

【hadoop】集群namenode和datanode群起失败,解决方法
背景:
解决hadoop和hive的log4j-slf4j-impl-2.10.0.jar 包冲突的问题
用mv lib/log4j-slf4j-impl-2.10.0.jar lib/log4j-slf4j-impl-2.10.0.back
修改hive的包名,解决冲突。
决绝完冲突,初始化derby元数据库,
在hive的安装文件夹下执行bin/schematool -dbType derby -initSchema后
启动hive的时候,突然报错连接被拒绝。
检查进程突然发下datanode和namenode没有启动起来,
解决方法:
首先要检查报的错误是什么,在hadoop安装文件夹下的 logs
通常如果是 hadoop namenode -format 命令执行对此,
会导致clusterid冲突,无法启动,这是可以
删除集群上的hadoop安装文件夹下的 data 和logs文件
使用命令 rm -rf data/ logs/ 同时删除
重新格式化,启动集群;如果解决不了,把根目录下的/temp的hadoop的临时文件删除。
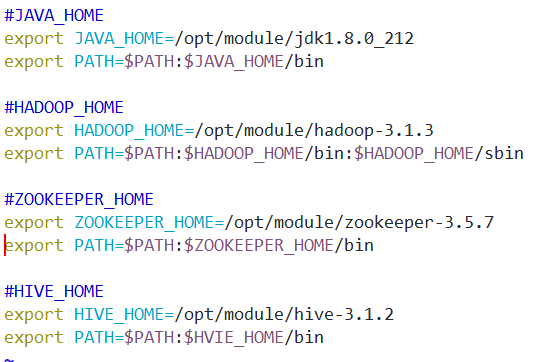
除了以上问题,还有可能在配置环境变量的时候格式错误,
以上提升全局变量的配置方式请参考~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号