梯度下降法
1. 基础知识
1.1 梯度
-
梯度是某一点最大的方向导数,沿梯度方向函数有最大的变化率(正向增加,逆向减少)
-
代价函数J沿梯度的负方向下降最快

1.2 损失函数、代价函数、目标函数
-
损失函数(Loss Function)是用来衡量算法拟合数据的好坏程度,具体评价的是模型的预测值与真实值之间的不一致程度。损失函数是定义在单个样本上的,算的是一个样本的误差。
-
代价函数(Cost Function )是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。
-
目标函数(Object Function)定义为:最终需要优化的函数。等于经验风险+结构风险(也就是Cost Function + 正则化项)
-
目标函数是最大化或者最小化,而代价函数是最小化
1.3 权值,权重,模型参数
-
权值,权重,模型参数,三者本是上是一个东西。
-
模型参数是模型内部的配置变量,其值可以根据数据进行估计。它们用于表示模型对数据的学习结果,并且在模型进行预测时是必需的。
2. 定义
-
梯度就是导数
-
梯度下降法就是一种通过求代价的导数来寻找代价函数最小化的方法。
-
梯度下降目的是找到代价函数最小化时的取值所对应的自变量的值,目的是为了找自变量X。
3. 梯度下降法直观理解
-
梯度下降法的基本思想可以类比为一个下山的过程,如下图所示函数看似为一片山林,红色的是山林的高点,蓝色的为山林的低点,蓝色的颜色越深,地理位置越低,则图中有一个低点,一个最低点。

-
为了寻找最低点,具体来说就是,以该点当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着山的高度下降的方向走,然后每走一段距离,都反复采用同一个方法,最后就能成功的抵达山谷。
4. 梯度下降法基本步骤
按照梯度下降算法的思想,它将按如下操作达到最低点:
-
第一步,明确自己现在所处的位置
-
第二步,找到相对于该位置而言下降最快的方向
-
第三步, 沿着第二步找到的方向走一小步,到达一个新的位置,此时的位置肯定比原来低
-
第四部, 回到第一步
-
第五步,终止于最低点
按照以上5步,最终达到最低点,这就是梯度下降的完整流程。
5. 算法上理解

-
定义一个公式如上图所示,J是关于Θ的一个函数,我们在山林里当前所处的位置为Θ0点,要从这个点走到J的最小值点,也就是山底。首先我们先确定前进的方向,也就是梯度的反向,然后走一段距离的步长,也就是α,走完这个段步长,就到达了Θ1这个点。

-
α在梯度下降算法中被称作为学习率或者步长,意味着我们可以通过α来控制每一步走的距离,以保证不要步子跨的太大错过了最低点。同时也要保证不要走的太慢。所以α的选择在梯度下降法中往往是很重要的。

我们假设有多变量目标函数为,$$ J(\theta) =\theta1 ^ {2} + \theta2^{2}$$现在要通过梯度下降法计算这个函数的最小值。
我们假设初始的起点为:$$
\theta^{0} = (1, 3),$$
初始的学习率为:$$\alpha = 0.1, $$
函数的梯度为:
进行多次迭代:

我们发现,已经基本靠近函数的最小值点
现在有一个线性回归的目标函数,为了方便,不带正则项,目标函数定义为:
此公示中,各参数如下:
m 表示为数据集中样本的个数,表示有m个样本;
½是一个常量,这样是为了在求梯度的时候,二次方乘下来就和这里的½抵消了,自然就没有多余的常数系数,方便后续的计算,同时对结果不会有影响;
y 是数据集中每个样本的实际值值;
f 是我们的预测函数,根据每一个输入x,根据θ计算得到预测的y值;
6. 梯度下降法步骤进一步理解
先对 $ \theta $ 赋初值,这个值可以是随机的,也可以让 $ \theta $ 是一个全0的向量。
改变\(\theta\)的值,使得\(J(\theta)\)按梯度下降的方向进行减少

其更新过程可写成:

其中“:=”为赋值的含义;α为学习速率,又叫步长;α右边的是J(θ)对θ求的偏导(偏导就是对θ向量中的每个元素分别求导)。
这个公式的含义就是,先初始确定一个θ的值,然后用(1)式计算新的w值,反复迭代。我们不断更新参数θ的值,直到J(θ)取得最小值时,停止迭代。
7. 梯度下降法的关键因素
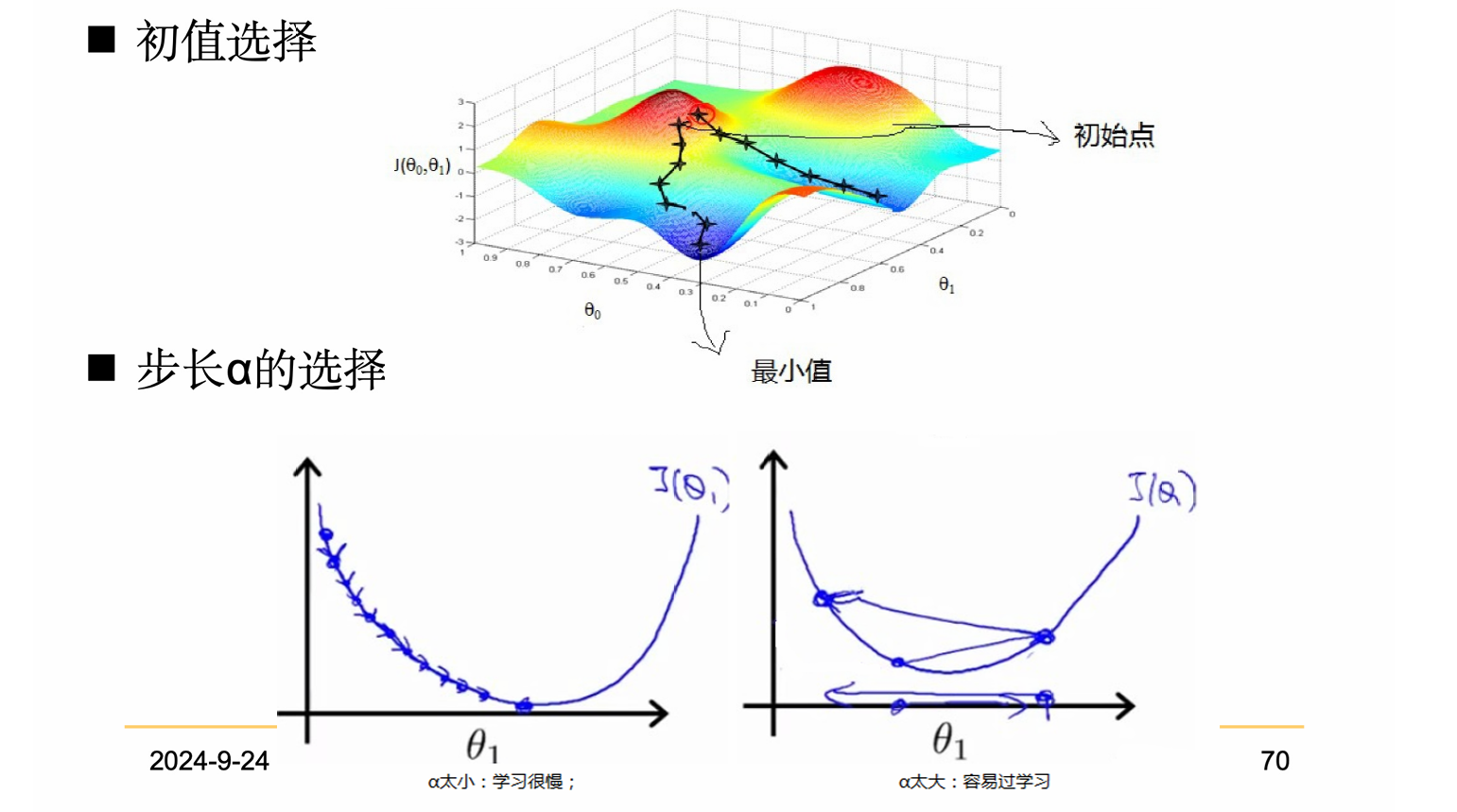
8. 常用的梯度下降法
8.1 批量梯度下降算法(BGD,Batch GD)
-
梯度下降算法又通常称为批量梯度下降算法。批量梯度下降每次学习都使用整个训练集,因此这些计算是冗余的,因为每次都使用完全相同的样本集。但其优点在于每次更新都会朝着正确的方向进行,最后能够保证收敛于极值点(凸函数收敛于全局极值点,非凸函数可能会收敛于局部极值点),但是其缺点在于每次学习时间过长,如果训练集很大以至于需要消耗大量的内存,并且全量梯度下降不能进行在线模型参数更新。它的具体思路是在更新每一参数时都使用所有的样本来进行更新。
-
梯度下降不一定能够找到全局最优解,有可能是一个局部最优解。
-
如果损失函数是凸函数(高数意义上的凹函数,定义相反),梯度下降法得到的解就一定是全局最优解。
-
由于有局部最优解的风险,需要多次用不同初始值运行算法。

