集成学习(Ensemble Learning)
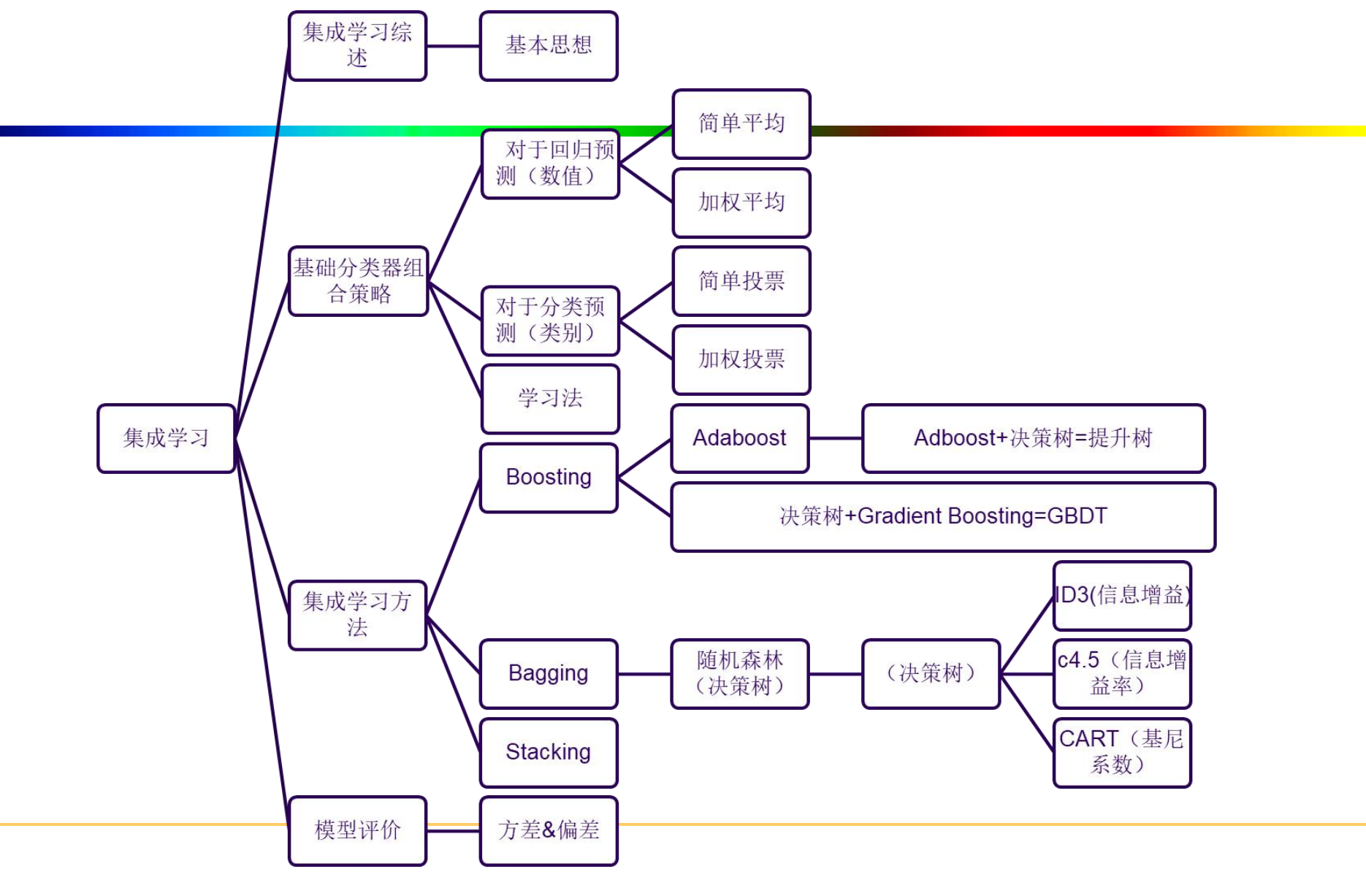
基本思想
- 集成学习:使用一系列学习器进行学习,并使用某种规则把各个学习结果进行
