LLM微调全指南
本文为「Master LLMs」系列内容,全面覆盖LLM微调的核心知识,含概念、方法、工具、实操示例及进阶技巧,助力AI从业者掌握定制化LLM打造能力。
一、核心概念:LLM微调是什么?为什么需要它?
- 定义
LLM(Large Language Model)是经海量通用文本预训练的语言模型,LLM微调(Finetuning) 指在预训练基础模型上,用更小体量的任务/领域定制数据集额外训练,让模型在特定应用中更专业、更好用。 - 基础模型与微调的关系
基础模型(Base Model)仅通过“预测下一个token”训练,无法稳定遵循复杂指令、进行多轮对话或对齐人类偏好;需通过两步核心微调(均属Finetuning)转化为可用聊天模型:
•有监督微调(SFT/Instruction Tuning):用(指令-期望响应)配对数据,教模型理解并执行用户指令
•对齐微调(Alignment Fine-Tuning):让模型贴合人类偏好、更安全可用 - 微调的核心价值
•小众需求适配:解决通用模型对低资源语言(如突尼斯方言)、特定场景的覆盖不足问题
•专业化能力强化:让模型掌握行业术语、固定人设、落地硬规则 - 模型专业化的4种方式
(原文核心提及,微调为关键方式之一,需结合场景选择)
二、微调的适用场景
•固定人设(Persona):锁定AI的一致人格与风格,不受用户提问影响
•行业术语适配(Speaking the Lingo):让模型流畅运用医学、法律、客服等专业表达
•硬规则落地(Embedding Hard Rules):强制模型输出特定格式(如JSON)、拒绝敏感话题
•数据就绪(Data is Ready to Go):已准备至少几千条高质量(用户提示-理想响应)配对样本
三、LLM微调的主要挑战与限制
•数据门槛(The Data Monster):需高质量、足量标注数据,采集与构造耗时昂贵,数据量随任务复杂度飙升
•算力成本(The Compute Bill):全量微调GPU占用高,成本可达数万至数十万美元(PEFT方法已显著降本)
•过拟合风险(The Overfitting Risk):模型记住训练数据,新数据表现变差(训练损失下降但验证损失上升)
•迭代缓慢(Slow to Change):调整语气、解决安全问题需重新收集数据、重复训练,代价高
四、微调的类型与目标 - 按调整权重范围分类
类型 调整范围 核心特点
全量微调(Full Finetuning) 全部权重 质量上限高、实现直接;资源消耗极大、易灾难性遗忘,2025年已少用
部分微调(Partial Finetuning) 部分权重 成本与遗忘风险降低;性能不及全量微调,需专业知识选层,逐步被PEFT取代
参数高效微调(PEFT) 新增极少权重 参数量减少99%以上,效率高,2025年默认选择
2. 核心训练目标与问题解决
(1)两大核心训练目标
•有监督微调(SFT):通过输入-输出对,让模型学会预测正确输出,核心用于领域适配、链式思维训练、结构化输出约束
