
x86 架构的简单介绍
x86 架构的简单介绍
一、目前常见的 CPU 架构
目前主流的 CPU 架构主要分为两个阵营:以 x86 为核心的复杂指令集架构(CISC),以及以 ARM 和 RISC-V 为代表的精简指令集架构(RISC)。其中,x86 架构长期以来主导着桌面和服务器市场,代表厂商包括 Intel 与 AMD,其特点是指令集复杂、兼容性强、单核性能高,适合处理需要强大通用计算能力的场景。而 ARM 架构和新兴的 RISC-V 架构则以低功耗、高能效比、架构简洁为主要优势,广泛应用于移动终端、物联网及嵌入式设备领域。ARM 生态成熟、授权模式灵活;RISC-V 则凭借开源、可定制、免授权费等特性迅速崛起,吸引了众多芯片厂商和研究机构的关注。经过多年的发展,这两大阵营正在逐步向对方领域靠拢:x86 架构在能耗比和移动端优化方面持续改进,如 Intel 的低功耗系列处理器(Atom、Core Ultra)与 AMD 的高能效设计。ARM 架构则不断提升高性能计算能力,已推出针对桌面和服务器市场的处理器,例如 Apple M 系列芯片、Ampere Altra、以及 华为鲲鹏(Kunpeng)服务器处理器等。同时,RISC-V 也开始探索高性能通用计算方向,出现了如 SiFive Performance 系列和 Alibaba 平头哥玄铁等高端内核。
此外还有经典的基于 RSIC 的 MIPS 架构,目前已开始转向 RISC-V。由 IBM 主导的基于 RISC 的 Power 架构,用于大型机和高性能计算,包括用于桌面电脑的 PowerPC 和用于服务器的 POWER 系列。
| 架构 | 类型 | 代表厂商 | 主要领域 | 优势 | 劣势 |
|---|---|---|---|---|---|
| x86 | CISC | Intel、AMD | 桌面、服务器 | 性能强、兼容性好 | 功耗高 |
| ARM | RISC | Apple、华为、高通 | 移动、嵌入式 | 低功耗、生态成熟 | 授权依赖 |
| RISC-V | RISC | SiFive、平头哥 | 嵌入式、AI、科研 | 开源灵活、潜力大 | 生态未完善 |
| MIPS | RISC | Wave Computing | 网络设备(旧) | 设计简洁 | 市场衰退 |
| Power | RISC | IBM | 高性能计算 | 吞吐量强 | 成本高、生态小 |
1.1 x86 架构
x86 是个人计算机历史上最经典、最成功的 CPU 架构之一。从最早的 8086 到如今的 Core、Ryzen,它经历了 40 多年的发展,形成了庞大的生态体系。几乎所有的桌面操作系统(如 Windows、Linux、macOS 的早期版本)都对 x86 有深度优化。
核心特点:
- 复杂指令集(CISC):支持大量指令,功能强大但硬件实现复杂。
- 高性能:得益于超标量、乱序执行、分支预测等技术,单核性能长期领先。
- 功耗高:相比 RISC 架构,功耗与发热较大,不适合移动端。
- 兼容性强:支持大量指令,功能强大但硬件实现复杂。
x86 的应用领域包括桌面电脑、服务器、数据中心、高性能工作站,并且逐渐朝着高能效的方向演进,比如 Intel Core Ultra、AMD Zen 5。
1.2 ARM 架构
核心特点:
- 精简指令集计算 (RISC) 架构: 指令集简单,设计紧凑高效。
- 低功耗和高能效: 这是其最大的优势,非常适合电池供电的设备。
- 授权模式: ARM公司不生产芯片,而是设计架构和指令集,然后授权给各大芯片制造商进行二次开发和制造。
- 生态:Android、iOS、Linux 等系统都有良好支持。