整合从而获得比单个学习器更好的学习效果的一种机器学习方法。 - 如果把单个分类器比作一个决策者的话,集成学习的方法就相当于多个决策者共同进行一项决策。
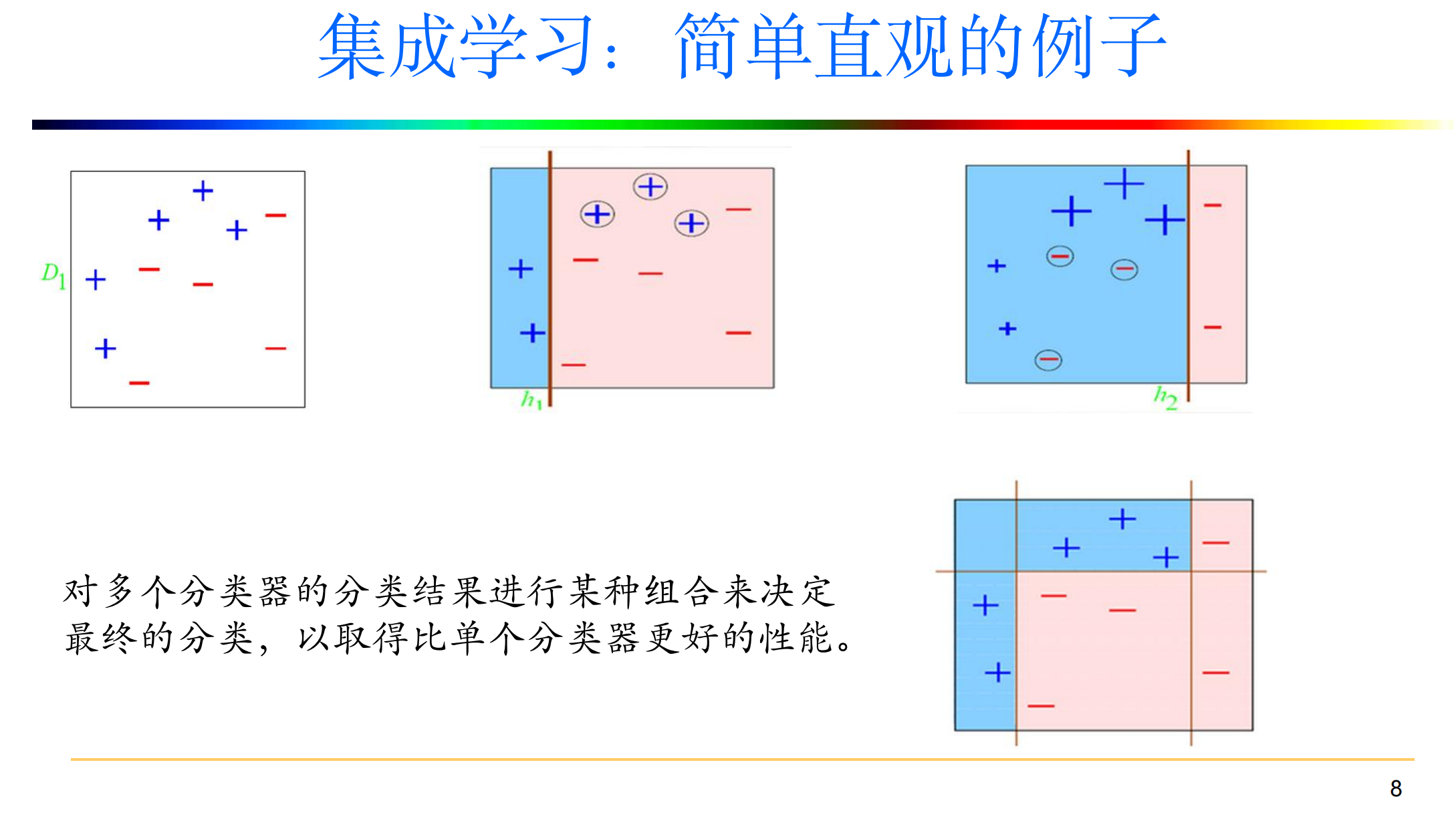
弱分类器之间是怎样的关系?