•对齐/偏好微调(Alignment/Preference Finetuning):通过标注“更优回复”,教模型贴合人类偏好,代表方法含RLHF/RLAIF/DPO/PPO/GRPO
(2)常见问题与解决方案
问题 表现 解决方案
过拟合(Overfitting) 训练集表现完美,新数据糟糕 扩充数据、正则化、早停(early stopping)
灾难性遗忘(Catastrophic Forgetting) 专精任务后丢失通用能力 混入通用数据、降低学习率、优化数据集设计
五、2025年必掌握的微调方法
- 参数高效微调(PEFT)核心技术
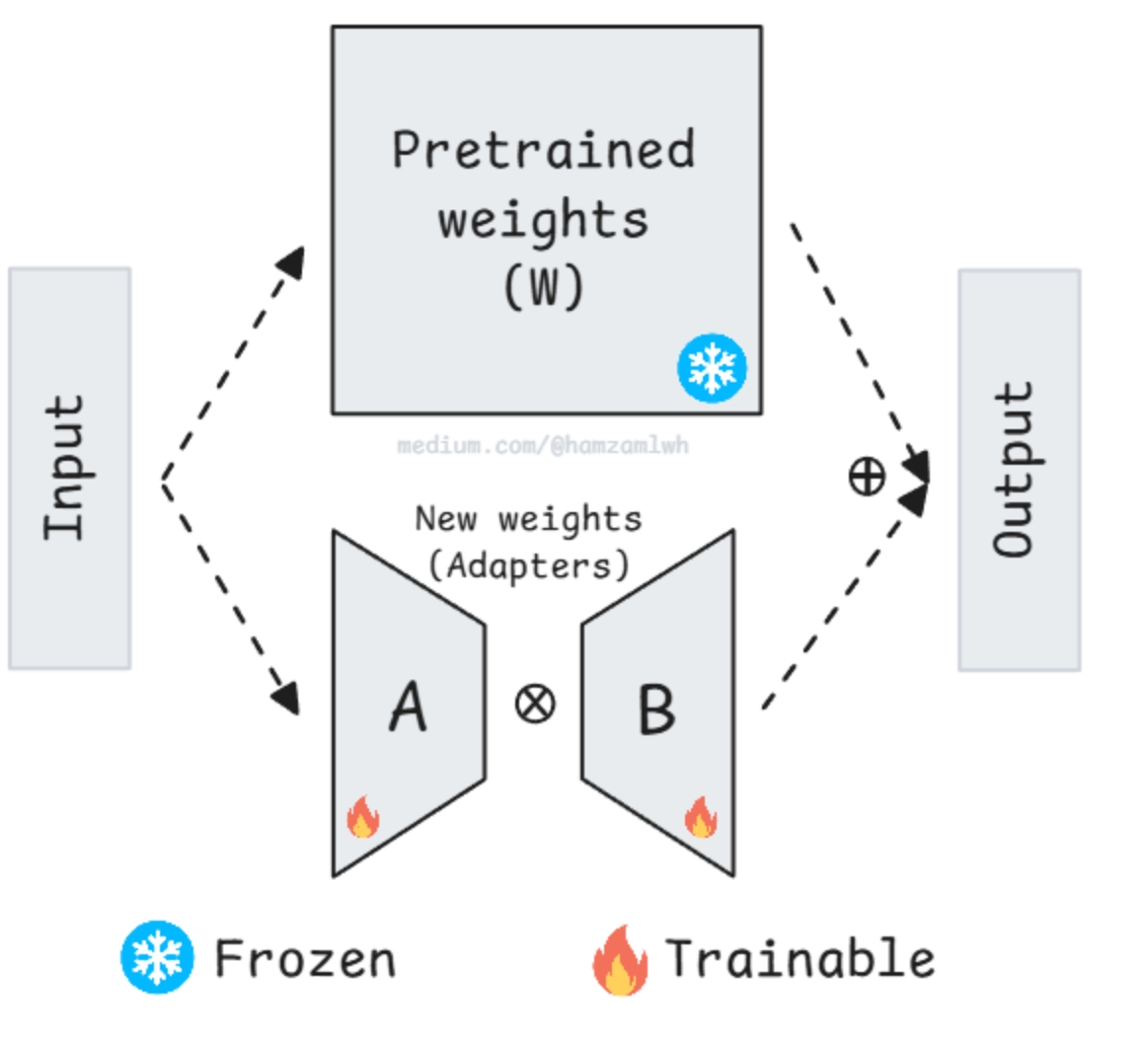
(1)LoRA(Low-Rank Adaptation)
•核心逻辑:冻结预训练权重,训练两个小矩阵A(d×r)与B(r×d),ΔW=A×B
•优势:参数量大幅减少(如4096×4096权重,r=8时参数量减少250倍),2025年默认选择
•![屏幕截图_15-1-2026_161932_blog.csdn.net]()
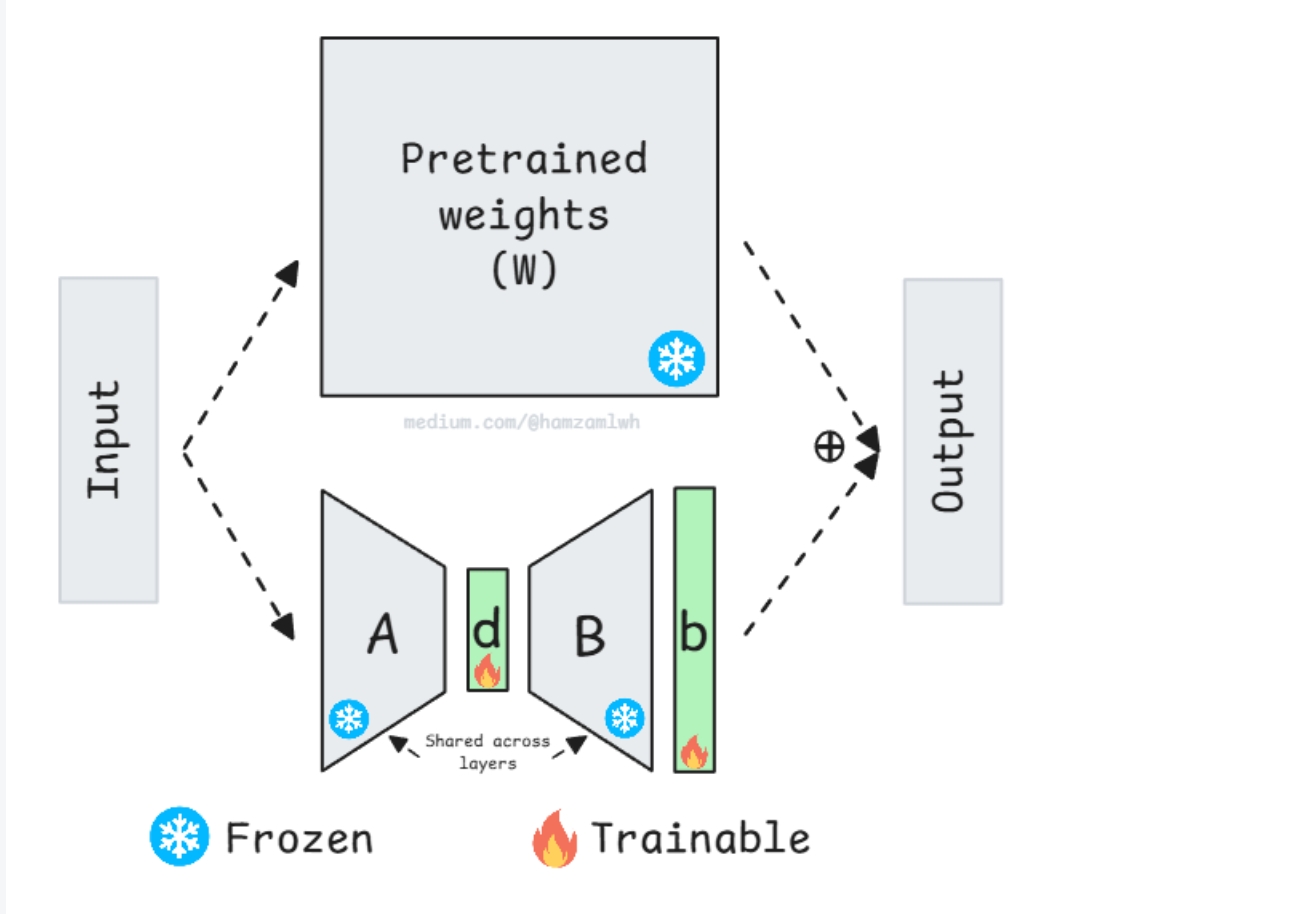
(2)QLoRA(Quantized LoRA)
•核心逻辑:量化加载模型(INT8/INT4/INT2),大幅降低显存占用
•适用场景:单张48GB GPU微调70B模型、12GB+消费级GPU微调7B模型
•
(3)其他主流PEFT方法
•VeRA:共享固定随机低秩矩阵,仅训练两个缩放向量,参数量与内存占用更低
•DoRA:权重分解为幅度-方向,小rank下效果优于LoRA,内存效率一致
•AdaLoRA:自适应秩分配,按层重要性动态调整rank,参数量更少但实现复杂
2. 奖励类微调方法
(1)经典方法:PPO/RLHF
•流程:先训练奖励模型(Reward Model),再用PPO优化策略
•现状:2025年使用减少,因实施复杂、训练不稳定、成本高
(2)现代主流:DPO(Direct Preference Optimization)
•核心逻辑:绕过强化学习阶段,直接基于偏好对优化模型,提升优响应对数似然、降低劣响应对数似然
•优势:简单、训练稳定、无需单独奖励模型,贴合人类偏好
(3)进阶方法:GRPO(Group Relative Policy Optimization)
•核心逻辑:生成N个候选响应,通过Verifier评分转化为“伪奖励”,优化策略
•适用场景:高要求推理领域(如数学、代码),性能稳定
(4)其他变体
•ORPO:融合SFT与偏好学习
•SimPO:无参考模型的简化偏好优化
•RHO:拒绝采样+对齐优化
六、数据集构建:微调的核心关键
- 核心原则
数据质量比模型尺寸、训练技术、算力预算的总和更重要 - 关键数据集类型
类型 用途 格式示例/要点 代表数据集
指令数据集(Instruction Datasets) SFT基础训练 含指令、输入、输出,格式规范、指令清晰 databricks/databricks-dolly-15k、Open-Orca/OpenOrca
