


爬虫 post请求:
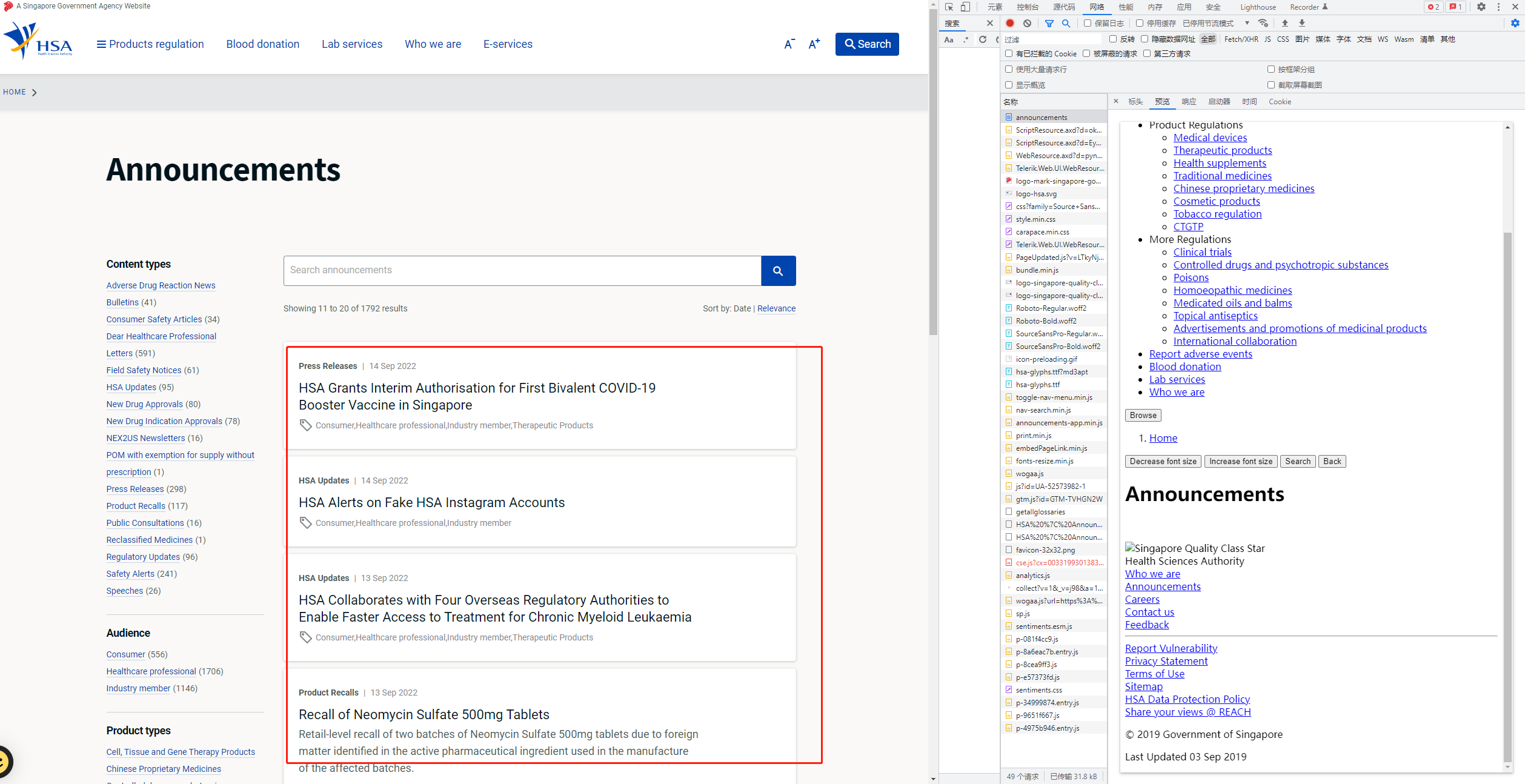
示例网站:如下图 ,要爬的资源不在html文件中,不可用xpath直接取
、
先把网络下面的信息清空,再点击页码 出现一下文件