- 所有的个体学习器都是同一种类型,即同质的;
- 所有的个体学习器不全是同一种类的,即异质的
- 通常使用多个同质学习器来解决同一问题:
- 如个体学习器均为决策树时,称为决策树集成;
- 如个体学习器均为神经网络时,称为神经网络集成;
2.如何选择学习器?
- 考虑准确性和多样性
- –准确性:指的是个体学习器不能太差,要有一定的准确度;
- –多样性:个体学习器之间的输出要具有差异性

3.怎样组合弱分类器?
- 组合策略:
- 平均法
- 投票法
- 学习法
3.1 平均法(对于数值类的回归预测问题)
- 思想:对于若干个弱学习器的输出进行平均得到最终的预测输出。
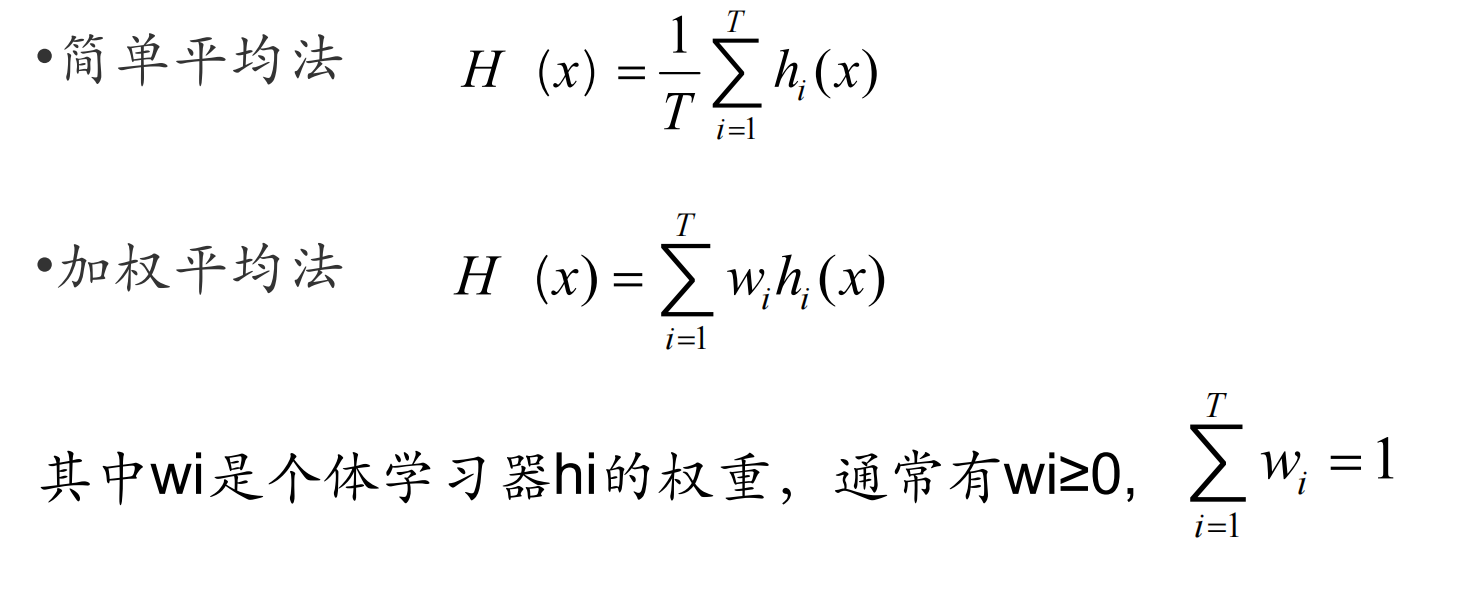
