为什么单线程的 Redis 能这么快?
你好,我是阿越。
今天,我想讲一讲很多人初学 Redis 时会遇到的困惑,“为什么单线程的 Redis 能这么快?”
为什么 Redis 采用单线程?
首先,我们先来理清,Redis 为什么使用单线程?
事实上,Redis 只对网络 IO 和数据读写等核心操作采用单线程,目的是避免多线程的并发控制问题。
而其他功能,比如持久化、集群数据同步,其实是多线程执行的。
所以,严格上说 Redis 并不是单线程的,但我们已经习惯将其称为单线程了。
单线程的 Redis 为什么快?
那单线程的 Redis 为什么有高性能呢?主要有以下三点,
- 数据都存储在内存中。
- 有高效的数据结构
- 使用了 I/O 多路复用机制,让单线程可以高效的处理多个请求。
I/O 多路复用
这里,我详细讲讲 I/O 多路复用。
最基础的 TCP 的 Socket 编程,是阻塞 I/O,只能一对一通信。
为了服务更多的客户端,就出现了 I/O 多路复用,让一个线程可以处理多个 IO 流。
Linux 下有三种实现方式,分别是,select、poll 和 epoll。
- select、poll 没有本质差别,内部都是使用线性结构来存储 Socket。
使用时,只知道有 IO 事件发生,但不清楚是哪一个,所以只能遍历整个 Socket 集合,性能低。 - 于是就有了 epoll。它使用红黑树来存储待检测的 Socket,并且使用链表来记录就绪事件,用户调用时,只需将链表中的 Socket 返回,从而避免遍历整个 Socket 集合,大大提高性能。
![]()
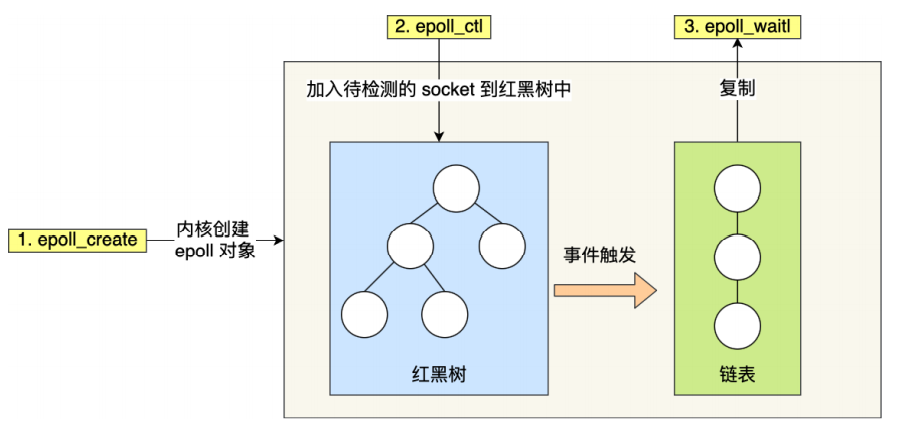
此外,epoll 支持边缘触发和水平触发,而 select、poll 只支持水平触发。
一般而言,边缘触发的效率更高。因为当有事件发生时,边缘触发只用苏醒一次,而水平触发会不断苏醒,直到内核缓冲区的数据都读完。
就好比你的快递到了,边缘触发只会通知你一次,即使不去取,也不会通知第二次。而水平触发会不断通知,直到你把快递取走为止。
Redis 使用的就是 epoll 机制,让内核监测内部的 IO 操作。
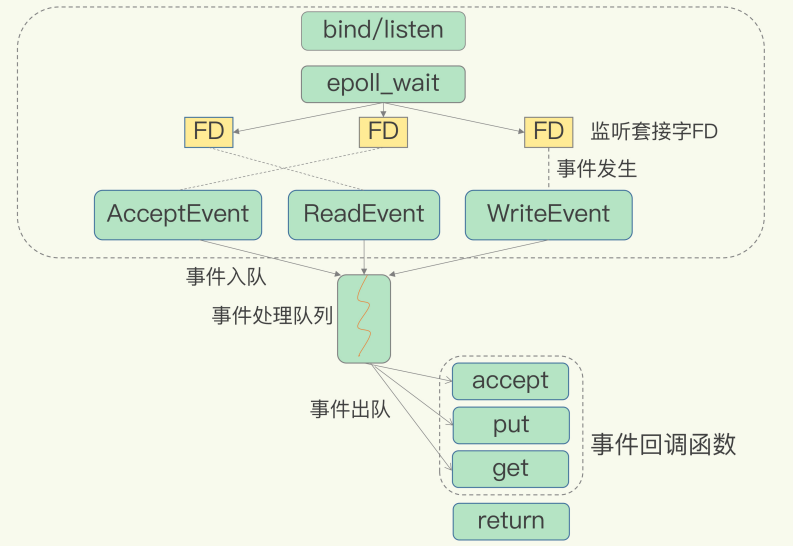
为了能及时通知到 Redis,epoll 使用了基于事件的回调机制。即一旦监测到有请求到达时,就触发相应的事件。
然后,把这些事件都放入一个事件队列,由 Redis 单线程的进行处理,从而实现一个线程可以处理多个 IO 流的效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号