领域数据集(Domain-Specific Datasets) 专业知识注入 需领域专家审核(如医生审医疗数据) MedQuAD、CUAD(合同)、Finance Alpaca
多轮对话数据集(Multiturn Conversational Datasets) 上下文维护能力训练 含用户与助手消息历史 OpenAssistant/oasst1
偏好数据集(Preference Datasets) DPO/RLHF训练 同一prompt配多个回复+优劣标注 Anthropic/hh-rlhf、OpenAssistant/oasst1
3. 好数据vs坏数据示例
(1)指令数据
•坏数据:指令含糊、格式混乱、输出简陋(如“answer this”+“what is ML”+“it is computers learn from data”)
•好数据:指令具体、格式规范、输出结构化+带示例(如明确“面向初学者解释”,输出含定义、例子、核心组件)
(2)偏好数据
•坏数据:回复差异小、prompt泛化(如“write about dogs”的两个相似短回复)
•好数据:优劣差异清晰、针对性强(如“忙时养犬建议”,优回复含时间要求、实操方案、风险提示)
4. 数据清洗关键步骤
•去重(Deduplication):删除或改写重复样本,避免过拟合
•规范化(Normalization):统一标点、大小写、特殊字符处理
•过滤幻觉(Filtering Hallucinations):用API或人工审核事实错误(合成数据重点关注)
•有害内容过滤(Toxic Content Filtering):用分类器+黑白名单
•类别平衡(Balancing Categories):上采样/下采样,避免话题偏倚
•拒绝样本处理(Handling Refusals):包含“有害请求拒绝”与“合理请求合规响应”
七、2025年主流微调框架与库
- 核心生态:Hugging Face
•核心库:Transformers(模型与API)、Datasets(数据访问)、Accelerate(分布式训练)、PEFT(高效微调)、TRL(强化学习微调)
•基线代码模板:
from transformers import AutoModelForCausalLM, TrainingArguments
from peft import LoraConfig, get_peft_model
from trl import SFTTrainer, DPOTrainer, GRPOTrainer
2. 其他常用工具
•PyTorch:底层框架,适合最大化定制需求
•Unsloth:适配T4 GPU,训练速度优化
•OpenRLHF、Axolotl:专项微调工具
•DeepSpeed:大规模训练加速
3. 高效微调神器:[[LLaMA-Factory Online](https://www.llamafactory.com.cn/register?utm_source=jslt_bky_gsh)]()