3.2 投票法 (对于分类问题的预测)
-
思想:多个基本分类器都进行分类预测,然后根据分类结果用某种投票的原则
进行投票表决,按照投票原则使用不同投票法。 -
投票原则:一票否决、一致表决、少数服从多数
-
阈值表决:首先统计出把实例x划分为Ci和不划分为Ci的分类器数目分别是多少,
然后当这两者比例超过某个阈值的时候把x划分到Ci。
3.3 学习法
- 思想:不是对弱学习器的结果做简单的逻辑处理,而是再加上一层学习器,分为2层。
- 第一层是用不同的算法形成T个弱分类器,同时产生一个与原数据集大小相同的新数据集,利用这个新数据集和一个新算法构成第二层的分类器。
- 我们将弱学习器称为初级学习器,将用于结合的学习器称为次级学习器。对于测试集,我们首先用初级学习器预测一次,得到次级学习器的输入样本,再用
次级学习器预测一次,得到最终的预测结果。 - 代表方法是Stacking
4. 学习方法
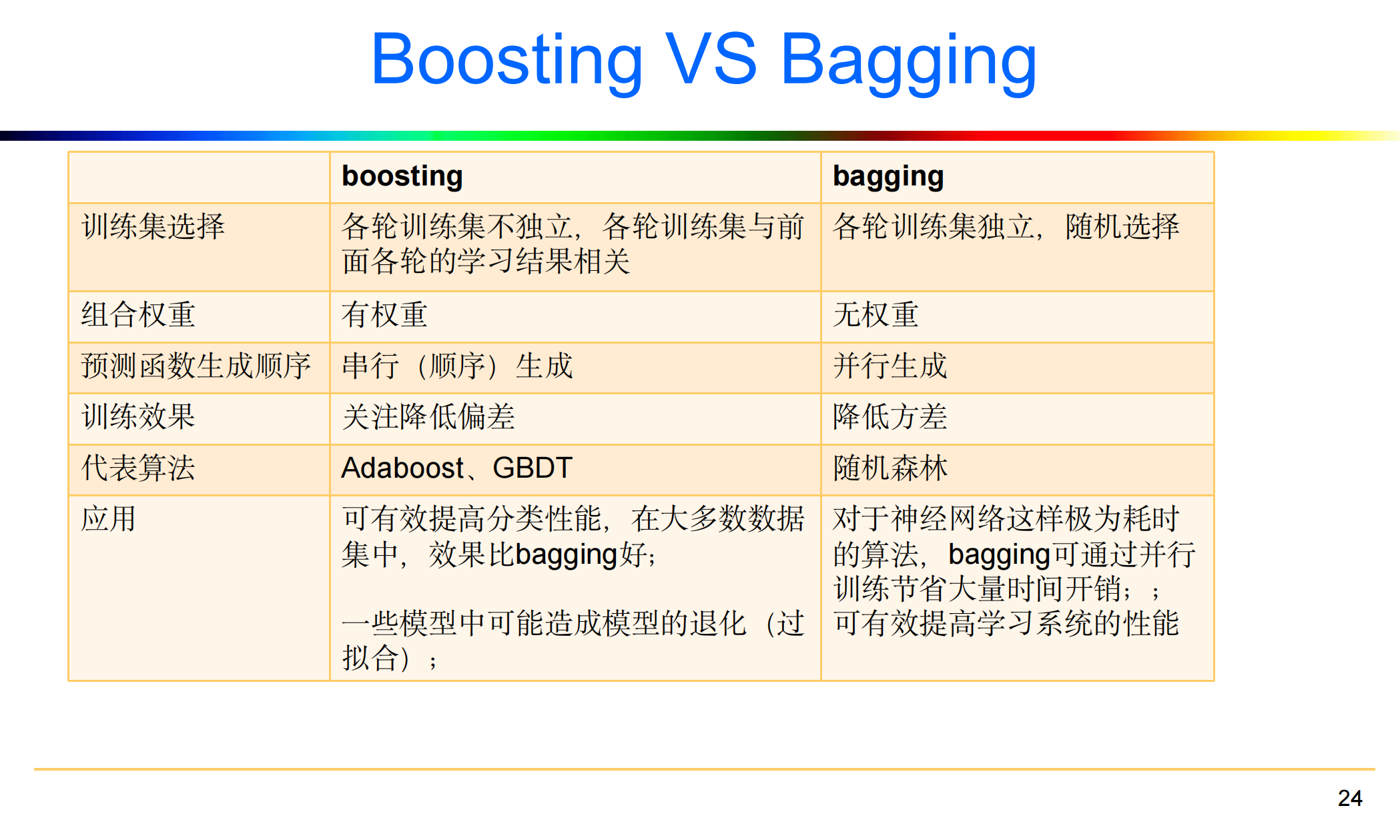
- 根据个体学习器的生成方式,目前的集成学习方法大致可分为两类,
- Boosting:个体学习器间存在强依赖关系,必须串行生成的序列化方法;
串行:下一个分类器只在前一个分类器预测不够准的实例上进行训练或检验。 - Bagging:个体学习器间不存在强依赖关系,可同时生成的并行化方法。
