FastAPI中间件、依赖注入、ORM
使用中间件为每个请求前后添加统一的处理逻辑,需求场景:
- 多个接口:都需要验证用户身份
- 多个接口:都需要记录日志、性能数据
日志记录、身份认证、跨域处理、响应头处理、性能监控
一、中间件
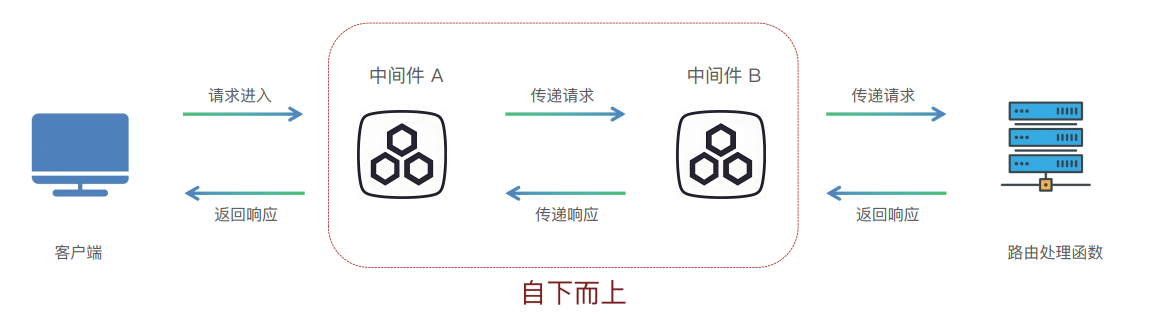
中间件(Midleware)是一个在每次请求进入 FastAPI 应用时都会被执行的函数。它在请求到达实际的路径操作(路由处理函数)之前运行,并且在响应返回给客户端之前再运行一次
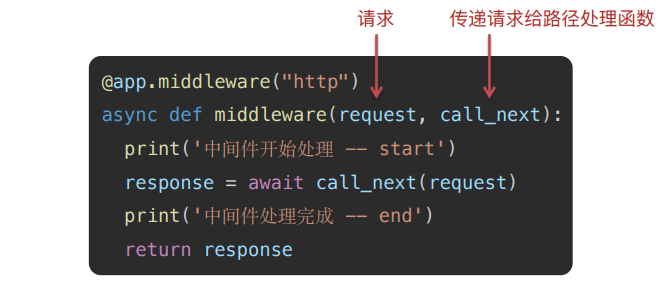
中间件定义:函数的顶部使用装饰器 @app.midleware("http")
多个中间件的执行顺序:自下而上
案例:
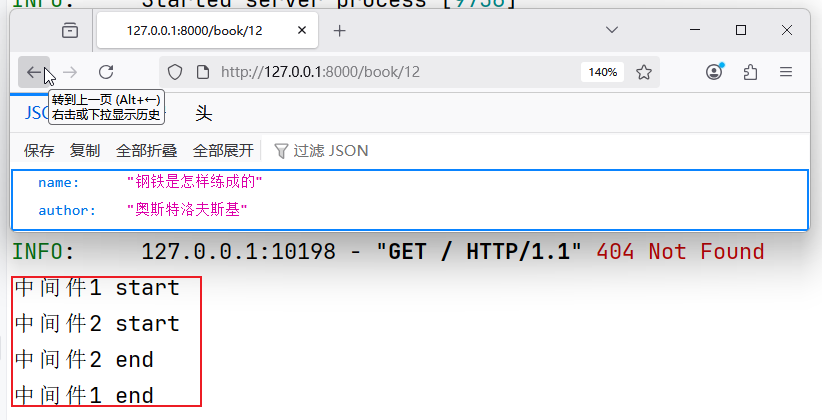
from fastapi import FastAPI app = FastAPI() @app.middleware("http") async def middleware2(request, call_next): """ :param request: :param call_next: :return: """ print("中间件2 start") response = await call_next(request) print("中间件2 end") return response @app.middleware("http") async def middleware1(request, call_next): """ :param request: :param call_next: :return: """ print("中间件1 start") response = await call_next(request) print("中间件1 end") return response @app.get("/book/{book_id}") async def root(): return {"name": "钢铁是怎样练成的", "author": "奥斯特洛夫斯基", "price": 19.9}
二、依赖注入
FastAPI中,依赖注入系统作用:抽取可复用的组件,实现代码复用、解耦且可轻松替换依赖项进行测试,使用依赖注入系统来共享通用逻辑,减少代码重复
依赖项:可重用的组件(函数/类),负责提供某种功能或数据。
注入:FastAPI 自动帮你调用依赖项,并将结果"注入"到路径操作函数中。
优点:
- 代码复用:一次编写,多处使用
- 解耦:业务逻辑与基础设施代码分离
- 易于测试:轻松地用模拟依赖替换真实依赖进行测试
依赖注入应用场景
- 处理请求参数:从请求中提取和验证参数(路径参数、查询参数、请求体)
- 共享数据库连接:管理数据库会话的创建、使用、关闭
- 共享业务逻辑:抽取封装多个路由公用的逻辑代码
- 安全和认证:验证用户身份、检查权限和角色要求等
依赖注入实现:
创建依赖项 → 导入 Depnds → 声明依赖项
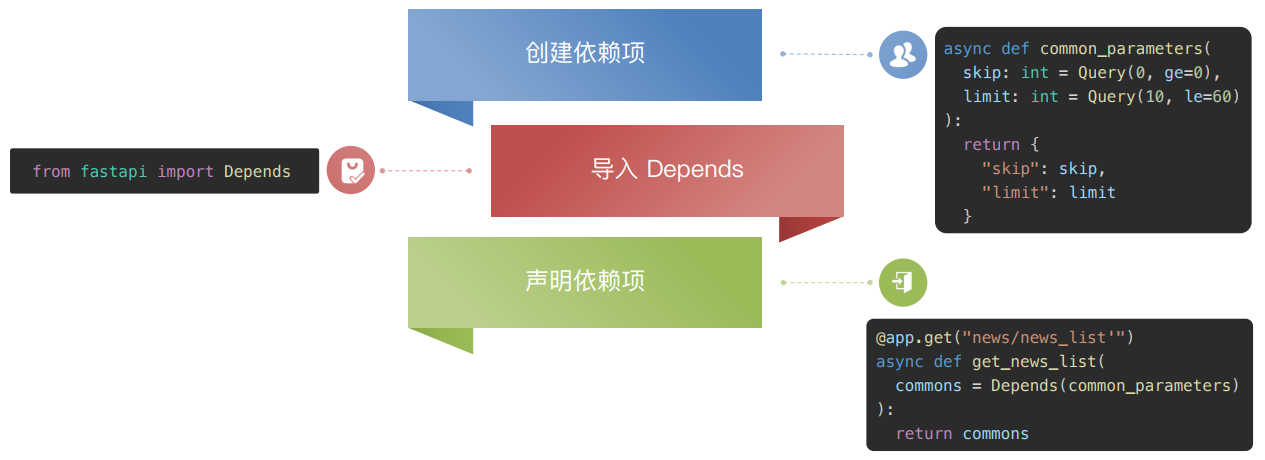
案例代码:
from fastapi import FastAPI, Query, Depends # 导入 Depends app = FastAPI() @app.get("/") async def root(): return {"message": "Hello World"} # 1.依赖项 async def common_parameters(skip: int = Query(0, ge=0), limit: int = Query(10, le=100)): return {"skip": skip, "limit": limit} # 3.声明依赖项:依赖注入 @app.get("/news/news_list") async def get_news_list(commons=Depends(common_parameters)): """ 获取新闻列表 :param commons: :return: """ # 获取参数 skip = commons["skip"] limit = commons["limit"] # 在这里可以使用 skip 和 limit 进行数据库查询等操作 return {"skip": skip, "limit": limit, "data": ["新闻1", "新闻2", "新闻3", "新闻4"]} @app.get("/user/user_list") async def get_user_list(commons=Depends(common_parameters)): """ 获取用户列表 :param commons: :return: """ # 获取参数 skip = commons["skip"] limit = commons["limit"] # 在这里可以使用 skip 和 limit 进行数据库查询等操作 return {"skip": skip, "limit": limit, "data": ["用户1", "用户2", "用户3", "用户4"]}
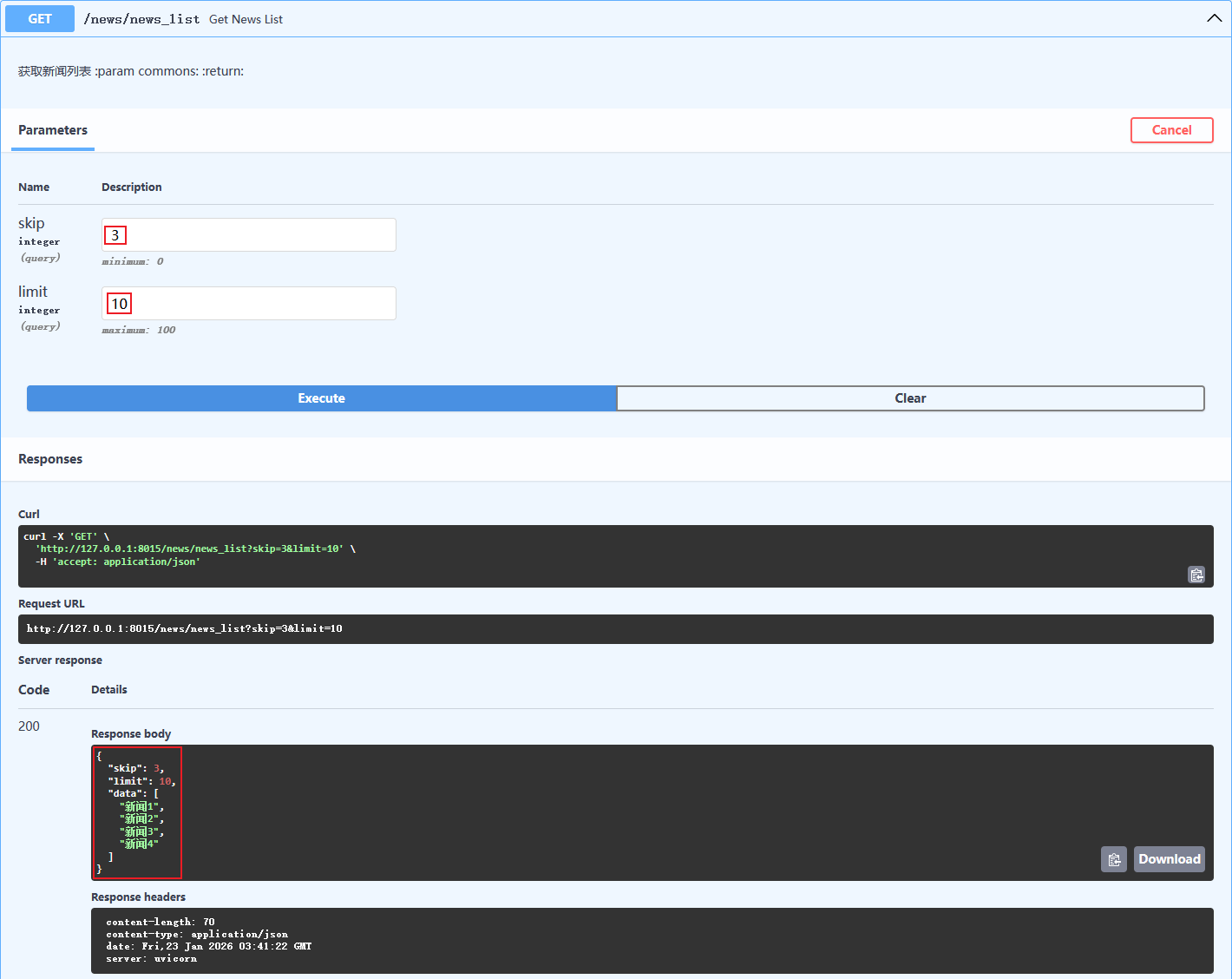
三、ORM 简介
ORM(Object-RelationalMaping,对象关系映射)是一种编程技术,用于在面向对象编程语言和关系型数据库之间建立映射。它允许开发者通过操作对象的方式与数据库进行交互,而无需直接编写复杂的SQL语句。
优势:
- 减少重复的 SQL 代码
- 代码更简洁易读
- 自动处理数据库连接和事务
- 自动防止 SQL 注入攻击
3.1.Python ORM分类
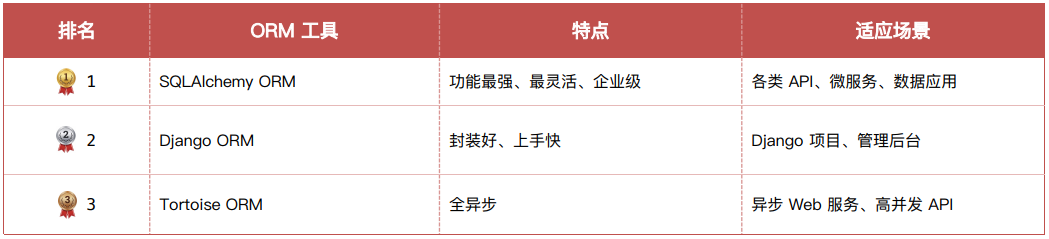
3.2.ORM 使用流程
1.安装
- sqlalchemy[asyncio]
- aiomysql(异步数据库驱动)
pip install sqlalchemy[asyncio]
pip install aiomysql
2.建库、建表
- run_sync(Base.metadta.create_al)
3.操作数据
- 查询
- 新增
- 修改
- 删除
3.3.建表
3.3.1.ORM - 创建数据库引擎
使用 create_async_engine 创建异步引擎