-
梯度下降
import random
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
def function(x,y):
z=(x-2)**2+2*(y-1)**2
return z
#求偏导
def Partial_derivative_fx(x1,x2):
return 2*(x1-2)
def Partial_derivative_fy(x1,x2):
return 4*(x2-1)
x1=-10
x2=3
#使用随机数
#x1=random.randint(-10,10)
#x2=random.randint(-10,10)
print(x1,x2)
u = [x1]#x1的数组
v = [x2]#x2的数组
w = [function(x1,x2)]
#梯度下降
k=0#统计次数
a=0.3#步长,0.3和0.4都可以,其他不行
#随机步长
#a=random.random()
print('步长',a)
e=10**(-20)#临界值
while abs(a*Partial_derivative_fx(x1,x2))>e or abs(a*Partial_derivative_fy(x1,x2))>e :
x1=x1-a*Partial_derivative_fx(x1,x2)
x2=x2-a*Partial_derivative_fy(x1,x2)
k=k+1
u.append(x1)
v.append(x2)
w.append(function(x1,x2))
print(x1,x2)
print(k,'次',function(x1,x2))
#print(u,v)
U = np.array(u)
V = np.array(v)
W = np.array(w)
#画图
fig = plt.figure()
#ax = fig.add_subplot(111, projection='3d')
ax = Axes3D(fig)
X = np.arange(-10, 10, 0.2)
Y = np.arange(-10, 10, 0.2)
X, Y = np.meshgrid(X, Y)
Z = (X-2)**2+2*(Y-1)**2
ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='rainbow')
plt.show()
#画线
ax.scatter(U,V,W,color = 'yellow')
ax.plot(U,V,W,color = 'black')
plt.show()

绘制“对比不同学习率收敛速度差异图”的代码
import matplotlib.pyplot as plt
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
import random
plt.ion()
fig = plt.figure()
ax = fig.gca(projection='3d')
# Make data.
X = np.arange(-4, 4, 0.05)
Y = np.arange(-2, 4, 0.05)
X, Y = np.meshgrid(X,Y)
#原式
Z=(X-2)*(X-2)+2*(Y-1)*(Y-1)
#原函数 分开定义
def Fun(x,y):
x=x-2
y=y-1
x=np.multiply(x,x)
y=np.multiply(y,y)
y=y*2
return x+y
#偏x导
def PxFun(x,y):
return 2*x-4
#偏y导
def PyFun(x,y):
return 4*y-4
#代码实现
def steep(x,y,e,ax):
flag = 1
k = 0
while(flag):
z1 = Fun(x,y)
x = x - a*PxFun(x,y)
y = y - a*PyFun(x,y)
z2 = Fun(x,y)
if(abs(z1-z2)<e):
flag=0
ax.scatter(x,y, Fun(x,y), color='k')
k=k+1
if(k>100):
break
plt.pause(0.01)
e = 10**(-20)
a = 0.03
surf = ax.plot_surface(X, Y, Z, cmap="rainbow")
ax.set_zlim(0,25)
fig.colorbar(surf, shrink=0.5, aspect=5)
for i in range(3):
x = random.randint(-1,4)
y=random.randint(-1,4)
steep(x,y,e,ax)
plt.show()
A=np.array([0.02,0.04,0.06])
for a in [0.02,0.04,0.06]:
x=1
y=3
flag = 1
k = 0
tag_z=[Fun(x,y)]
tag_k=[0]
while(flag):
z1 = Fun(x,y)
x = x - a*PxFun(x,y)
y = y - a*PyFun(x,y)
z2 = Fun(x,y)
tag_z.append(z2)
if(abs(z1-z2)<e):
flag=0
k=k+1
tag_k.append(k)
if(k>50):
break
plt.plot(tag_k,tag_z)
plt.title('Objective function,Iterations')
plt.xlabel('Iterations')
plt.ylabel('Objective function')
plt.legend(['a=0.02','a=0.04','a=0.06'])
plt.show()