ARM 的主要应用领域包括智能手机、平板电脑、智能电视、汽车电子、路由器、嵌入式设备等。其正在进军高性能计算领域。Apple M 系列、华为鲲鹏、Ampere Altra 等产品已进入桌面和服务器市场,挑战 x86 的地位。
1.3 RISC-V 架构
RISC-V 是一种完全开源的指令集架构,任何公司或个人都可以免费使用和修改。由于其开源的特点,很多想要自主设计芯片的公司基于此研究自己的处理器架构,比如由 RISC-V 转变为自研架构的龙芯。
核心特点:
- 开源、免费:无专利费,无需授权。
- 精简指令集
- 可扩展、可定制:适合科研、AI、IoT 等多种场景。
- 生态仍在成长:开发工具、编译器、操作系统支持正在逐步完善。
- 潜力巨大:中国、欧洲、印度等国家正在积极推动 RISC-V 产业化。
RISC-V 的应用领域包括物联网、微控制器、嵌入式系统、AI 加速器、高性能通用计算等等,被视为去美化、去授权依赖的关键路线之一,未来可能成为全球芯片生态的重要支柱。
二、x86 架构的组成
在介绍 x86 架构前,我们先明确核心前提 —— 指令集的概念。指令集(ISA,Instruction Set Architecture)是处理器架构的基础核心,它定义了 CPU 能够识别和执行的代码规范。所有高级语言编写的程序,最终都必须通过编译转化为机器码,而这些机器码正是指令集的具体落地形式。从硬件的角度看,处理器必须根据 ISA 的定义来构建其内部逻辑电路,以确保能正确解析和执行这些指令。指令集具有架构排他性,比如为 ARM 架构编译的可执行文件,其包含的机器指令无法被 x86 处理器识别和运行。
指令集合汇编的关系。它们非常相关但不完全等同,是抽象与具体的关系。指令集是一个标准和架构。它定义了我们可以有哪些指令以及这些指令的功能是什么。汇编指令是这种标准和架构的具体文本表示,是给人看的。它是根据指令集的规范,用助记符(比如 MOV, ADD, JMP)写出来的代码。每一条汇编指令都直接对应着一条指令集架构中定义的机器指令。当你用汇编器编译汇编代码时,它就会把这些助记符(如 ADD)翻译成指令集规范所对应的二进制操作码(如 00000011),也就是CPU真正能执行的机器码。
指令集与微架构的关系。微架构是实现指令集的具体硬件电路。 指令集是目标,微架构是达成这个目标的手段。没有微架构,指令集只是一纸空文;没有指令集,微架构就不知道要执行什么命令。一个指令集可以有多种微架构实现。Intel的Core i7 和 AMD 的 Ryzen 都执行 x86指令集,所以它们可以运行相同的Windows操作系统和软件。但它们的内部设计(微架构)完全不同:Intel和AMD的缓存结构、流水线深度、分支预测算法、执行单元数量等都各有千秋。这就是为什么同为x86 CPU,它们的性能和功耗却不一样。 在指令集基本不变的情况下,通过改进微架构(比如增加更多的执行单元、更好的分支预测、更大的缓存),可以让CPU在同一个时钟周期内处理更多的指令,从而大幅提升性能。
指令集的主要定义:
| 类别 | 说明 | 举例 |
|---|---|---|
| 指令系统(Instruction Set) | 定义 CPU 能执行的所有操作 | 加法、乘法、跳转、加载/存储等 |
| 寄存器集(Registers) | 定义 CPU 内部可直接操作的高速存储单元 | EAX、RAX(x86);X0–X31(ARM) |
| 数据类型(Data Types) | 支持的数据格式 | 字节、字、双字、浮点数、向量 |
| 寻址方式(Addressing Modes) | 指定操作数的获取方式 | 立即数、寄存器间接、基址+偏移 |
| 异常与中断机制 | 定义错误处理、系统调用等机制 | 页错误、除零错误、中断向量表 |
