深度学习模型的构建
构建深度学习模型的基本步骤

需要举例的地方以波士顿房价预测为案例
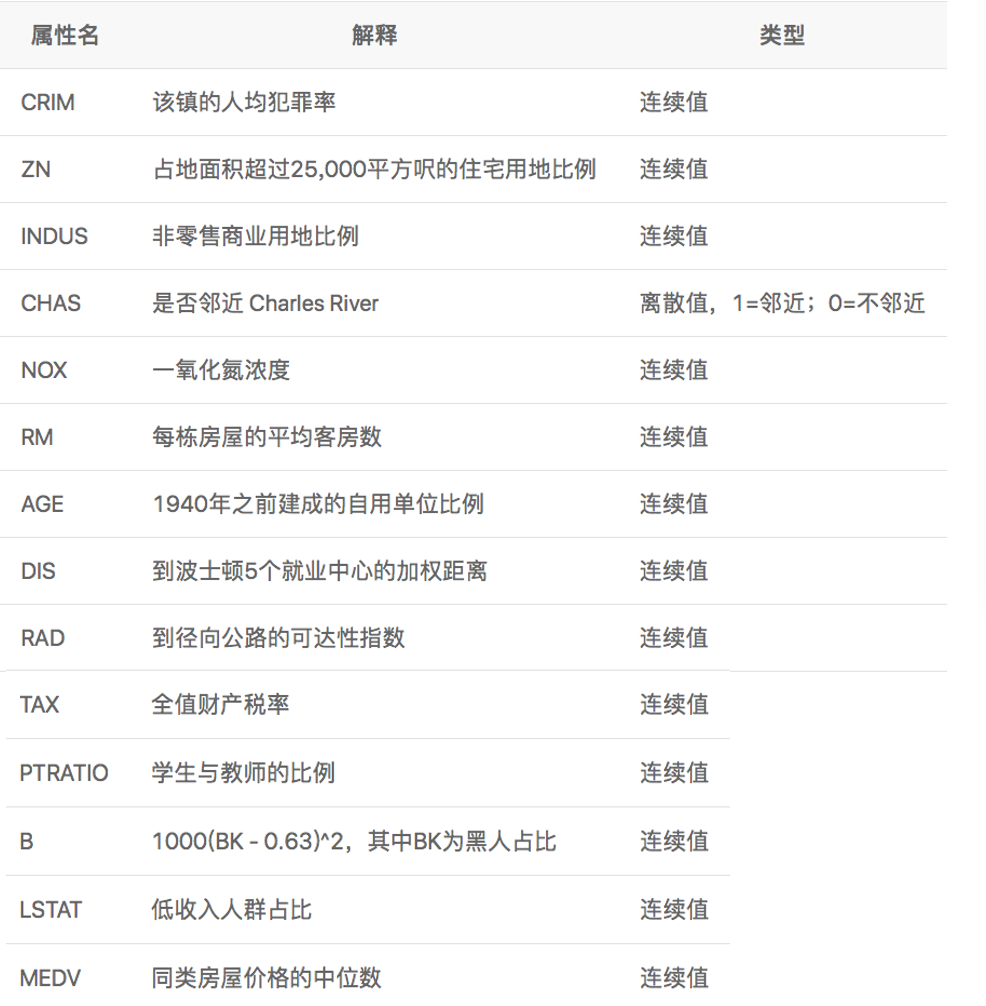
波士顿房价预测是一个经典的机器学习任务,类似于程序员世界的“Hello World”。和大家对房价的普遍认知相同,波士顿地区的房价是由诸多因素影响的。该数据集统计了13种可能影响房价的因素和该类型房屋的均价,期望构建一个基于13个因素进行房价预测的模型。
一、数据处理
数据处理包含五个部分:数据导入、数据形状变换、数据集划分、数据归一化处理和封装load data函数。数据预处理后,才能被模型调用。
1、数据形状变换
由于读入的原始数据是1维的,所有数据都连在一起。因此需要我们将数据的形状进行变换,形成一个2维的矩阵。
#每行为一个数据样本,每个数据样本包含13个X(影响房价的特征)和一个Y(该类型房屋的均价)。
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE','DIS',
'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
data = data.reshape([data.shape[0] // feature_num, feature_num])
'''
reshape(a,b): 变成a行b列矩阵
shape的作用是读取矩阵长度,shape[0]为读取矩阵第一维(行)的长度,
'''
2、数据集划分
将数据集划分成训练集和测试集,其中训练集用于确定模型的参数,测试集用于评判模型的效果。
#在本案例中,我们将80%的数据用作训练集,20%用作测试集。
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
3、数据归一化处理
对每个特征进行归一化处理,使得每个特征的取值缩放到0~1之间。
这样做有两个好处:一是模型训练更高效;二是特征前的权重大小可以代表该变量对预测结果的贡献度(因为每个特征值本身的范围相同)。常用的归一化方法有两种:
(1) min-max标准化(Min-Max Normalization)
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间。转换函数如下:
其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
(2) Z-score标准化方法
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数为:
其中\(\mu\)为均值,\(\sigma\)为标准差。
二、模型设计
对于预测问题,可以根据预测输出的类型是连续的实数值,还是离散的标签,区分为回归任务和分类任务。因为房价是一个连续值,所以房价预测显然是一个回归任务。
1、线性回归模型
假设房价和各影响因素之间能够用线性关系来描述:
模型的求解即是通过数据拟合出每个 wj 和 b。其中,wj 和 b 分别表示该线性模型的权重和偏置。一维情况下,wj 和 b 是直线的斜率和截距。
线性回归模型使用均方误差作为损失函数(Loss),用以衡量预测房价和真实房价的差异,公式如下:
2、线性回归模型的神经网络结构
神经网络的标准结构中每个神经元由加权和与非线性变换构成,然后将多个神经元分层的摆放并连接形成神经网络。线性回归模型可以认为是神经网络模型的一种极简特例,是一个只有加权和、没有非线性变换的神经元(无需形成网络)。
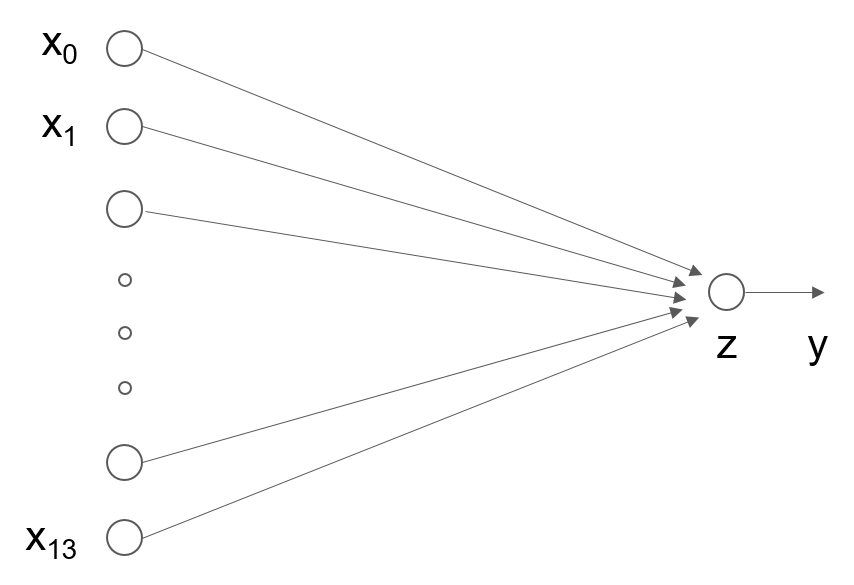
3、模型设计
模型设计是深度学习模型关键要素之一,也称为网络结构设计,相当于模型的假设空间,即实现模型“前向计算”(从输入到输出)的过程。
#如果将输入特征和输出预测值均以向量表示,输入特征x有13个分量,y有1个分量,那么参数权重的形状(shape)是13×1。
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,
# 此处设置固定的随机数种子
np.random.seed(0)