8.2 随机梯度下降算法(SGD,Stochastic Gradient Descent)
为了克服批量梯度下降的缺点,有人提出了随机梯度下降(Stochastic Gradient Descent)算法,即每次更新系数只随机抽取一个样本参与计算,因此既可以减少迭代次数,节省计算时间,又可以防止内存溢出,降低了计算开销。
但是随机梯度下降也有一个缺点,每次更新可能并不会按照正确的方向进行,因此可以带来优化波动(扰动),即参数更新频率太快,有可能出现目标函数值在最优值附近的震荡现象,并且高频率的参数更新导致了高方差。
不过从另一个方面来看,随机梯度下降所带来的波动有个好处就是,对于类似盆地区域(即很多局部极小值点)那么这个波动的特点可能会使得优化的方向从当前的局部极小值点跳到另一个更好的局部极小值点,这样便可能对于非凸函数,最终收敛于一个较好的局部极值点,甚至全局极值点。
随机梯度下降虽然提高了计算效率,但是由于每次迭代只随机选择一个样本,因此随机性比较大,所以下降过程中非常曲折,如下图所示:

随机梯度下降法和批量梯度下降法是两个极端,一个采用所有数据来梯度下降,一个用一个样本来梯度下降,自然各自的优缺点都非常突出。对于训练速度来说,随机梯度下降法由于每次仅仅采用一个样本来迭代,训练速度很快,参数更新频率太快;
而批量梯度下降法在样本量很大的时候,训练速度很慢。对于准确度来说,随机梯度下降法用于仅仅用一个样本决定梯度方向,导致解很有可能不是最优。对于收敛速度来说,由于随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。
8.3 小批量梯度下降法(MBGD,Mini-batch Gradient Descent)
是批量梯度下降法和随机梯度下降法的折衷,即对于m个样本选取x个样子来迭代

9. 全局最小与局部极小
跳出局部极小
- 在现实任务中,常采用以下策略以接近全局最小(但也会造成跳出全局最小)
-
以多组不同参数值初始化多个神经网络,按标准方法训练后,取其中误差最小的解作为最终参数
-
使用“模拟退火”技术,模拟退火在每一步都以一定的概率接受比当前解更差的结果,从而有助于跳出局部极小
-
使用随机梯度下降,计算梯度时加入随机因素
上述用于跳出局部极小的技术大多是启发式,理论上缺乏保障
10. 梯度发发散 VS 梯度爆炸


- sigmoid函数易发生梯度消失







10.1 梯度爆炸解决方法
-
梯度剪切:主要是针对梯度爆炸提出的
- 其思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就强制限制在这个范围内,以防止梯度爆炸
-
权重正则化:比较常见的是L1和L2正则化
- 如L2正则化损失函数:Loss = \((y - W^{T}x)^{2} + \alpha||W||^{2}\)
$ \alpha是指正则项系数,因此,如果发生梯度爆炸,权值的范数就会变化非常大,通过正则化,可以部分限制梯度爆炸发生$
-
批规范化(Batch normalization)
- 反向传播式子中有w的存在,所以w的大小影响了梯度的消失和爆炸
- batchnorm就是通过对每一层的输出规范为均值和方差一致的方法,消除了w带来的放大缩小的影响,进而解决梯度消失和爆炸的问题
11. softmax求导







12. optimization
12.1 微分为0,停止更新原因有二
- 微分为0原因有二

12.2 如何判别是卡在local minima还是saddle point



Saddle Point VS Local Minima
【Python】梯度下降法可视化学习过程记录(matplotlib绘制三维图形、ipywidgets包的使用等)
友链
机器学习-梯度下降算法原理及公式推导

 浙公网安备 33010602011771号
浙公网安备 33010602011771号