| 内存模型(Memory Model) | 定义程序的内存访问与一致性规则 | 物理地址、虚拟地址、分页机制 |
同样采用 x86 架构的不同厂商的处理器一般指令集是兼容的,他们的处理器的区别主要是实现指令集的具体微架构的设计区别。比如同样实现一个指令,不同厂商执行这个指令的硬件电路设计不同。这就引出了 x86 的整套体系:
- 指令集架构(ISA):软件层面定义的指令规则。
- 微架构(Microarchitecture):硬件层面具体实现方式。
- 扩展技术:如 SIMD[1](单指令处理多数据)、虚拟化、内存保护、超线程[2]等。
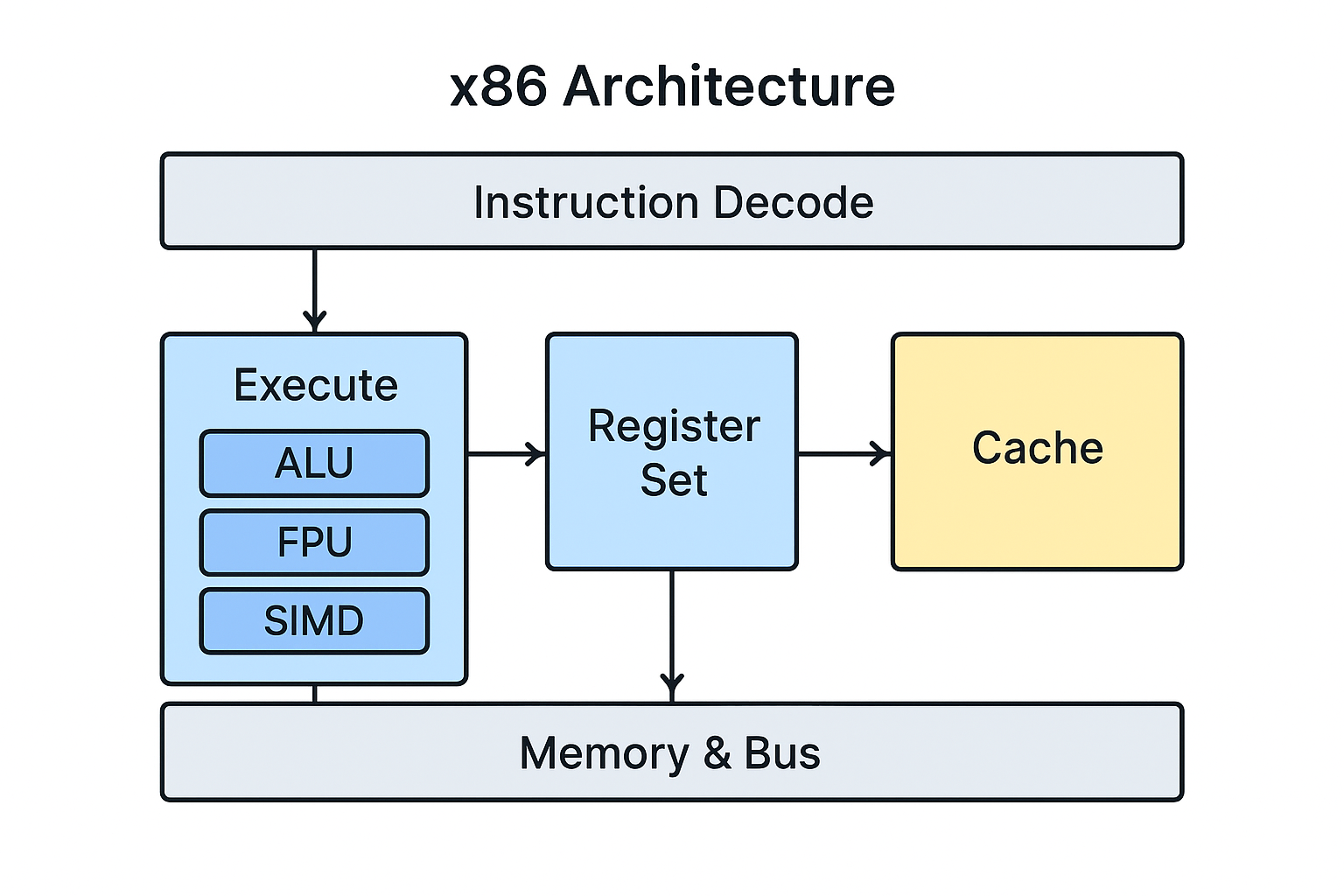
2.1 x86 架构的主要组成
| 层次 | 组成 | 功能 |
|---|---|---|
| 指令集层 | 指令系统、寄存器、寻址模式 | 软件与硬件的接口 |
| 微架构层 | 取指、译码、执行、调度、预测 | 执行指令的实际逻辑 |
| 存储层 | 缓存、MMU、总线 | 提供数据支撑 |
| 控制层 | 模式切换、异常处理、虚拟化 | 管理与调度 CPU 资源 |
2.1.1 指令集
ISA 是 x86 架构的灵魂,它定义了 CPU 可以理解和执行的所有指令、寄存器种类、寻址模式、异常机制等。x86 的 ISA 发展经历了多个阶段:
- x86(16位):8086~80286 时代。
- IA-32(32位):80386 开始,广泛用于早期 PC。
- x86-64(64位):由 AMD 首先推出(AMD64),支持 64 位寻址与寄存器扩展。
- SIMD 扩展:MMX → SSE → AVX → AVX2 → AVX-512,大幅提升并行计算性能。
1. x86 指令集
这里列举一部分:
- 数据传送指令: MOV, PUSH, POP, LEA(取有效地址)。
- 算术运算指令: ADD, SUB, MUL, DIV, INC, DEC。
- 逻辑运算指令: AND, OR, XOR, NOT, SHL(左移), SHR(右移)。
- 控制转移指令: JMP(无条件跳转), CALL / RET(函数调用/返回), Jcc(条件跳转,如JZ, JNE)。
- 字符串操作指令: MOVS, CMPS, SCAS(与REP前缀配合使用)。
- 系统指令: 用于操作系统,如INT(触发中断), IRET(从中断返回), LGDT(加载全局描述符表), CPUID(获取CPU信息)。
2. x86 寄存器组
- 通用寄存器:用于算术运算、逻辑运算、内存寻址等。某些寄存器有特殊用途,如ECX常用于循环计数,ESP始终指向栈顶。
- 32位: EAX, EBX, ECX, EDX, ESI, EDI, ESP, EBP。
- 64位:在32位基础上扩展为RAX, RBX, RCX, RDX, RSI, RDI, RSP, RBP,并新增了R8到R15。
- 段寄存器:在实模式和保护模式的早期,用于内存分段管理。在现代64位模式下,它们的意义不大,通常被设置为0。
- CS(代码段), DS(数据段), SS(堆栈段), ES, FS, GS(附加数据段)。
- 指令指针:存放下一条要执行的指令的内存地址。CPU就是通过改变它来实现跳转和函数调用。
- EIP(32位) / RIP(64位)
- 标志寄存器:存储CPU运算后的状态和控制标志。
- EFLAGS(32位) / RFLAGS(64位)
- 控制寄存器:控制CPU的操作模式(如开启分页、保护模式)。只有操作系统内核能访问。比如CR0 包含系统控制标志,如保护模式使能位(PE)、分页使能位(PG)。页目录基址寄存器 CR3,存放当前进程页表的物理地址,是 MMU 的核心。