并行:所有的弱分类器都给出各自的预测结果,通过组合把这些预测结果转化为最终结果。
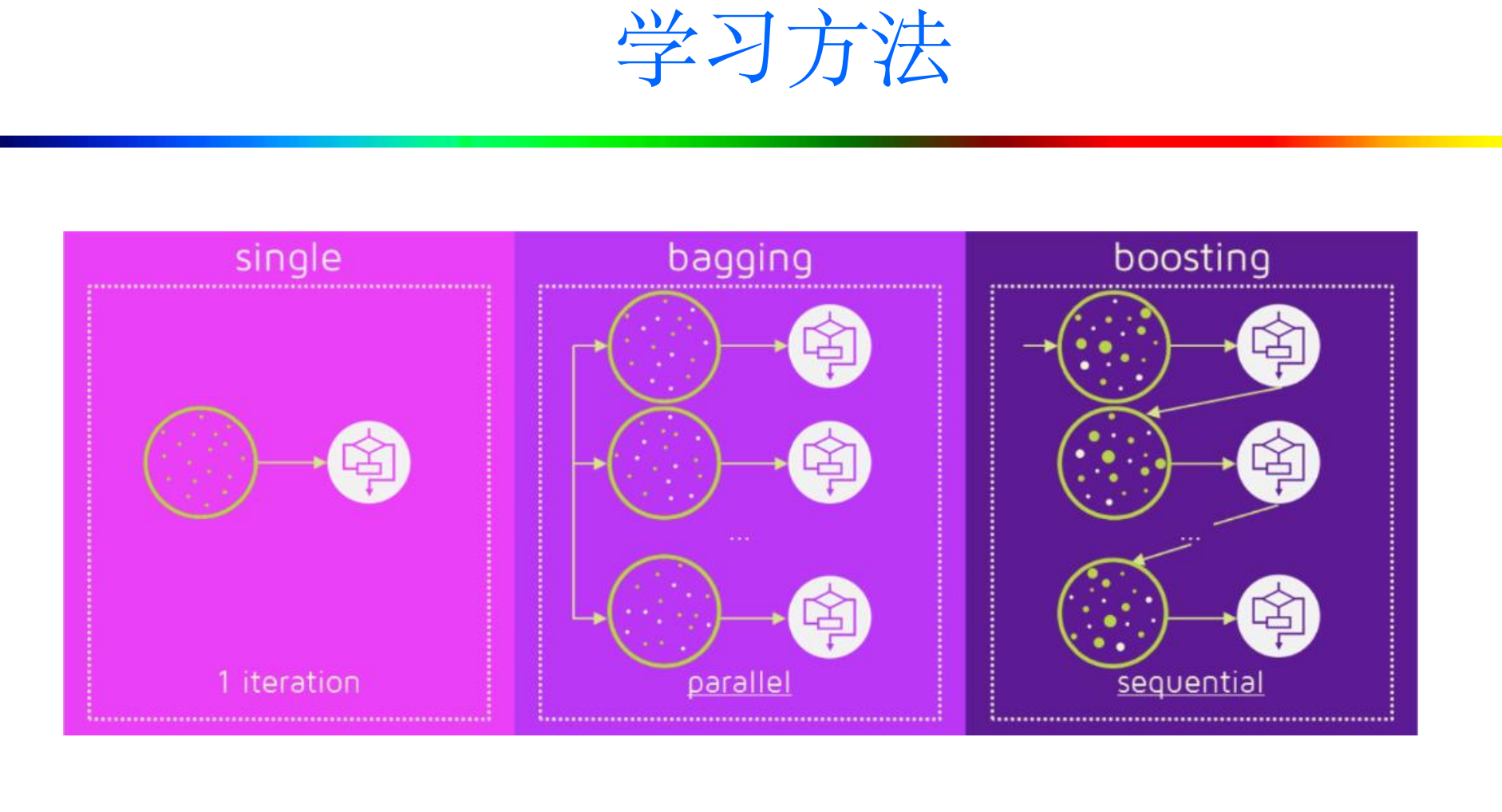
- Boosting:个体学习器间存在强依赖关系,必须串行生成的序列化方法;
5. 从偏差-方差分解的角度理解集成学习
-
偏差(bias) :描述的是预测值的期望与真实值之间的差距。偏差越大,越
偏离真实数据,如下图第二行所示。 -
方差(variance) :描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散,如下图右列所示。
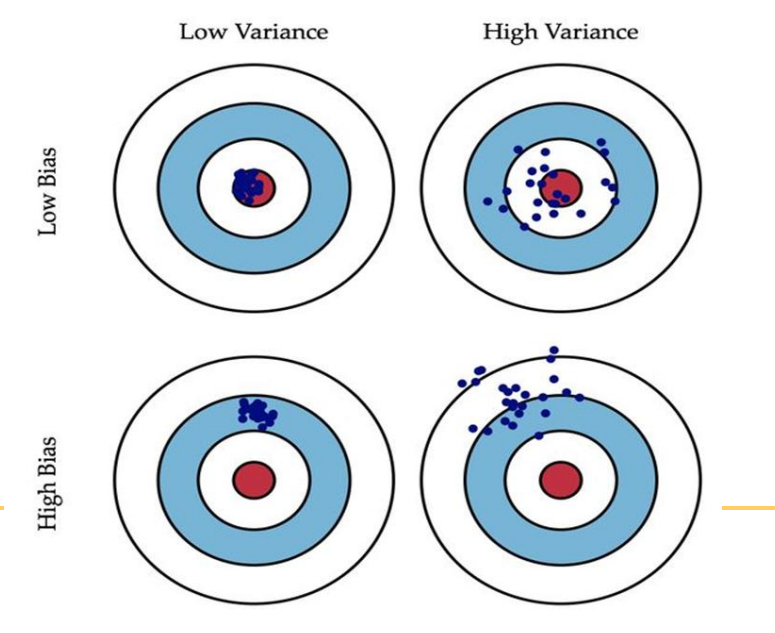
-