# np.random.randn()是从标准正态分布中返回一个或多个样本值,参数为返回的矩阵每个维度的长度
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):# 前向计算
z = np.dot(x, self.w) + self.b # z = wx+b
return z
三、训练配置
模型设计完成后,需要通过训练配置寻找模型的最优值,即通过损失函数来衡量模型的好坏。训练配置也是深度学习模型关键要素之一。
对于回归问题,最常采用的衡量方法是使用均方误差作为评价模型好坏的指标,具体定义如下:
上式中的Loss通常也被称作损失函数,它是衡量模型好坏的指标。在回归问题中均方误差是一种比较常见的形式,分类问题中通常会采用交叉熵作为损失函数。
因为计算损失时需要把每个样本的损失都考虑到,所以我们需要对单个样本的损失函数进行求和,并除以样本总数N。
四、训练过程
训练过程是深度学习模型的关键要素之一,其目标是让定义的损失函数Loss尽可能的小,也就是说找到一个参数解w和b使得损失函数取得极小值。
1、梯度下降法
在现实中存在大量的函数正向求解容易,反向求解较难,被称为单向函数,这样也就无法逆向求解出导数为0时的参数值。那么,求解Loss函数最小值可以“从当前的参数取值,一步步的按照下坡的方向下降,直到走到最低点”实现。这种方法就叫做梯度下降法。
实现梯度下降法的方案如下:
- 步骤1:随机的选一组初始值,例如:[w5,w9]=[−100.0,−100.0]
- 步骤2:选取下一个点[w5′,w9′],使得 L(w5′,w9′) < L(w5,w9)
- 步骤3:重复步骤2,直到损失函数几乎不再下降。
如何选择 [w5′,w9′] 是至关重要的,第一要保证 L 是下降的,第二要使得下降的趋势尽可能的快。微积分的基础知识告诉我们,沿着梯度的反方向,是函数值下降最快的方向。
2、计算梯度
对于上面的损失函数计算方法,我们将函数稍加改写,引入因子1/2(因为求梯度时要进行偏导,可以消去1/2,简化计算),定义损失函数如下:
其中 zi 是网络对第i个样本的预测值:
梯度的定义为:
则 L 对 w 和 b 的偏导数为:
下面我们考虑只有一个样本的情况下,计算梯度:
可以计算出:
则 L 对 w 和 b 的偏导数为:
# 按上面的公式,当只有一个样本时,可以计算某个wj,比如w0的梯度。
gradient_w0 = (z1 - y1) * x1[0]
# w1
gradient_w1 = (z1 - y1) * x1[1]
# w2
gradient_w2 = (z1 - y1) * x1[2]
...
#所以我们可以通过for循环来实现对w0到w12所有权重梯度的计算,或者,我们可以使用numpy
基于Numpy广播机制(对向量和矩阵计算如同对1个单一变量计算一样),可以更快速的实现梯度计算。
#计算梯度的代码中直接用(z1 - y1) * x1,得到的是一个13维的向量,每个分量分别代表该维度的梯度。
gradient_w = (z1 - y1) * x1
#同样,我们可以通过for循环的形式把每个样本(xi, yi)对梯度的贡献计算出来,或者我们依然可以使用numpy
# 注意这里是一次取出3个样本的数据,不是取出第3个样本
x3samples = x[0:3]
y3samples = y[0:3]
z3samples = np.dot(x3samples, w) + b # np.dot()为矩阵乘法
gradient_w = (z3samples - y3samples) * x3samples #前三个样本对梯度的贡献
# 所以我们可以直接一次计算所有样本对梯度的贡献度
z = np.dot(x, w) + b
gradient_w = (z - y) * x #前三个样本对梯度的贡献
对于有N个样本的情形,我们可以直接使用如下方式计算出所有样本对梯度的贡献,这就是使用Numpy库广播功能带来的便捷。 优点是:
- 一方面可以扩展参数的维度,代替for循环来计算1个样本对从w0 到w12 的所有参数的梯度。