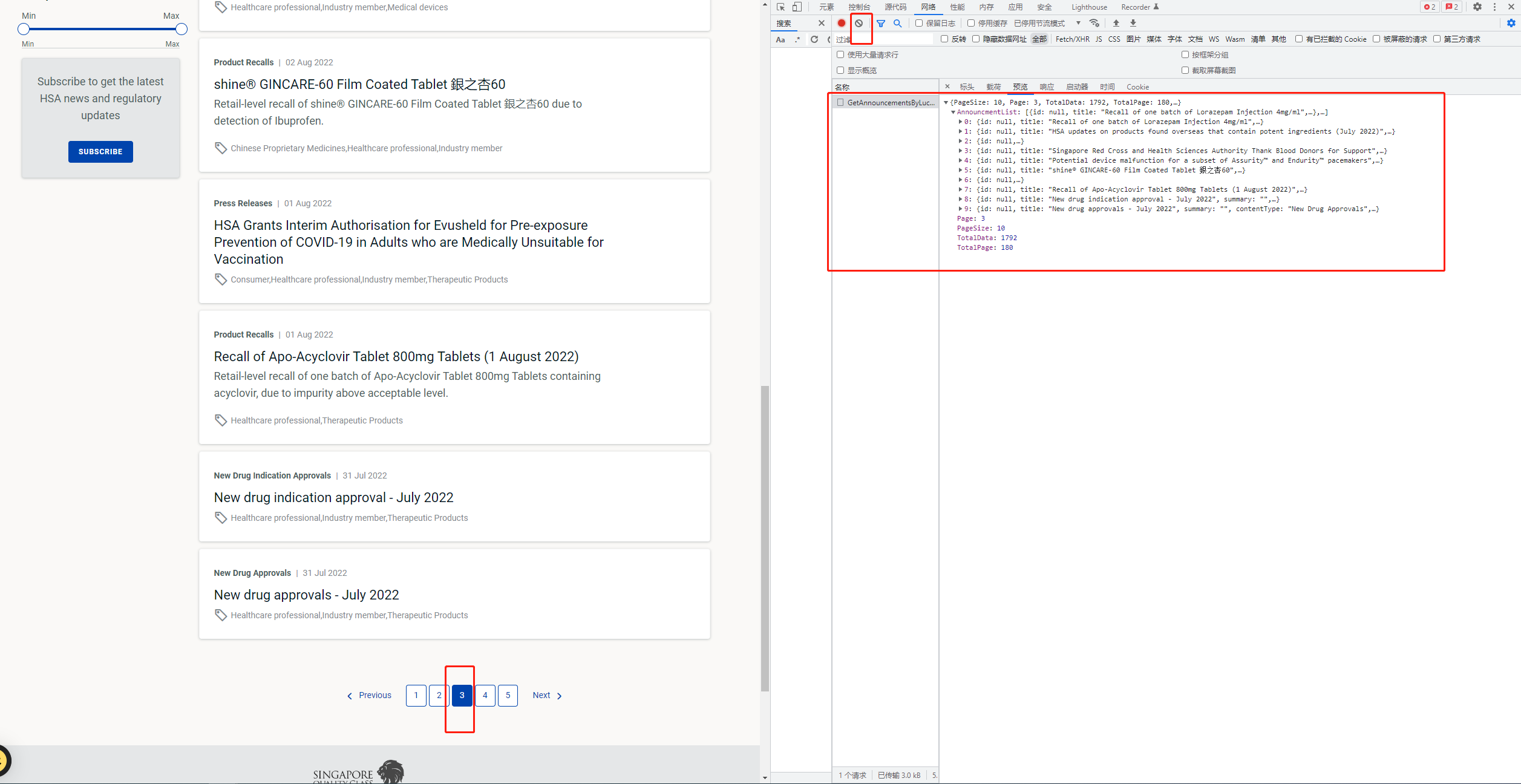
但是翻页过程中发现请求头的请求网址是不变的 ,请求方法是post
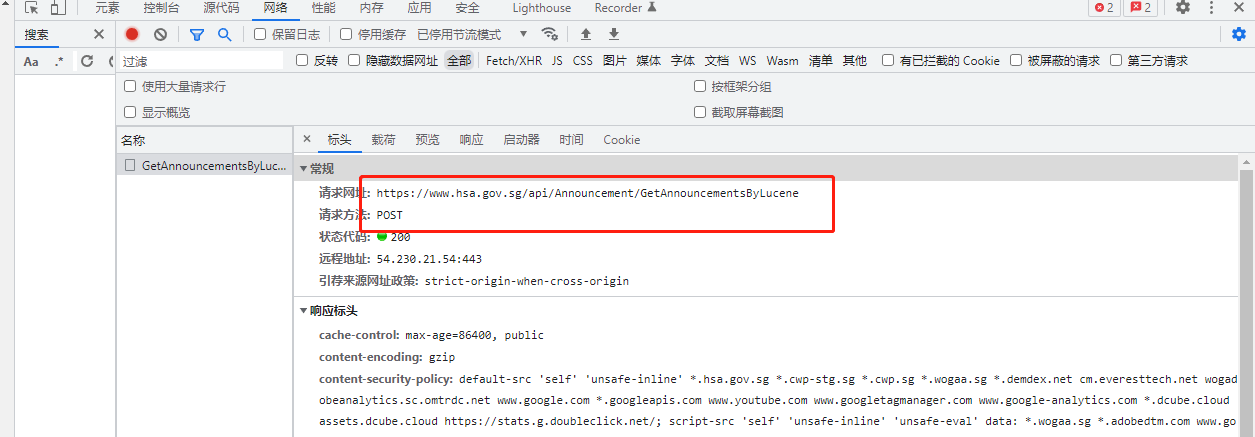
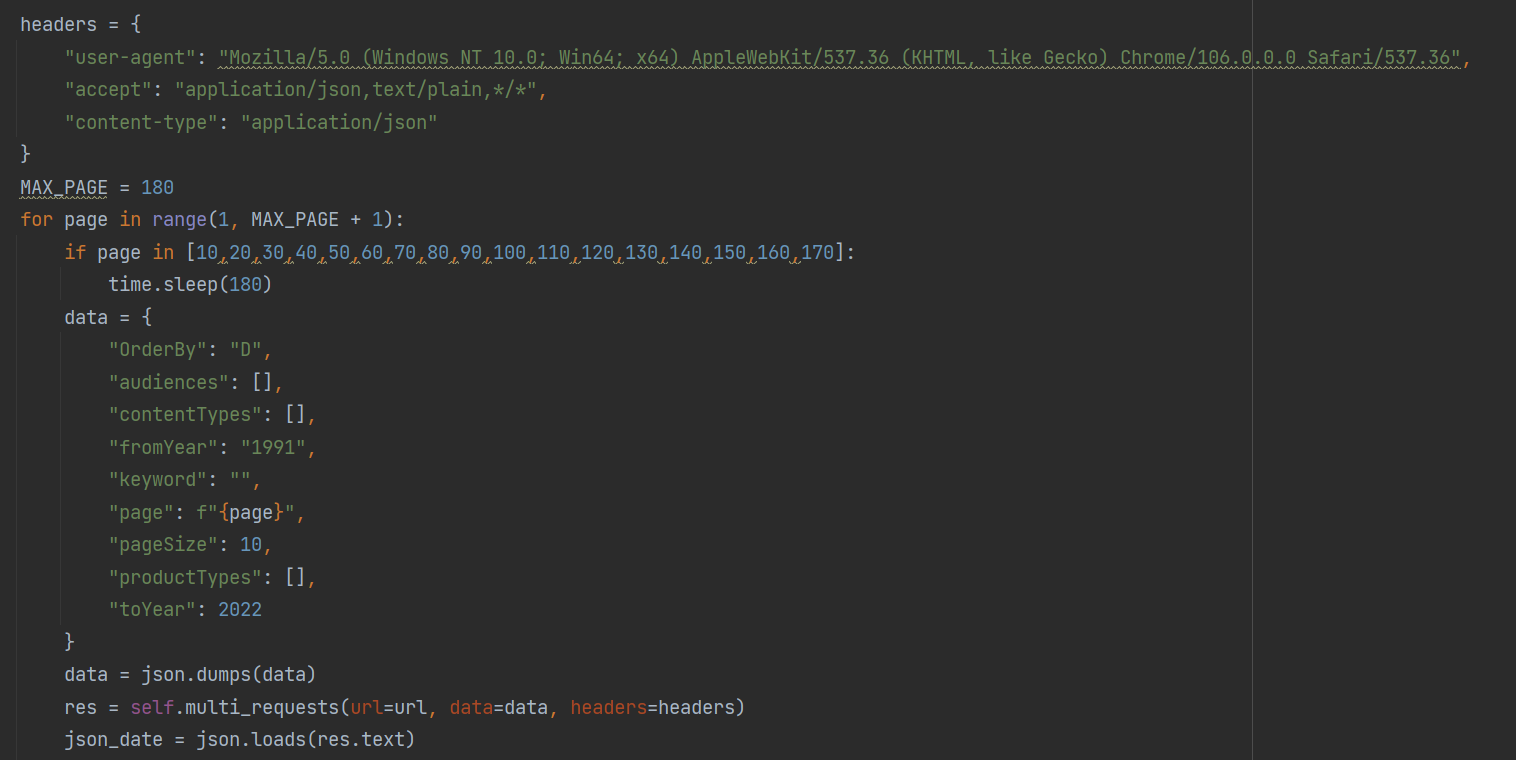