偏差刻画了学习算法本身的拟合能力。
-
方差度量了同样大小的数据集的变动所导致的学习性能的变化。刻画了数据扰动所造成的影响。
-
Boosting主要关注降低偏差
-
Boosting思想,对判断错误的样本不停的加大权重,为了更好地拟合当前数据,所以降低了偏差,因此Boosting能基于泛化性能相当弱的学习器构建出很强的集成。
-
boosting是把许多弱的分类器组合成一个强的分类器。
-
-
Bagging主要是降低方差
- Bagging思想,随机选择部分样本来训练处理不同的模型,再综合来减小方差,
因此它在不剪枝决策树、神经网络等易受样本扰动的学习器上效果更明显。 - bagging是对许多强(甚至过强)的分类器求平均。
- Bagging思想,随机选择部分样本来训练处理不同的模型,再综合来减小方差,
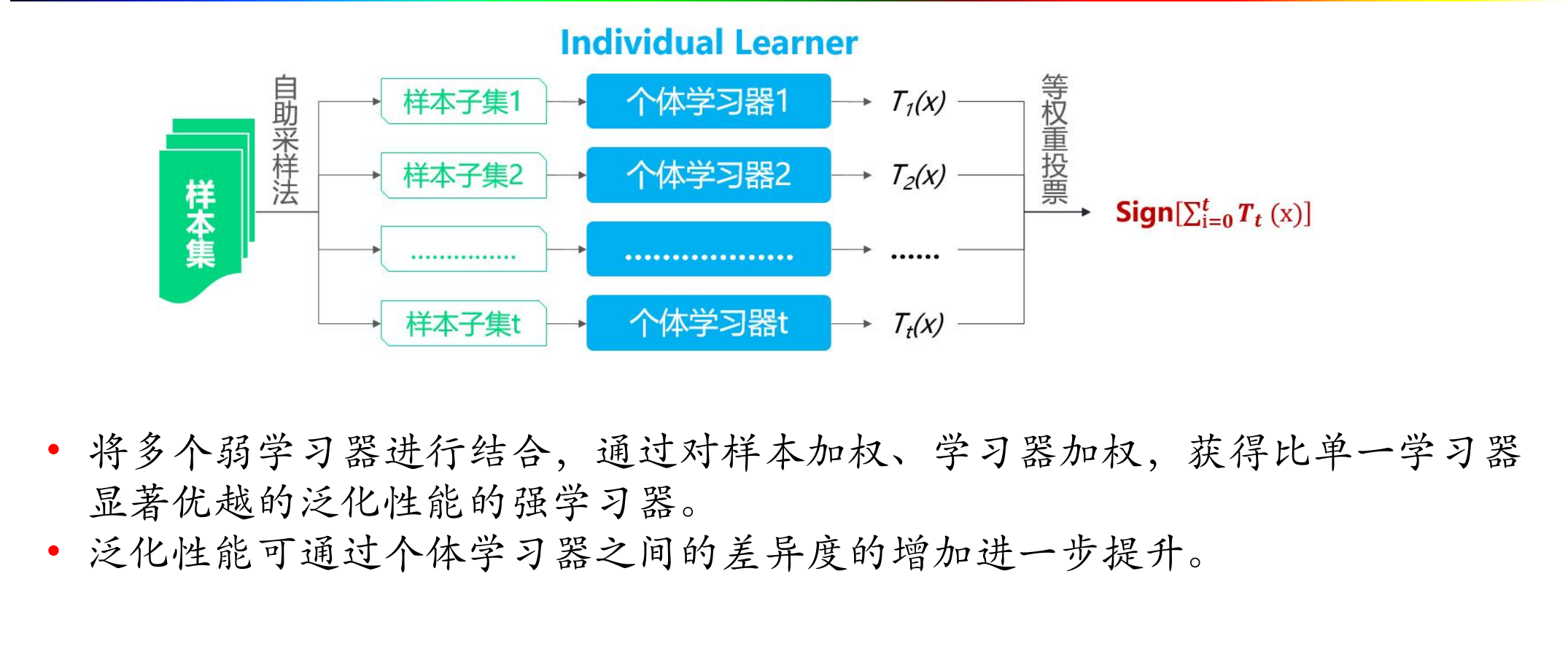
6. 集成学习方法
6.1 Boosting


6.2 Bagging

6.3 Boosting VS Bagging
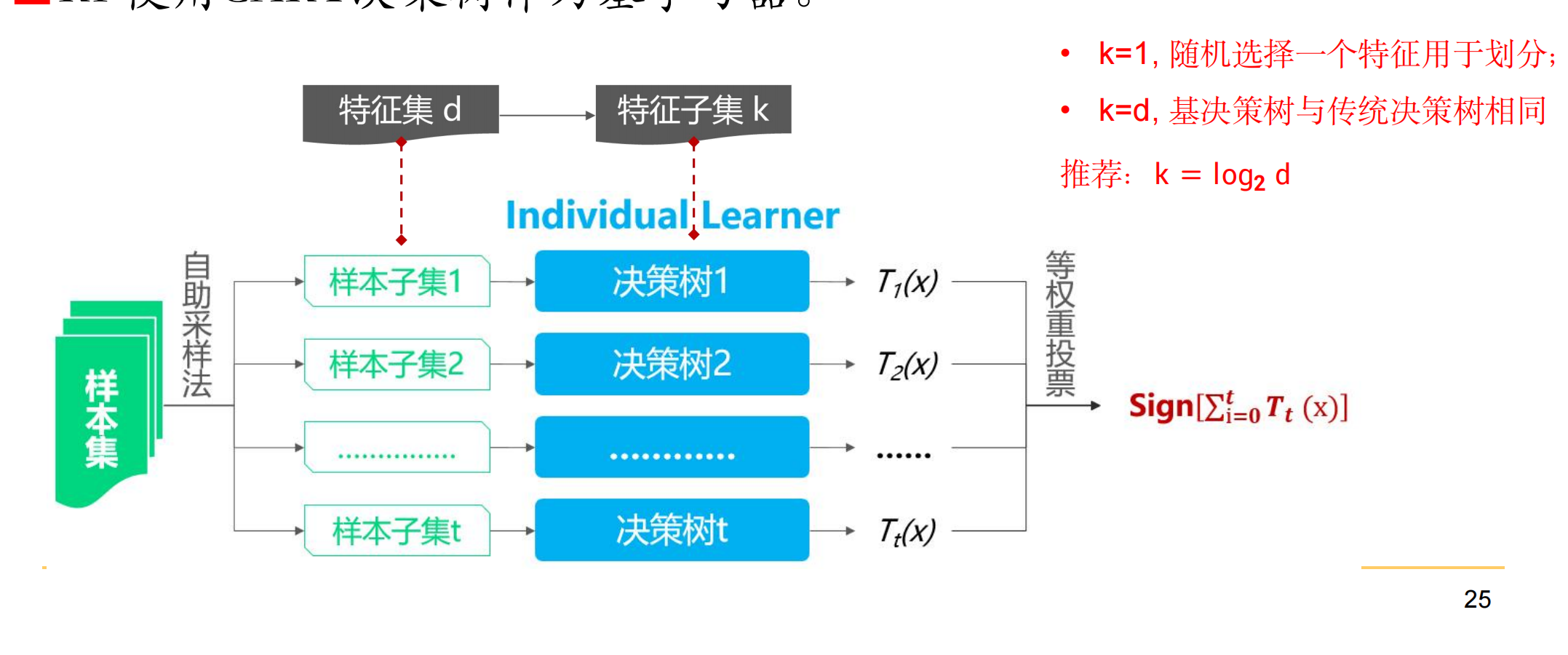
7. 随机森林
- 随机森林( Random Forest ,RF )以决策树为基学习器的bagging算法
- RF使用CART决策树作为基学习器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号