
Python爬取百度搜索风云榜实时热点.
百度搜索风云榜:http://top.baidu.com/
源码:
1 import os 2 import json 3 from datetime import datetime 4 from datetime import timezone 5 from datetime import timedelta 6 from collections import OrderedDict 7 8 import requests 9 from bs4 import BeautifulSoup 10 11 12 def get_utc8now(): 13 utcnow = datetime.now(timezone.utc) 14 utc8now = utcnow.astimezone(timezone(timedelta(hours=8))) 15 return utc8now 16 17 18 def save_as_json(filename, records): 19 dict_obj = {} 20 if os.path.exists(filename): 21 with open(filename, 'r', encoding='utf-8') as f: 22 dict_obj = json.load(f, object_pairs_hook=OrderedDict) 23 time_str = str(get_utc8now()) 24 for keyword, search_index in records: 25 time_count_dict = {'time': time_str, 'count': search_index} 26 dict_obj.setdefault(keyword, []).append(time_count_dict) 27 with open(filename, 'w', encoding='utf-8') as f: 28 json.dump(dict_obj, f, indent=4, separators=(',',': '), 29 ensure_ascii=False, sort_keys=False) 30 31 32 def crawl_baidu_top(buzz_no=1): 33 response = requests.get('http://top.baidu.com/buzz?b={}'.format(buzz_no)) 34 response.encoding = 'gb18030' 35 soup = BeautifulSoup(response.text, 'html.parser') 36 table_tag = soup.find('table', {'class': 'list-table'}) 37 item_tags = table_tag.find_all('tr') 38 keywords, search_indices = [], [] 39 for item in item_tags: 40 keyword_tag = item.find('td', {'class': 'keyword'}) 41 last_tag = item.find('td', {'class': 'last'}) 42 if (keyword_tag is not None) and (last_tag is not None): 43 keyword_title_tag = keyword_tag.find('a', {'class': 'list-title'}) 44 keywords.append(keyword_title_tag.text.strip()) 45 search_indices.append(last_tag.text.strip()) 46 return list(zip(keywords, search_indices)) 47 48 49 if __name__ == '__main__': 50 now = get_utc8now() 51 year_str = now.strftime('%Y') 52 date_str = now.strftime('%Y%m%d') 53 os.makedirs(year_str, exist_ok=True) 54 filename = os.path.join(year_str, '{} 实时热点.json'.format(date_str)) 55 56 records = crawl_baidu_top() 57 save_as_json(filename, records)
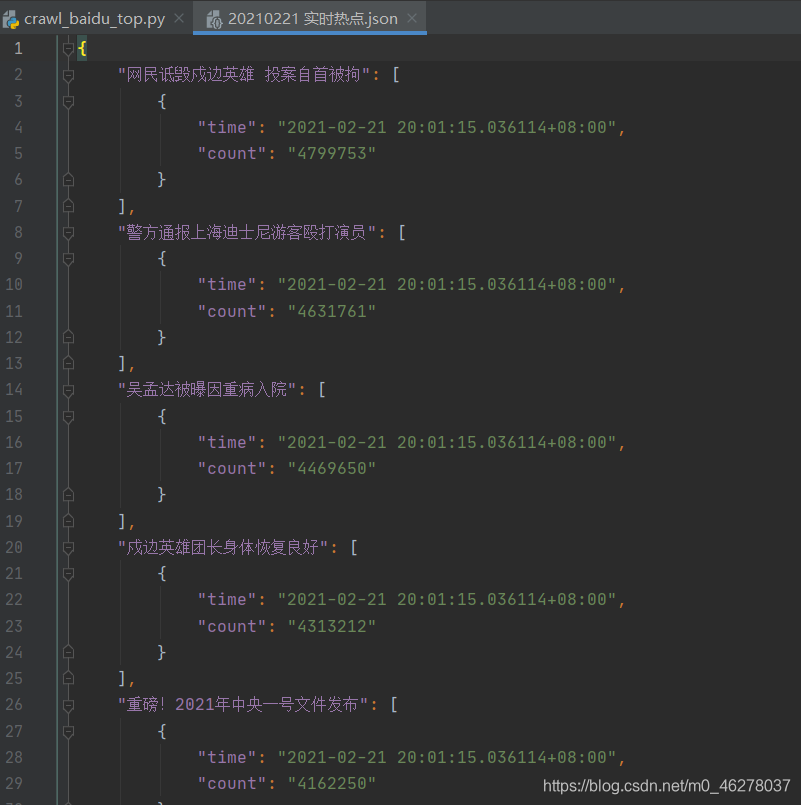
运行:
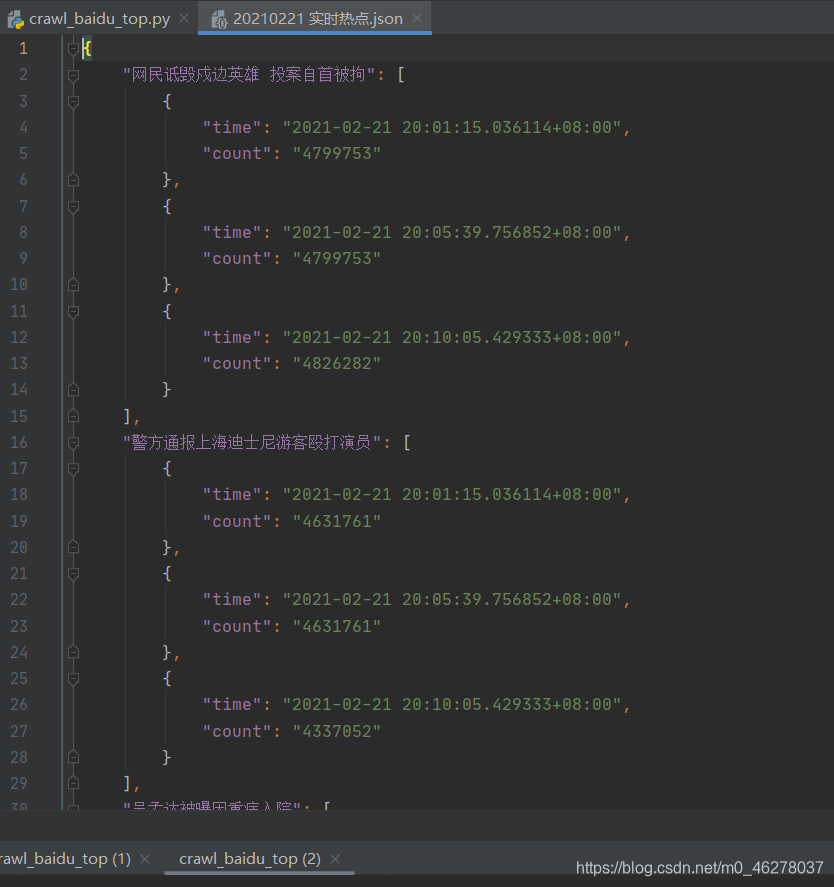
再次运行:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号