from sqlalchemy.ext.asyncio import create_async_engine ASYNC_DATABASE_URL = "mysql+aiomysql://root:123456@localhost:3306/fastapi_test?charset=utf8" # 创建异步引擎 async_engine = create_async_engine( ASYNC_DATABASE_URL, echo=True, # 可选:输出SQL日志 pool_size=10, # 设置连接池中保持的持久连接数 max_overflow=20, # 设置连接池运行创建的额外连接数 )
3.3.2.ORM - 定义模型类
1.基类,继承 DeclartiveBase(包含通用属性和字段的映射)
2.定义数据库表对应的模型类
# 2.定义模型类:基类+表 对应的模型类 class Base(DeclarativeBase): """ 声明式基类,所有数据模型都集成此类 """ create_time: Mapped[datetime] = mapped_column(DateTime, insert_default=func.now(), default=datetime.now, comment="创建时间") update_time: Mapped[datetime] = mapped_column(DateTime, insert_default=func.now(), onupdate=datetime.now(), default=datetime.now, comment="更新时间") # class Book(Base): __tablename__ = "book" id: Mapped[int] = mapped_column(primary_key=True, comment="编号") title: Mapped[str] = mapped_column(String(255), comment="书名") author: Mapped[str] = mapped_column(String(255), comment="作者") # Numeric(10, 2) 是 SQLAlchemy 中的数据库列类型,Numeric(10, 2) 是 SQLAlchemy 中的数据库列类型,特别适用于金额、价格等对精度要求高的数值 price: Mapped[Decimal] = mapped_column(Numeric(10, 2), comment="价格") publisher: Mapped[str] = mapped_column(String(255), comment="出版社") # ⚠️ 注意:create_time 和 update_time 已在 Base 中定义,此处自动继承
3.3.3.ORM - 创建数据库表
1.从连接池获取异步连接,开启事务,执行 ORM 操作
2.FastAPI 应用启动时,创建数据库表
from datetime import datetime from decimal import Decimal from sqlalchemy import DateTime, func, String, Float, Engine, Numeric from sqlalchemy.ext.asyncio import create_async_engine from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column from fastapi import FastAPI, Query, Depends # 导入 Depends # 创建FastAPI实例 app = FastAPI() # 1.