Hadoop之HA高可用
1、集群规划
| ZooKeeper | NameNode | DataNode | ResourceManager | NodeManage | JN | ZKFC | |
|---|---|---|---|---|---|---|---|
| master | 1 | 1 | 1 | 1 | 1 | ||
| node1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| node2 | 1 | 1 | 1 | 1 |
2、前提
1、
Zookeeper集群安装完毕
2、jdk安装完成等等
3、免密配置
注意:两台NameNode机器 (master、node1)都需要配置免密登录



4、修改hadoop配置文件
4.1、hdfs高可用
1、修改core-site.xml 添加如下配置文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,node1:2181,node2:2181</value>
</property>
</configuration>
2、修改hdfs-site.xml文件,添加如下内容
<configuration>
<!-- 指定hdfs元数据存储的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/data/namenode</value>
</property>
<!-- 指定hdfs数据存储的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/data/datanode</value>
</property>
<!-- 数据备份的个数 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 关闭权限验证 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 开启WebHDFS功能(基于REST的接口服务) -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- //////////////以下为HDFS HA的配置////////////// -->
<!-- 指定hdfs的nameservices名称为mycluster -->
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
<!-- 指定cluster的两个namenode的名称分别为nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>nn1,nn2</value>
</property>
<!-- 配置nn1,nn2的rpc通信端口 -->
<property>
<name>dfs.namenode.rpc-address.cluster.nn1</name>
<value>master:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.nn2</name>
<value>node1:8020</value>
</property>
<!-- 配置nn1,nn2的http通信端口 -->
<property>
<name>dfs.namenode.http-address.cluster.nn1</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.nn2</name>
<value>node1:50070</value>
</property>
<!-- 指定namenode元数据存储在journalnode中的路径 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;node1:8485;node2:8485/cluster</value>
</property>
<!-- 指定journalnode日志文件存储的路径 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/data/journal</value>
</property>
<!-- 指定HDFS客户端连接active namenode的java类 -->
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制为ssh -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 指定秘钥的位置 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 开启自动故障转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
3、将修改后的文件同步到另外两台机器
注意:此时只是core-site.xml与hdfs-site.xml两个配置文件与单namenode的hadoop集群不同,其它配置文件和单节点的相同,已经省略!!!
scp -r /usr/local/soft/hadoop-2.7.6/etc/hadoop/ node1:/usr/local/soft/hadoop-2.7.6/etc/
4、删除之前hadoop的存储文件
rm -rf /usr/local/soft/hadoop-2.7.6/tmp
启动Zookeeper集群,三台机器都要启动
zkServer.sh start

5、启动JN 存储hdfs元数据
三台三台机器 都要执行命令
hadoop-daemon.sh start journalnode
jps查看进程

6、格式化namenode
在一台namenode上面执行,master与node1上都可以,本文选择在master上面执行
hdfs namenode -format
启动当前的namenode
hadoop-daemon.sh start namenode


7、执行同步
在没有格式化的
namenode上执行,本文没格式化的namenode是node1
在node1上执行
hdfs namenode -bootstrapStandby

8、格式化ZK
在已经启动的
namenode上面执行(master)
!!一定要先 把zk集群正常 启动起来
hdfs zkfc -formatZK

9、启动hdfs集群
在启动了
namenode的节点上执行(master)
start-dfs.sh
查看master与node1上的进程


至此,hdfs高可用搭建完成,有两个namenode,一个在master上,另一个在node1上
4.2、yarn高可用
1、修改yarn-site.xml文件,并添加如下内容
<configuration>
<!-- NodeManager上运行的附属服务,需配置成mapreduce_shuffle才可运行MapReduce程序 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 配置Web Application Proxy安全代理(防止yarn被攻击) -->
<property>
<name>yarn.web-proxy.address</name>
<value>master:8888</value>
</property>
<!-- 开启日志 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 配置日志删除时间为7天,-1为禁用,单位为秒 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 修改日志目录 -->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/logs</value>
</property>
<!-- 配置nodemanager可用的资源内存 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<!-- 配置nodemanager可用的资源CPU -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
<!-- //////////////以下为YARN HA的配置////////////// -->
<!-- 开启YARN HA -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 启用自动故障转移 -->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 指定YARN HA的名称 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarncluster</value>
</property>
<!-- 指定两个resourcemanager的名称 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 配置rm1,rm2的主机 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node1</value>
</property>
<!-- 配置YARN的http端口 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node1:8088</value>
</property>
<!-- 配置zookeeper的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,node1:2181,node2:2181</value>
</property>
<!-- 配置zookeeper的存储位置 -->
<property>
<name>yarn.resourcemanager.zk-state-store.parent-path</name>
<value>/rmstore</value>
</property>
<!-- 开启yarn resourcemanager restart -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 配置resourcemanager的状态存储到zookeeper中 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 开启yarn nodemanager restart -->
<property>
<name>yarn.nodemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 配置nodemanager IPC的通信端口 -->
<property>
<name>yarn.nodemanager.address</name>
<value>0.0.0.0:45454</value>
</property>
</configuration>
2、mapred-site.xml文件,并添加如下内容
<configuration>
<!-- 指定MapReduce计算框架使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定jobhistory server的rpc地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<!-- 指定jobhistory server的http地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
<!-- 开启uber模式(针对小作业的优化) -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- 配置启动uber模式的最大map数 -->
<property>
<name>mapreduce.job.ubertask.maxmaps</name>
<value>9</value>
</property>
<!-- 配置启动uber模式的最大reduce数 -->
<property>
<name>mapreduce.job.ubertask.maxreduces</name>
<value>1</value>
</property>
</configuration>
将修改的yarn-site.xml与mapred-site.xml同步到另外两台机器上
scp -r /usr/local/soft/hadoop-2.7.6/etc/hadoop/ node1:/usr/local/soft/hadoop-2.7.6/etc/
3、启动yarn
在
master启动start-yarn.sh

4、在另外一台主节点上启动RM(node1)
yarn-daemon.sh start resourcemanager

至此查看所有进程 jps,与我们集群规划的所有进程一致,Hadoop的HA高可用安装完毕


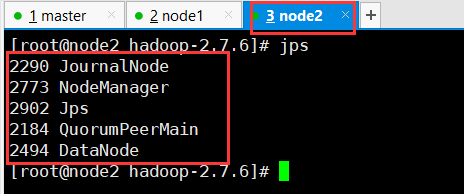
5、测试高可用
1、在浏览器查看
输入
master与node1地址,
看到master处于active状态
node1处于standby状态


2、手动杀死master中的namenode进程
kill -9 2718

3、再次访问wed界面
发现
node1已经处于active状态了

4、重新启动master上的namenode
hadoop-daemon.sh start namenode
查看master状态
发现其已经变成standby状态了



 浙公网安备 33010602011771号
浙公网安备 33010602011771号