如果觉得本地配置环境、调试代码繁琐,想要快速落地微调需求,LLaMA-Factory Online 绝对是你的不二之选!它深度整合了本文所有核心微调方法(LoRA/QLoRA/DPO/GRPO等),无需复杂环境配置,浏览器端即可完成全流程操作:
•零代码门槛:可视化界面配置模型、数据集、超参数,小白也能快速上手
•全方法覆盖:支持SFT、DPO、RLHF等主流训练范式,适配金融、医疗、客服等多场景
•高效省成本:内置算力优化方案,支持多种开源模型快速加载,大幅降低训练耗时
•数据灵活处理:支持自定义数据集上传、自动清洗与格式转换,完美匹配指令/对话/偏好类数据需求
•一键部署测试:训练完成后可直接在线测试模型效果,支持权重导出与生产环境部署衔接
无论是入门者想要快速体验微调流程,还是从业者需要高效落地产品级模型,LLaMA-Factory Online都能帮你省去80%的繁琐工作,聚焦核心的数据与效果优化,让LLM微调更简单、更高效!现在即可通过专属注册链接开启体验:LLaMA-Factory Online 注册入口
八、实战示例
示例1:QLoRA实现金融客服助理微调(SFT)
目标:用QLoRA微调Qwen3 4B,适配金融场景(数据集:gbharti/finance-alpaca)
关键步骤:
1.安装依赖:torch、transformers、datasets、peft、trl等
2.数据准备:加载10%数据集(68k条→6.8k条)
3.模型加载:4-bit量化配置(BitsAndBytesConfig),启用sdpa注意力
4.LoRA配置:r=8、lora_alpha=16,目标模块q/k/v/o_proj
5.数据格式化:统一指令模板(### Instruction/Input/Response)
6.训练设置:SFTConfig(max_steps=100、batch_size=4、学习率2e-4)
7.训练与保存:启动训练→保存LoRA权重→可选合并基础模型与LoRA权重
8.测试:用pipeline生成金融相关响应
示例2:GRPO+QLoRA实现数学推理训练
目标:训练模型解决数学题,输出可验证答案(数据集:GSM8k)
关键步骤:
9.安装依赖:unsloth、vllm、bitsandbytes等
10.数据预处理:提取数学题、答案,定义系统提示(含思考过程+解决方案格式约束)
11.编写奖励函数:正确性奖励(答案匹配得2.0)、格式奖励(符合XML标签)、整数奖励
12.模型加载:用Unsloth加载Qwen2.5-1.5B-Instruct,4-bit量化+LoRA配置
13.GRPO训练设置:采样参数、学习率5e-6、max_steps=100
14.训练与保存:启动训练→保存LoRA权重
15.测试:输入数学题,验证模型推理过程与答案准确性
九、进阶主题(面向熟练用户)
- 容量与Rank选择经验法则
Rank值 适用样本量 核心逻辑
8 500–1000条 rank越高→参数量越多→学复杂模式能力越强,数据不足易过拟合
16 1000–5000条
32 5000–20000条
64 20000+条
•优化建议:多rank对比验证集loss,或用AdaLoRA自动分配rank