- 另一方面可以扩展样本的维度,代替for循环来计算样本0到样本403对参数的梯度。
根据梯度的计算公式,总梯度是对每个样本对梯度贡献的平均值。
我们也可以使用Numpy的均值函数来完成此过程:
# axis = 0 表示把每一行做相加然后再除以总的行数
gradient_w = np.mean(gradient_w, axis=0) # 得到一个1维13列的变量
我们使用numpy的矩阵操作方便的完成了gradient的计算,但引入了一个问题,gradient_w的形状是(13,),而w的维度是(13, 1)。导致该问题的原因是使用np.mean函数的时候消除了第0维。为了加减乘除等计算方便,gradient_w和w必须保持一致的形状。因此我们将gradient_w的维度也设置为(13, 1)
gradient_w = gradient_w[:, np.newaxis]
则计算梯度的完整代码为:
z = np.dot(x, w) + b
gradient_w = (z - y) * x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
对于b,我们也用同样的方式计算梯度
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
# 此处b是一个数值,所以可以直接用np.mean得到一个标量
gradient_b
3、确定损失函数更小的点
如何更新参数来找到 Loss 更小的点呢?很容易想到,沿着梯度反方向走一小步,下一个点的损失函数就会减少。
# eta:控制每次参数值沿着梯度反方向变动的大小,即每次移动的步长,又称为学习率。
eta = 0.1
# 更新参数w5和w9
w = w - eta * gradient_w # 沿梯度反方向走一步
从数据处理到现在为止对于波士顿房价预测问题的示例代码如下:
import numpy as np
import json
import os
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
def load_data():# 数据处理
# 从文件导入数据
datafile = 'F:\ZTR\Study\Code\Python\.vscode\Boston\data\housing.data'
data = np.fromfile(datafile, sep=' ')
# 读入之后的数据被转化成1维array
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
# 将原始数据进行Reshape,变成[N, 14]这样的形状
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 将原数据集拆分成训练集和测试集
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
#计算最大、最小、平均值
maximums = training_data.max(axis=0)
minimums = training_data.min(axis=0)
avgs = training_data.sum(axis=0) / training_data.shape[0]
# 对数据进行归一化处理
for i in range(feature_num):
#print(maximums[i], minimums[i], avgs[i])
data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])
# 训练集和测试集的划分比例
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):# 向前计算
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):# 损失函数
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def gradient(self, x, y):# 梯度计算
