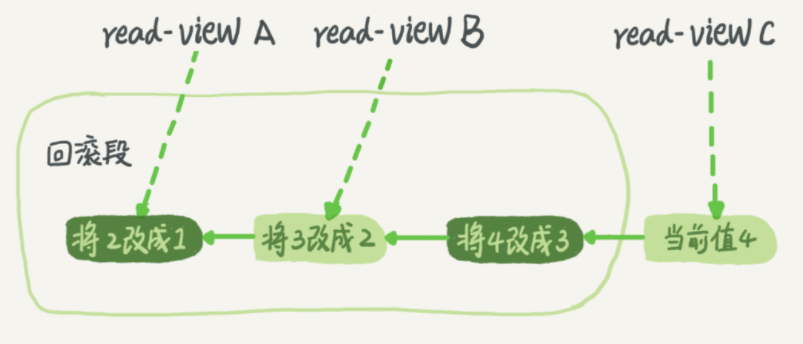
undo log
undo log 是回滚日志,使用段的方式记录数据行的历史版本,提供回滚操作,保证事务的一致性。
redo log
redo log 是重做日志,记录数据页的修改,提供再写入操作,保证事务的原子性和持久性。
在 MySQL 中,如果每一次更新都写进磁盘,那性能的开销会很大。
为了解决这个问题,InnoDB 引擎采用 WAL(Write Ahead Log)技术,即先写日志,再写磁盘。
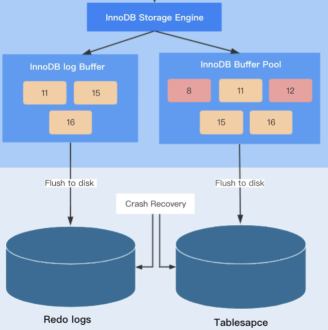
具体来说,当一条记录更新时,InnoDB 先把记录写到 redo log buffer,并更新内存(Buffer Pool)。
此时,该内存页就跟磁盘上的不一致,称为脏页。脏页会被后台线程自动刷到磁盘上,而这个过程由于会占用资源,可能会让 MySQL 抖一下,突然变慢一会。
和 Redis 增量复制时用到的环形缓冲区类似。
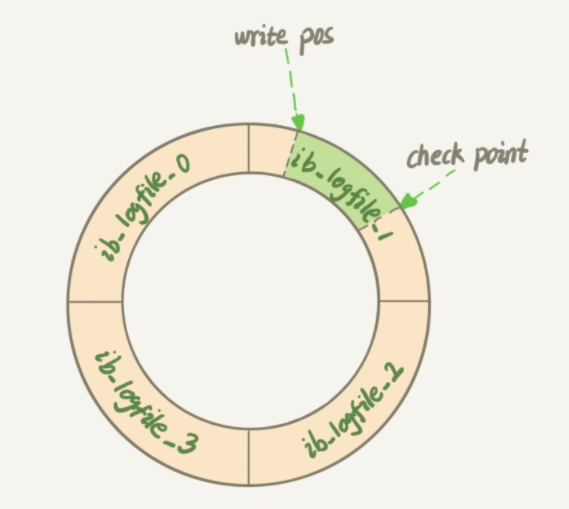
InnoDB 的 redo log 也是固定大小的,由多个日志文件组合形成一个闭环,当写到结尾时,又会回到开头循环写。
其中,也有两个指针,一个记录写位,一个记录擦除位(更新到 redo log 文件)。
有了 redo log,InnoDB 就能保证 MySQL 宕机时数据不丢失,这个能力称为 crash-safe。
建议把 commit 参数设置成 1,这样每次事务的 redo log buffer 都会持久化到 redo log 文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号