


[hadoop读书笔记] Hadoop下各技术应用场景
1、数据采集
对于数据采集主要分为三类,即结构化数据库采集,日志和文件采集,网页采集。
对于结构化数据库,采用Sqoop是合适的,可以实现结构化数据库中数据并行批量入库到hdfs存储。
对于网页采集,前端可以采用Nutch,全文检索采用lucense,而实际数据存储最好是入库到Hbase数据库。
对于日志文件的采集,现在最常用的仍然是flume或chukwa,但是我们要看到如果对于日志文件数据需要进行各种计算处理再入库的时候,往往flume并不容易处理,这也是为何可以采用Pig来做进一步复杂的data flow和process的原因。
数据采集类似于传统的ETL等工作,因此传统ETL工具中的数据清洗,转换,任务和调度等都是相当重要的内容。
这一方面是要基于已有的工具,进行各种接口的扩展以实现对数据的处理和清洗,一方面是加强数据采集过程的调度和任务监控。
使用Hadoop分析处理数据,需要装载大量从不同来源的数据到Hadoop集群。
从不同来源大容量的数据加载到Hadoop,然后这个过程处理它,这具有一定的挑战。
维护和确保数据的一致性,并确保资源的有效利用,选择正确的方法进行数据加载前有一些因素是要考虑的。
http://www.68dl.com/2016/0404/21335.html
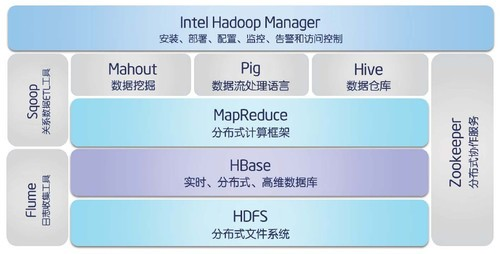
2、数据存储库
数据存储在这里先谈三种场景下的三种存储和应用方式,即Hbase,Hive,impala。三者都是基于底层的hdfs分布式文件系统。 hive重点是sql-batch查询,海量数据的统计类查询分析。而impala的重点是ad-hoc和交互式查询。hive和impala都可以看作是基于OLAP模式的。 Hbase库是支撑业务的CRUD操作,各种业务操作下的处理和查询。 如何对上面三种模式提供共享一致的数据存储和管理服务,HCatalog是基于Apache Hadoop之上的数据表和存储管理服务。提供统一的元数据管理,而不需要知道具体的存储细节当然是最好的,但是Hcatalog本身也还处于完善阶段,包括和Hive ,Pig的集成。 基于Mysql的MPP数据库Infobright是另外一个MPP(share nothing)数据分析库的选择,如果本身已有的业务系统就是基于Mysql数据库的,那么采用Infobright来做作为一个OLAP分析库也是一个选择。但是本身 Infobright的性能,Infobright社区版的稳定性,管控功能的缺失等仍然是需要考量的因素。 对于mapreduce和zookeeper本身就已经在hbase和hive中使用到了。如hive的hsql语言需要通过mapreduce解析和合并等。而对于impala要注意到本身是基于内存的MPP机制,没有用到mapreduce框架去处理,Dremel之所以能在大数据上实现交互性的响应速度,是因为使用了两方面的技术:一是对有嵌套结构的嵌套关系型数据采用了全新的列式存储格式,一是分布式可扩展统计算法,能够在几千台机器上并行计算查询结果。
3、实时流处理
这个hadoop框架本身没有包含,在此也做一个分析,前面已经摘录过文章对实时流处理做过介绍,而实际上真正实时流处理的场景并不多,任何一个技术的出现都是为了解决实际的业务问题。比如twitter推出storm可以解决实时热点查询和排序的问题,基于一个巨大的海量数据数据库,如果不是这种基于增量stream模式的分布式实时任务计算和推送,很难真正满足都业务对性能的要求。
同样对于s4和storm只是提供了一个开源的实时流处理框架,而真正的任务处理逻辑和代码仍然需要自己去实现,而开源框架只是提供了一个框架,提供了基本的集群控制,任务采集,任务分发,监控和failover的能力。真正在企业内部应用来看,很少有这种实时流场景,而与之对应的CEP复杂事件处理和EDA事件驱动架构,这个前面很多文章也都谈到过,这个基于消息中间件实现的事件发布订阅和推送,事件链的形成相对来说更加成熟。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号