
搭建solr的简单应用服务(二)
环境:Centos7 + jdk1.8 + solr-7.7.2 + tomcat-8.5.43
Centos7下载地址: https://www.jianshu.com/p/a63f47e096e8
jdk1.8下载地址: https://www.oracle.com/java/technologies/javase-jdk8-downloads.html
solr-7.7.2下载地址: http://archive.apache.org/dist/lucene/solr/
tomcat-8.5.43下载地址: http://archive.apache.org/dist/tomcat/tomcat-8/v8.5.43/bin/
第二部分: sorl服务配置中文分词器
说明: Solr版本中(Solr5之前), 在创建core的时候,Solr会自动创建好schema.xml , 但是在之后的版本中,新加入了动态更新schema功能,这个默认的schema.xml找不到了,在Solr5以后,这个schema文件已经不是默认生成好的了,它被取了一个名字managed-schema , 并且没有后缀。
第一种方法:
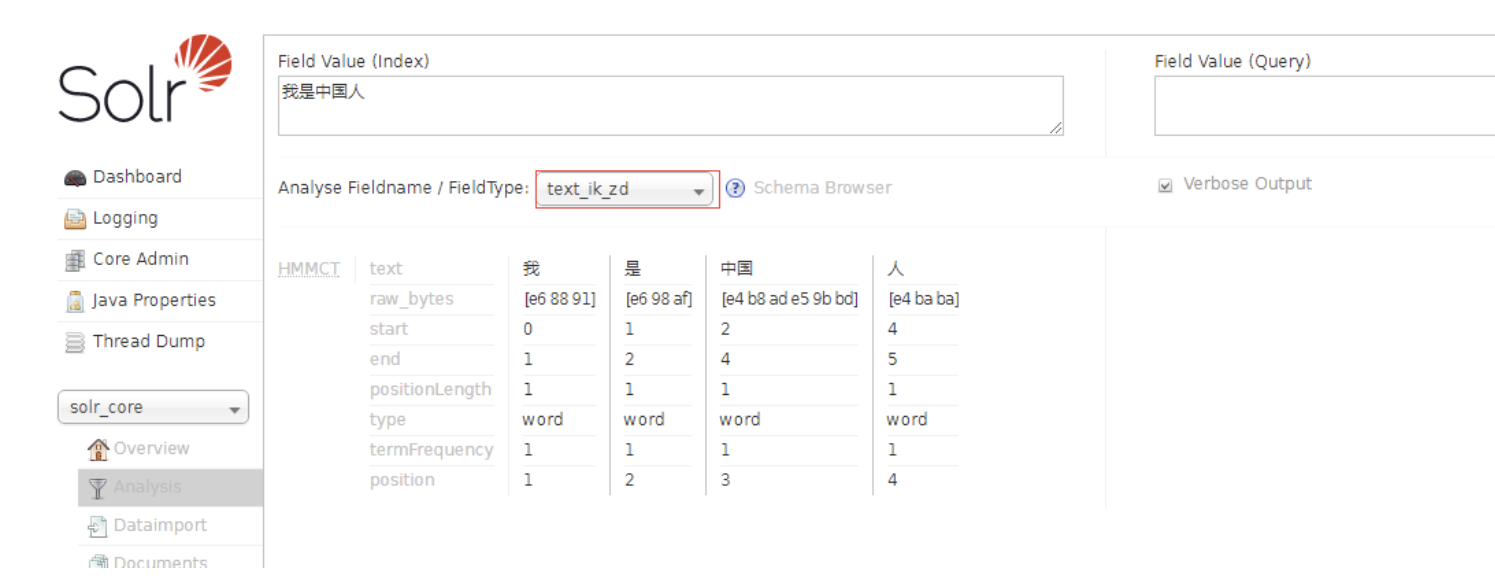
使用solr7版本以后自带的中文分词器
将solr-7.7.2\contrib\analysis-extras\lucene-libs下的lucene-analyzers-smartcn-7.2.0.jar放到tomcat-8.5.43\webapps\solr\WEB-INF\lib下。
在/usr/local/solrhome\new_core\conf找到managed-schema 添加已下代码
<fieldType name="text_ik_zd" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> </fieldType>
重新启动Tomcat , 就可以使用solr自带的分词器了
第二种方法:
配置IK中文分词器
IK各个版本分词器下载地址: https://github.com/medcl/elasticsearch-analysis-ik/releases
1. ext.dic为扩展字典
2. stopword.dic为停止词字典
3. IKAnalyzer.cfg.xml为配置文件
4. solr-analyzer-ik-5.1.0.jar ik-analyzer-solr5-5.x.jar为分词jar包。
1:将IK分词器 JAR 包拷贝到tomcat-8.5.43/webapps/solr/WEB-INF/lib下
2:将词典 配置文件拷贝到 tomcat-8.5.43/webapps/solr/WEB-INF/classes下
3: 更改在 /usr/local/solrhome/new_core/conf找到managed-schema配置文件,添加以下:
<fieldType name="text_ik" class="solr.TextField"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="true"/> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="true"/> </analyzer> </fieldType>
重新启动Tomcat , 就可以使用ik的分词器了
参考文章:
https://blog.csdn.net/m0_37044606/article/details/79155144

 浙公网安备 33010602011771号
浙公网安备 33010602011771号