
冒泡排序是最基本的排序方法,但是最基本的冒泡排序方法有一些不足,他只能死板的进行意义比较,不管是否已经排序完成。
传统的冒泡排序方法代码如下:
for ( i = 0; i < len-1; i++) { for (int j = 0; j < len - i - 1; j++) { if (a[j] < a[j + 1]) swap(a[j], a[j + 1]); } }
如果加入一位change位来判断是否已经排序完成,若change为0则说明没有两两位置交换的数据,则说明已经排序完成,用此方法进行改进则可以节约运算时间,代码如下:
or (int j = 0; j < len - 1 - i; j++) if (b[j] < b[j + 1]) { swap(b[j], b[j + 1]); change = 1; }
以下代码为两种方法运算时间对比的全部代码:
#include<iostream> #include<time.h> #include<stdlib.h> using namespace std; void swap(int* a,int* b) { int m; m = *a; *a = *b; *b = m; } int main() { int i; int a[10000],b[10000]; int len = 10000; double start, finish,time1; int change=1; srand((unsigned)time(NULL)); for (i = 0; i <len; i++) { a[i] = 1+rand()%9999; b[i] = a[i]; } start = clock(); for ( i = 0; i < len-1; i++) { for (int j = 0; j < len - i - 1; j++) { if (a[j] < a[j + 1]) swap(a[j], a[j + 1]); } } finish = clock(); time1 = finish - start; cout << "传统的冒泡排序所用时间为:" << time1 << endl; start = clock(); for (i = 0; i < len - 1 && change != 0; i++) { change = 0; for (int j = 0; j < len - 1 - i; j++) if (b[j] < b[j + 1]) { swap(b[j], b[j + 1]); change = 1; } } finish = clock(); time1 = finish - start; cout << "改进后的冒泡排序所用时间为:" << time1 << endl << endl; }
结果如下:
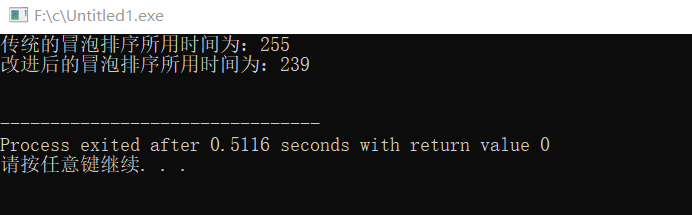
结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号