kafka04-消费组
kafka本身是分布式集群,多台服务器来共同处理一件事,效率高
采用分区技术存储,将海量数据切分成一块一块并行存储,同时生产者可以并行给不同的分区推送数据,消费者可以并行消费,提升效率
采用稀疏索引,可以快速定位数据,提升查找速率
以追加日志的方式顺序写入磁盘,速度快。顺序写快的原因:不需要像随机写那样需要先寻址定位,才能写入
使用了页缓存和零拷贝技术
页缓存:kafka重度依赖底层操作系统提供的pagecache功能。当上层有写操作时,操作系统知识将数据写入pagecache。当读操作发生时,先从pagecache中查找,如果找不到,再去磁盘中读取。实际上 pagecache是把尽可能多的空闲内存都当作了磁盘存储来使用。
零拷贝:kafka的数据加工处理操作交由生产者和消费者处理。kafka broker应用层不关心存储的数据,所以就不用走应用层,传输效率高。
*kafka消费者
kafka消费方式:
pull(拉)模式(默认):消费者主动从broker中拉取数据。
push(推)模式:broker主动推送给消费者
push优点:kafka知道自己什么时候有数据,有数据就推,没数据就不推。
push缺点:不知道consumer的消费能力。每个消费者的消费能力不同,可能A消费速度是10m/s, B消费速度是20m/s,C消费速度是30m/s,如果kafka以30m/s的速度推,A和B是无法承受的。
pull优点:每个consumer可能根据自己的消费能力去拉取数据
pull缺点:不知道什么kafka什么时候有数据,拉取返回的数据可能会为空
消费者总体工作流程:
消费者和消费者之间的独立的,可以对kafka不同的分区进行消费。
消费组 可以看成一个整体的消费者,同一分区只能由消费组中的一个消费者单独消费,否则会出现重复消费问题。
因为消费组内只能有一个消费者对一个分区进行消费,如果该消费者消费了部分数据后突然宕机了,那我们之后该如何接着之前的消费,把未消费的数据进行消费呢? offset会记录我们消费的位置 ,每个消费者的offset由消费者提交到系统主题进行保存
消费者组原理:
消费组是由多个groupid小童的消费者组成。
注意:在消费者api代码中必须配置消费组groupid。命令行启动消费者不填写groupid,是因为kafka会自动帮我们填写随机的groupid。
如果消费组内的消费者多于分区数,多于的消费者就处于空闲状态。

消费者组初始化流程:
coordinator 协调者,辅助实现消费者组的初始化和分区的分配
每个broker都有一个对应的一个coordinator
每个消费者组都有自己的groupid(我们自己定义),coordinator节点选择=groupid的hashcode值%50(_consumer_offsets的分区数据)得到的值便是分区值
例如:groupid的hashcode值=1,1%50=1,那么consumer_offsets主题的1号分区,在哪个broker上,则该broker节点的coordinator就是此次消费者组的leader。消费组下的所有消费者提交offset的时候,就往这个分区提交offset即可。
consumer_offsets主题:未来存储消费者的offset会放在这个主题里面,该主题对应有50个分区(和存储事务的主题分区数相同)
接下来所有的消费者都会发送joinGroup请求给coordinator_leader
coordinator_leader会选出一个consumer_leader
coordinator_leader会把要消费topic的情况发送给consumer_leader
consumer_leader会根据一种成熟的分区分配规则 制定一份计划方案,并发送给coordinator_leader
coordinator_leader再把消费方案下发给各个consumer
(面试经常问)每个consumer会定期和coordinator_leader保持心跳(默认3s),一旦超时(session.timeout.ms=45s),该consumer会被移除,并触发再平衡;或者消费者处理消息的时间过长(max.poll.interval.ms5分钟),也会触发再平衡
再平衡:消费组内如果一个消费者宕机,其他活跃的消费者需要分担宕机消费者剩余的任务