z = self.forward(x)
gradient_w = (z-y)*x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
return gradient_w, gradient_b
def update(self, gradient_w, gradient_b, eta = 0.01):# 更新参数
self.w = self.w - eta * gradient_w
self.b = self.b - eta * gradient_b
def train(self, x, y, iterations=100, eta=0.01):# 训练过程
losses = []
for i in range(iterations):
z = self.forward(x)
L = self.loss(z, y)
gradient_w, gradient_b = self.gradient(x, y)
self.update(gradient_w, gradient_b, eta)
losses.append(L)
if (i+1) % 10 == 0:
print('iter {}, loss {}'.format(i, L))
return losses
# 获取数据
train_data, test_data = load_data()
x = train_data[:, :-1]
y = train_data[:, -1:]
# 创建网络
net = Network(13)
num_iterations=1000
# 启动训练
losses = net.train(x,y, iterations=num_iterations, eta=0.01)
# 画出损失函数的变化趋势
plot_x = np.arange(num_iterations)
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
4、随机梯度下降法
在上述方法中,每次损失函数和梯度计算都是基于数据集中的全量数据。对于样本数比较少的任务来说比较适用。但在实际问题中,数据集往往非常大,如果每次都使用全量数据进行计算,效率非常低。由于参数每次只沿着梯度反方向更新一点点,因此方向并不需要那么精确。一个合理的解决方案是每次从总的数据集中随机抽取出小部分数据来代表整体,基于这部分数据计算梯度和损失来更新参数,这种方法被称作随机梯度下降法(Stochastic Gradient Descent,SGD),核心概念如下:
- min-batch:每次迭代时抽取出来的一批数据被称为一个min-batch。
- batch_size:一个mini-batch所包含的样本数目称为batch_size。
- epoch:当程序迭代的时候,按mini-batch逐渐抽取出样本,当把整个数据集都遍历到了的时候,则完成了一轮的训练,也叫一个epoch。启动训练时,可以将训练的轮数num_epochs和batch_size作为参数传入。
- iterations:完成一次epoch所需的batch个数。
下面结合程序介绍具体的实现过程,涉及到数据处理和训练过程两部分代码的修改。
(1) 数据处理部分代码修改
数据处理需要实现拆分数据批次和样本乱序(为了实现随机抽样的效果)两个功能。
# 获取数据
train_data, test_data = load_data()
# train_data中一共包含404条数据,如果batch_size=10,即取前0-9号样本作为第一个mini-batch,命名train_data1。
train_data1 = train_data[0:10]
# 使用train_data1的数据(0-9号样本)计算梯度并更新网络参数。
net = Network(13)
x = train_data1[:, :-1]
y = train_data1[:, -1:]
loss = net.train(x, y, iterations=1, eta=0.01)