- CR0, CR1, CR2, CR3, CR4...
2.1.2 微架构
微架构是 实现 ISA 的硬件逻辑设计。不同 CPU(如 Intel Core i9、AMD Ryzen 9)虽然都属于 x86 指令集,但它们的微架构不同(比如 Intel 的 Alder Lake、AMD 的 Zen 5)。微架构的主要组成部分包括:
-
取指单元(Fetch Unit)
负责从缓存或内存中读取即将执行的指令,并预先存入指令队列。现代 CPU 通常具备 分支预测器(Branch Predictor),提前预测跳转结果以减少流水线停顿。
-
译码单元(Decode Unit)
将复杂的 x86 指令翻译成更简单的 微操作(Micro-ops 或 µops)。内部的执行单元通常是以类似 RISC 风格的微操作执行的。
-
调度与执行单元(Execution Engine)
将译码后的微操作交由不同的功能单元执行:ALU(算术逻辑单元),负责整数运算。FPU(浮点单元),负责浮点计算。SIMD/AVX 单元,负责并行向量计算。Load/Store 单元,负责数据读写。支持乱序执行[3](Out-of-Order Execution)与超标量[4](Superscalar)技术。
乱序执行是现代 CPU 性能的关键。x86 乱序执行的一些关键点:寄存器重命名,解决指令间的假数据依赖,让更多指令可以并行执行;保留站,微操作在这里等待他们所需的操作数就绪;调度器,监视保留站,一旦某个微操作的操作数就绪,就把它分派给一个空闲的执行单元,不严格按照原始程序顺序,从而实现“乱序执行”。
2.1.3 存储与缓存层次(Memory Hierarchy)
x86 处理器采用多级缓存结构来解决 CPU 与内存速度差异,这一点基本所有架构是一致的:
- L1 缓存:分为指令缓存与数据缓存,速度最快。
- L2 缓存:容量更大,访问稍慢。
- L3 缓存:多个核心共享,提升整体数据吞吐。
- 主存(DRAM):由内存控制器访问。
- 内存管理单元 MMU:集成在CPU内,负责将程序使用的虚拟地址通过查询页表转换为物理地址。
2.1.4 控制单元与系统管理
- 实模式(Real Mode):16 位寻址,兼容早期 DOS。
- 保护模式(Protected Mode):支持多任务与内存保护。
- 长模式(Long Mode):64 位寻址。
- 系统管理模式(SMM):用于硬件级控制(如电源管理)。
- 虚拟化扩展:Intel VT-x、AMD-V 支持虚拟机运行。
附录
x86 指令集的发展
- x86 (16位)。始于 Intel 8086/8088处理器。16位寄存器(AX, BX, CX...),1MB 内存寻址空间,使用分段内存模型。
- x86-32 / IA-32。由 80386 处理器引入。扩展到 32 位寄存器(EAX, EBX, ECX...)。引入保护模式,支持虚拟内存、内存保护和多任务。寻址空间扩展到 4GB。这是现代操作系统(如Windows XP, Linux)真正兴起的基础。
- x86-64 / AMD64 / Intel 64。由 AMD 首先设计并推广,后来被 Intel 采纳。寄存器扩展到64位(RAX, RBX...),并新增了8个通用寄存器(R8-R15)。寻址空间理论上达到 2^64 字节,实际上目前是 48 位或 57 位。几乎完全向后兼容 32 位代码。这是我们现在使用的桌面、服务器 CPU 的基准指令集。
- MMX。Pentium MMX 处理器,目的是加速多媒体处理(如图像、音频),使用 80x87 浮点寄存器的尾数部分,定义了 8 个 64 位寄存器(MM0-MM7),进行单指令多数据 SIMD操作,即一条指令可以同时处理多个小位宽的数据(如 8 个 8 位像素)。