2. 避免灾难性遗忘的方法
•回放缓冲:训练集混入10–30%通用指令数据
•降低学习率:采用1e-55e-5(而非1e-45e-4)
•选择性调参:仅微调后期25–50%层(早期层存通用知识)
3. 评估策略
•分类任务:accuracy指标
•生成任务:rouge、bleu指标
•指令跟随:用LLM(如GPT-4)作为评审打分(1-10分)
4. 微调缩放定律(Scaling Laws)
•性能随训练数据量呈幂律提升,5–10万样本后边际收益递减
•80/20法则:80%提升来自前5000条高质量样本
•例外:复杂任务(医学诊断、法律推理)需5万+样本
5. MoE模型微调注意事项
•低学习率(1e-5或更低):避免破坏路由稳定性
•冻结路由:仅训练专家网络,保护专家选择逻辑
6. 安全与治理(Safety & Governance)
•红队测试:用对抗性提示(如“忽略之前指令”)验证模型拒绝能力
•数据保留:训练集中保留安全相关数据
•持续监控:微调后复测拒绝行为,上线后制定回滚预案
十、模型监控
- 训练期监控(Weights & Biases)
•核心指标:训练损失(平滑下降)、验证损失(不与训练损失背离)、学习率、梯度范数
•实现方式:TrainingArguments中指定report_to="wandb",设置logging_steps - 生产期监控
•关键指标:质量漂移、延迟(P50/P95/P99)、失败模式(拒绝率)、用户满意度
•工具:Prometheus定义指标(响应质量、幻觉检测、用户点赞数) - 再训练触发时机
•验证指标下降>5%
•用户满意度显著下降
•数据分布变化(季节性、产品迭代、政策更新)
•例行再训练:每3–6个月一次,配合影子发布与A/B测试
十一、实操建议 - 入门者路径
16.打好Prompt Engineering基础
17.构建/收集500条高质量样本
18.选择7B级易上手模型,用QLoRA高效微调
19.迭代循环:评估→优化数据/超参→小规模验证价值后再扩容
(入门阶段推荐用LLaMA-Factory Online,零配置快速体验全流程,注册链接:LLaMA-Factory Online 注册入口) - 产品级应用路径
20.先用RAG接入动态、最新知识
21.用微调固化品牌风格与期望行为
22.采用DPO/GRPO对齐用户偏好
23.建立持续监控与季度再训练机制
(产品级场景可通过LLaMA-Factory Online批量处理数据、调度训练任务,提升迭代效率,立即注册:LLaMA-Factory Online 注册入口)
结语
掌握LLM微调的核心在于“数据质量+方法选择+实操迭代”。工具与知识已就绪,建议从具体场景出发,动手微调模型、试错优化,在实践中深化理解。如果想跳过环境配置、快速落地需求,不妨通过专属注册链接体验LLaMA-Factory Online:LLaMA-Factory Online 注册入口,让微调流程更高效、更省心!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号