# 按此方法不断的取出新的mini-batch,并逐渐更新网络参数。(10-19号样本、20-29号样本....)
接下来,将train_data分成大小为batch_size的多个mini_batch。
# 将train_data分成 404/10+1个 mini_batch,其中前40个mini_batch,每个均含有10个样本,最后一个mini_batch只含有4个样本。
batch_size = 10
n = len(train_data)
mini_batches = [train_data[k:k+batch_size] for k in range(0, n, batch_size)]
通过大量实验发现,模型对最后出现的数据印象更加深刻。训练数据导入后,越接近模型训练结束,最后几个批次数据对模型参数的影响越大。为了避免模型记忆影响训练效果,需要进行样本乱序操作。
'''
我们这里是按顺序取出mini_batch的,而SGD(随机梯度下降)里面是随机的抽取一部分样本代表总体。为了实现随机抽样的效果,我们先将train_data里面的样本顺序随机打乱,然后再抽取mini_batch。
'''
np.random.shuffle(train_data)
======================================
# 数据处理部分最终代码如下:
# 获取数据
train_data, test_data = load_data()
# 打乱样本顺序
np.random.shuffle(train_data)
# 将train_data分成多个mini_batch
batch_size = 10
n = len(train_data)
mini_batches = [train_data[k:k+batch_size] for k in range(0, n, batch_size)]
# 创建网络
net = Network(13)
# 依次使用每个mini_batch的数据
for mini_batch in mini_batches:
x = mini_batch[:, :-1]
y = mini_batch[:, -1:]
loss = net.train(x, y, iterations=1)
(2) 训练过程代码修改
将每个随机抽取的mini-batch数据输入到模型中用于参数训练。训练过程的核心是两层循环:
i. 第一层循环,代表样本集合要被训练遍历几次,称为“epoch”。
for epoch_id in range(num_epoches):
ii. 第二层循环,代表每次遍历时,样本集合被拆分成的多个批次,需要全部执行训练,称为“iter (iteration)”。 for iter_id,mini_batch in emumerate(mini_batches):
在两层循环的内部是经典的四步训练流程:前向计算->计算损失->计算梯度->更新参数
五、最终完整代码
import numpy as np
import json
import os
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
#================数据处理==================
def load_data():
# 从文件导入数据
datafile = 'F:\ZTR\Study\Code\Python\.vscode\Boston\data\housing.data'
data = np.fromfile(datafile, sep=' ')