消费者组详细消费流程:
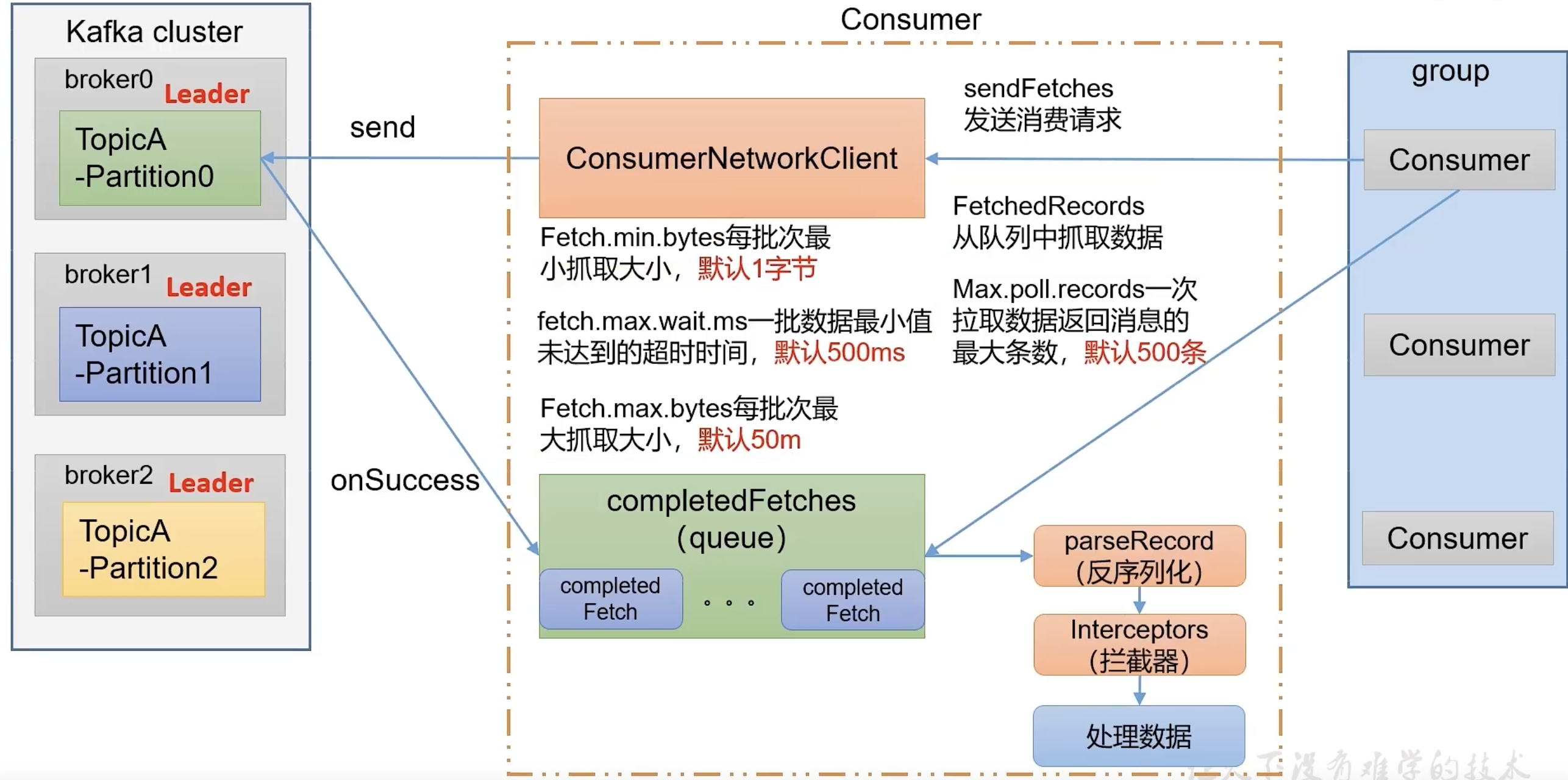
消费者组要想工作,首先需要创建一个ConsumerNetwordClient网络连接客户端,主要用来和kafka集群交互。
sendFetches,抓取数据的初始化,发送消费请求
配置参数:
Fetch.min.bytes 每批次最小抓取大小,默认1字节(也就是说,如果topic-partition有1字节数据,就会进行抓取)
Fetch.max.wait.ms 一批数据最小值未达到的超时时间,默认500ms(如果topic-partition内的数据没有达到minbyte抓取最小值,那么到达maxwaite,也会进行抓取)
Fetch.max.bytes 每批次最大抓取大小,默认50m
send方法发送请求
onSuccess 回调方法,拉取到的数据会放在completedFetches 的 queue消息队列中
消费者从 completedFetches 的 queue消息队列中 拉取数据
Max.poll.records 一次拉取数据返回信息的最大条数,默认500条
对数据进行parseRecord 反序列化 -> 拦截器 -> 处理数据
分区的分配以及再平衡:
四种主流的分区分配策略:
配置 Partition.assignment.strategy,可修改分区的分配策略。
默认策略:Range + CooperativeSticky。kafka可以使用多个分区分配策略。
Range
RoundRobin
Sticky
CooperativeSticky
Range策略:

RoundRobin策略:

Sticky分区分配策略:
粘性分区,可以解决为分配的结果带有“粘性”。即在执行一次新的分配之前,考虑上一次分配的结果,尽量减少分配的变动,可以节省大量的消耗。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号