创建异步数据库连接 URL (MySQL + aiomysql 驱动) # 格式:mysql+aiomysql://用户名:密码@主机:端口/数据库?charset=utf8mb4 ASYNC_DATABASE_URL = "mysql+aiomysql://root:123456@localhost:3306/fastapi_test?charset=utf8mb4" # 创建异步引擎 async_engine = create_async_engine( ASYNC_DATABASE_URL, echo=True, # 可选:输出SQL日志输出(调试用,生产环境需要关闭) pool_size=10, # 设置连接池中保持的持久连接数(默认5) max_overflow=20, # 设置连接池运行创建的额外连接数, 超过pool_size的连接数, 创建新的连接数,超过max_overflow的连接数,则拒绝连接 ) # 2.定义模型类:基类+表 对应的模型类 class Base(DeclarativeBase): """ 声明式基类,所有数据模型都集成此类 """ create_time: Mapped[datetime] = mapped_column(DateTime, insert_default=func.now(), default=datetime.now, comment="创建时间") update_time: Mapped[datetime] = mapped_column(DateTime, insert_default=func.now(), onupdate=datetime.now(), default=datetime.now, comment="更新时间") # 表对应的模型 class Book(Base): __tablename__ = "book" id: Mapped[int] = mapped_column(primary_key=True, comment="编号") title: Mapped[str] = mapped_column(String(255), comment="书名") author: Mapped[str] = mapped_column(String(255), comment="作者") # Numeric(10, 2) 是 SQLAlchemy 中的数据库列类型,Numeric(10, 2) 是 SQLAlchemy 中的数据库列类型,特别适用于金额、价格等对精度要求高的数值 price: Mapped[Decimal] = mapped_column(Numeric(10, 2), comment="价格") publisher: Mapped[str] = mapped_column(String(255), comment="出版社") # ⚠️ 注意:create_time 和 update_time 已在 Base 中定义,此处自动继承 async def create_tables(): """ 定义异步函数 create_tables(), 用于创建所有模型对应的数据库表 :return: """ # 使用异步殷勤开启事务连接conn # begin() 确保DDL 操作在事务中执行(MySQL支持事务) async with async_engine.begin() as conn: # run_sync 是关键:在异步上下文中同步调用SQLAlchemy的DDL方法 # Base.metadata.create_all 会创建所有继承自 Base 的表(如果不存在则会创建) await conn.run_sync(Base.metadata.create_all) # FastAPI 启动事件钩子,当应用启动时自动执行建表操作 @app.on_event("startup") async def startup_event(): # 调用创建表函数 await create_tables() @app.get("/") async def root(): return {"message": "Hello World"}
然后重启项目,就可以创建表,执行日志:
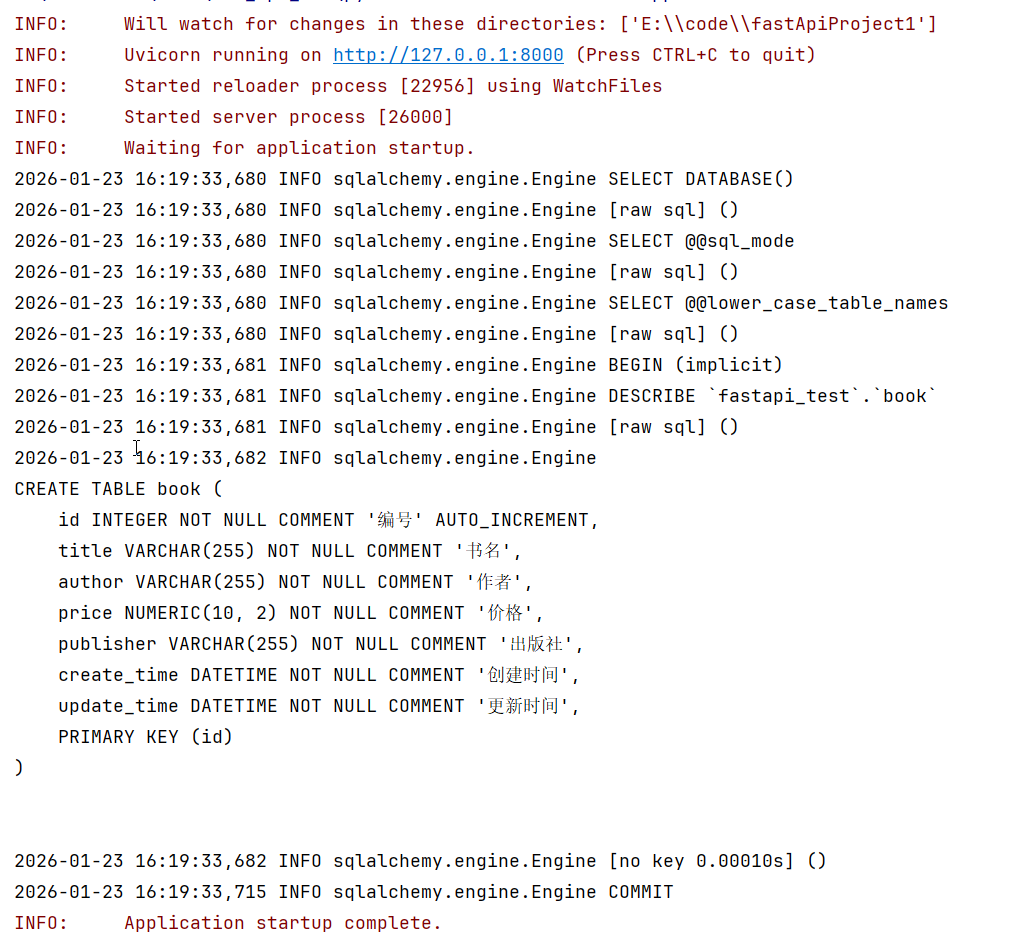
查看创建的表
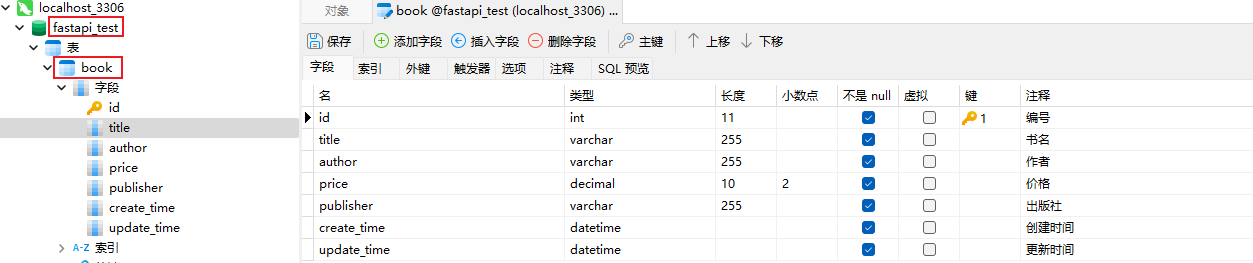
3.4.ORM-路由匹配中使用ORM
ORM - 路由匹配中使用 ORM
核心:创建依赖项,使用 Depnds 注入到处理函数

完整代码:
from datetime import datetime from decimal import Decimal from sqlalchemy import DateTime, func, String, Numeric, select from sqlalchemy.ext.asyncio import create_async_engine, async_sessionmaker, AsyncSession from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column from fastapi import FastAPI, Query, Depends # 导入 Depends # 创建FastAPI实例 app = FastAPI() # 1.创建异步数据库连接 URL (MySQL + aiomysql 驱动) # 格式:mysql+aiomysql://用户名:密码@主机:端口/数据库?charset=utf8mb4 ASYNC_DATABASE_URL = "mysql+aiomysql://root:123456@localhost:3306/fastapi_test?charset=utf8mb4" # 创建异步引擎 async_engine = create_async_engine( ASYNC_DATABASE_URL, echo=True, # 可选:输出SQL日志输出(调试用,生产环境需要关闭) pool_size=10, # 设置连接池中保持的持久连接数(默认5) max_overflow=20, # 设置连接池运行创建的额外连接数, 超过pool_size的连接数, 创建新的连接数,超过max_overflow的连接数,则拒绝连接 ) # 2.