# 读入之后的数据被转化成1维array,其中array的第0-13项是第一条数据,第14-27项是第二条数据,以此类推....
# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
# 将原始数据进行Reshape,变成[N, 14]这样的形状
data = data.reshape([data.shape[0] // feature_num, feature_num])#reshape(行,列),shape的作用是读取矩阵长度,shape[0]为读取矩阵第一维长度
# 将原数据集拆分成训练集和测试集
# 这里使用80%的数据做训练,20%的数据做测试
# 测试集和训练集必须是没有交集的
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
#数据归一化处理
'''
对每个特征进行归一化处理,使得每个特征的取值缩放到0~1之间。这样做有两个好处:
一是模型训练更高效;
二是特征前的权重大小可以代表该变量对预测结果的贡献度(因为每个特征值本身的范围相同)。
'''
# 计算train数据集的最大值,最小值,平均值
maximums = training_data.max(axis=0) #axis为矩阵维度,如axis=0就是取第一维,也就是行;axis=1是取第二维,也就是列
minimums = training_data.min(axis=0)
avgs = training_data.sum(axis=0) / training_data.shape[0]
# 对数据进行归一化处理
for i in range(feature_num):
#print(maximums[i], minimums[i], avgs[i])
data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])#计算方法存疑,data[:,i]指取每行的第i个元素
# 训练集和测试集的划分比例
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
#================模型设计==================
'''
模型设计是深度学习模型关键要素之一,也称为网络结构设计,相当于模型的假设空间,即实现模型“前向计算”(从输入到输出)的过程。
如果将输入特征和输出预测值均以向量表示,输入特征x有13个分量,y有1个分量,那么参数权重的形状(shape)是13×1。
'''
'''
将上述计算预测输出的过程以“类和对象”的方式来描述,类成员变量有参数w和b。
通过写一个forward函数(代表“前向计算”)完成从特征和参数到输出预测值的计算过程。
'''
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,
# 此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)# np.random.randn()是从标准正态分布中返回一个或多个样本值,参数为返回的矩阵每个维度的长度
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
# 训练配置
# 模型设计完成后,需要通过训练配置寻找模型的最优值,即通过损失函数来衡量模型的好坏。训练配置也是深度学习模型关键要素之一。
'''
对于回归问题,最常采用的衡量方法是使用均方误差作为评价模型好坏的指标,具体定义如下:
Loss=(y−z)^2
上式中的Loss通常也被称作损失函数,它是衡量模型好坏的指标。
在回归问题中均方误差是一种比较常见的形式,分类问题中通常会采用交叉熵作为损失函数,
'''
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
# 训练过程
'''
梯度下降法步骤如下:
步骤1:随机的选一组初始值,例如:[w5,w9]=[−100.0,−100.0][w_5, w_9] = [-100.0, -100.0]
步骤2:选取下一个点[w5′,w9′],使得L(w5′,w9′)<L(w5,w9)
步骤3:重复步骤2,直到损失函数几乎不再下降。
'''
def gradient(self, x, y):
z = self.forward(x)
gradient_w = (z-y)*x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
return gradient_w, gradient_b
def update(self, gradient_w, gradient_b, eta = 0.01):
self.w = self.w - eta * gradient_w
self.b = self.b - eta * gradient_b
def train(self, training_data, num_epoches, batch_size=10, eta=0.01):
n = len(training_data)
losses = []
for epoch_id in range(num_epoches):
# 在每轮迭代开始之前,将训练数据的顺序随机的打乱,
np.random.shuffle(training_data)
# 然后再按每次取batch_size条数据的方式取出
# 将训练数据进行拆分,每个mini_batch包含batch_size条的数据
mini_batches = [training_data[k:k+batch_size] for k in range(0, n, batch_size)]
for iter_id, mini_batch in enumerate(mini_batches):# enumerate()的作用是将一个可遍历的数据对象组合为一个索引序列,同时列出数据和数据下标
#print(self.w.shape)
#print(self.b)
x = mini_batch[:, :-1]
y = mini_batch[:, -1:]
a = self.forward(x)
loss = self.loss(a, y)
gradient_w, gradient_b = self.gradient(x, y)
self.update(gradient_w, gradient_b, eta)
losses.append(loss)
print('Epoch {:3d} / iter {:3d}, loss = {:.4f}'.
format(epoch_id, iter_id, loss))
return losses
# 获取数据
train_data, test_data = load_data()
# 打乱样本顺序
np.random.shuffle(train_data)
# 将train_data分成多个mini_batch
batch_size = 10
n = len(train_data)
mini_batches = [train_data[k:k+batch_size] for k in range(0, n, batch_size)]
# 创建网络
net = Network(13)
# 启动训练
losses = net.train(train_data, num_epoches=50, batch_size=100, eta=0.1)
# 画出损失函数的变化趋势
plot_x = np.arange(len(losses))
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
'''
使用神经网络建模房价预测有三个要点:
1、构建网络,初始化参数w和b,定义预测和损失函数的计算方法。
2、随机选择初始点,建立梯度的计算方法和参数更新方式。
3、从总的数据集中抽取部分数据作为一个mini_batch,计算梯度并更新参数,不断迭代直到损失函数几乎不再下降。
'''

 浙公网安备 33010602011771号
浙公网安备 33010602011771号