这时候就需要在post请求的data参数加上载荷,可以发现载荷里面有page这个参数,并且与我们翻页对应
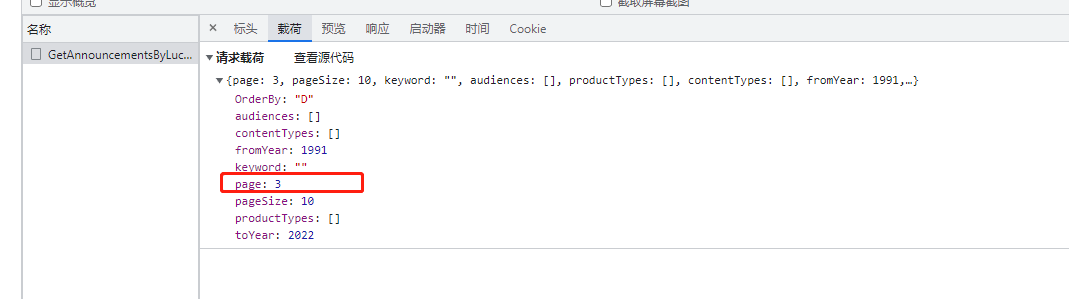
所以可通过如下脚本拿到响应信息,代码如下:
request请求添加headers的简单方法:
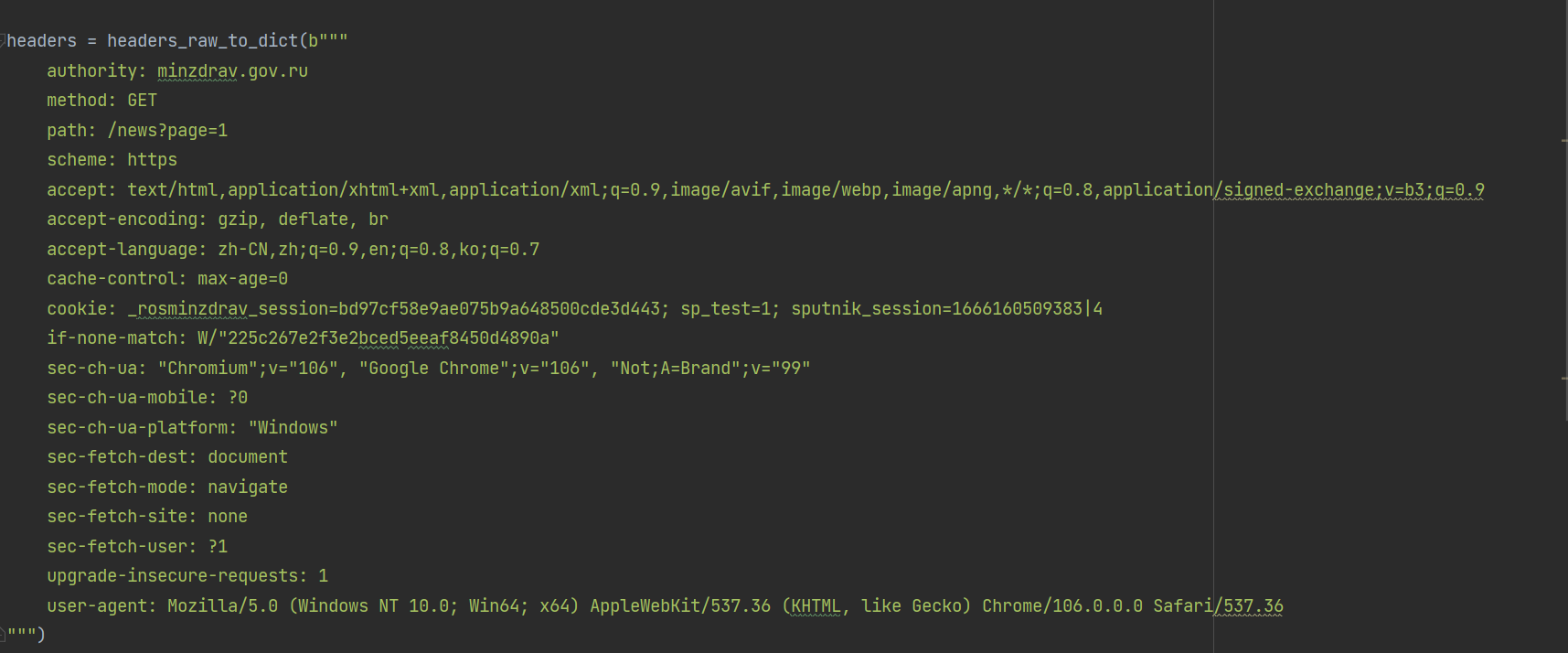
直接将浏览器的请求标头复制到引号之间
b"""
"""

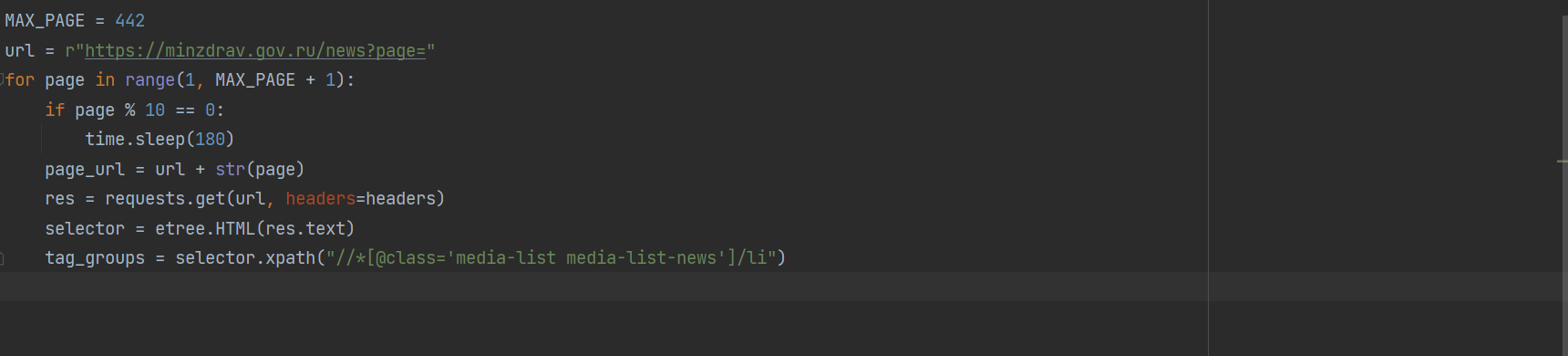
一般headers只需要如下几个 带太多反而会报错,如304等错误

有的时候,url访问明明200 了,返回内容却并非原网页内容,这个时候需要把网页上所有headers都添加全

 浙公网安备 33010602011771号
浙公网安备 33010602011771号