浏览器中的中文乱码问题(GBK还是UTF-8)
代码编写过程中,遇到中文的乱码问题,我们一定会想到修改编码为UTF-8,但这并不一定对所有的情况都适用。
编码的简单流程:
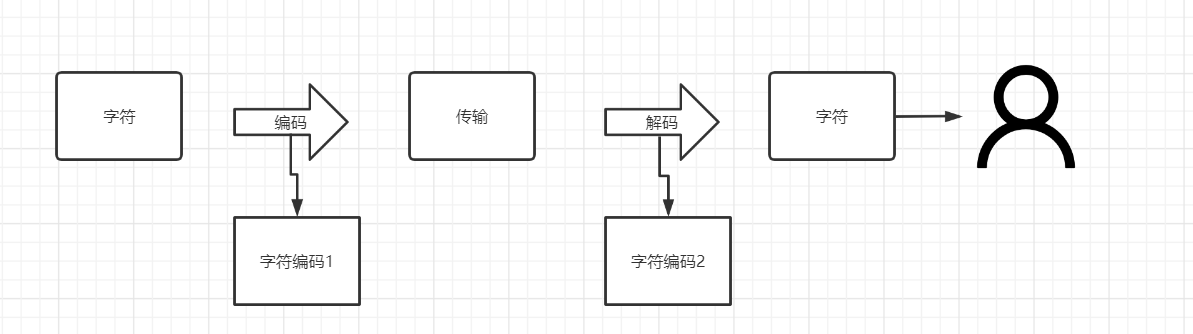
我们编写的中文字符最终要在浏览器中显示,需要经过编码和解码,编码和解码需要满足两个条件才能使显示出来的字符是正常不乱码的
-
编码方式和解码方式要支持所使用的文字(例如中文);
-
编码方式和解码方式要相同。
GBK和UTF-8都是支持中文的,但浏览器使用的解码方式大多都是GBK模式的。因此我们使用UTF-8来编码,最终浏览器使用GBK来解码,这就产生了乱码!
代码编写时使用UTF-8来编码,并且告诉浏览器“我使用的是UTF-8来编码,请你也使用UTF-8进行解码操作,否则将产生乱码问题!”
因此两行代码即可解决:
resp.setCharacterEncoding("utf-8"); //编码方式
resp.setContentType("text/html;charset=utf-8"); //要求浏览器要使用的解码方式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号