- SSE。Pentium III 处理器引入,为了解决 MMX 的一些缺陷,并提升浮点性能。引入了独立的 128 位寄存器(XMM0-XMM7),后来增加到 16 个(XMM0-XMM15)。支持单精度浮点数的 SIMD 操作。SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2 是一系列连续的扩展,功能不断增强,例如 SSE2 加入了双精度浮点数和整数的 SIMD 操作。
- AVX。Sandy Bridge架构(Intel)和 Bulldozer 架构(AMD)。进一步扩展了 SIMD 能力。将寄存器宽度从128位扩展到256位(YMM0-YMM15)。引入了新的三操作数指令格式,更灵活。AVX, AVX2, AVX-512 是更强大的扩展。其中AVX-512将寄存器进一步扩展到512位(ZMM0-ZMM31),并引入了掩码寄存器等强大功能,主要用于高性能计算和服务器领域。
什么是 SIMD
x86 的 SIMD 技术经历了以下几个主要阶段,其核心是寄存器宽度和功能的不断扩展:
| 技术 | 引入时间 | 寄存器宽度 | 典型数据容量 | 特点 |
|---|---|---|---|---|
| MMX | 1997 | 64位 | 8个8位整数 / 4个16位整数 | 使用浮点寄存器,主要处理整数 |
| SSE | 1999 | 128位 (XMM) | 4个32位单精度浮点数 | 革命性,引入独立寄存器,支持浮点 |
| SSE2/3/4 | 2000s | 128位 | 2个64位双精度浮点数 / 16个8位整数 | 功能不断增强和完善 |
| AVX | 2011 | 256位 (YMM) | 8个32位单精度浮点数 | 更宽的寄存器,新指令格式 |
| AVX-512 | 2013 | 512位 (ZMM) | 16个32位单精度浮点数 | 极度强大,主要用于服务器/HPC |
在传统的标量运算中,如果你要对两个数组进行加法运算:
for (int i = 0; i < 4; i++) {
c[i] = a[i] + b[i];
}
CPU 需要执行大致需要执行4条加法指令:
- 取
a[0]和b[0],相加,结果存入c[0]。 - 取
a[1]和b[1],相加,结果存入c[1]。 - 取
a[2]和b[2],相加,结果存入c[2]。 - 取
a[3]和b[3],相加,结果存入c[3]。
而在SIMD模式下,假设我们有一个 128 位的 SIMD 寄存器:
- 我们可以将
a[0]到a[3]这4个32位整数,一次性打包加载到一个 128 位的 SIMD 寄存器中。 - 同样,将
b[0]到b[3]也打包加载到另一个 SIMD 寄存器中。 - 然后,执行一条 SIMD 加法指令,这条指令会同时将
a[0]+b[0],a[1]+b[1],a[2]+b[2],a[3]+b[3]这4个加法计算一次性完成。 - 最后,将结果一次性存回内存的
c[0]到c[3]。
只执行了1条加法指令。
SIMD 是一种通过一条指令同时处理多个数据的并行计算技术。它是现代CPU提升数据吞吐量、实现高性能计算的最关键手段之一。 当你听到 SSE、AVX 这些术语时,它们就是 x86 平台上 SIMD 指令集的具体实现。编译器(如GCC、Clang、MSVC)通常可以自动将合适的循环代码向量化,生成 SIMD 指令,而程序员也可以使用内置函数来手动编写高性能的 SIMD 代码。
Steady Progress!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号