定义模型类:基类+表 对应的模型类 class Base(DeclarativeBase): """ 声明式基类,所有数据模型都集成此类 """ create_time: Mapped[datetime] = mapped_column(DateTime, insert_default=func.now(), default=datetime.now, comment="创建时间") update_time: Mapped[datetime] = mapped_column(DateTime, insert_default=func.now(), onupdate=datetime.now(), default=datetime.now, comment="更新时间") # 表对应的模型 class Book(Base): __tablename__ = "book" id: Mapped[int] = mapped_column(primary_key=True, comment="编号") title: Mapped[str] = mapped_column(String(255), comment="书名") author: Mapped[str] = mapped_column(String(255), comment="作者") # Numeric(10, 2) 是 SQLAlchemy 中的数据库列类型,Numeric(10, 2) 是 SQLAlchemy 中的数据库列类型,特别适用于金额、价格等对精度要求高的数值 price: Mapped[Decimal] = mapped_column(Numeric(10, 2), comment="价格") publisher: Mapped[str] = mapped_column(String(255), comment="出版社") # ⚠️ 注意:create_time 和 update_time 已在 Base 中定义,此处自动继承 async def create_tables(): """ 定义异步函数 create_tables(), 用于创建所有模型对应的数据库表 :return: """ # 使用异步殷勤开启事务连接conn # begin() 确保DDL 操作在事务中执行(MySQL支持事务) async with async_engine.begin() as conn: # run_sync 是关键:在异步上下文中同步调用SQLAlchemy的DDL方法 # Base.metadata.create_all 会创建所有继承自 Base 的表(如果不存在则会创建) await conn.run_sync(Base.metadata.create_all) # FastAPI 启动事件钩子,当应用启动时自动执行建表操作 @app.on_event("startup") async def startup_event(): # 调用创建表函数 await create_tables() @app.get("/") async def root(): return {"message": "Hello World"} # 创建异步会话工厂 AsyncSessionLocal = async_sessionmaker( bind=async_engine, # 绑定异步数据库连接引擎 class_=AsyncSession, # 指定会话类 expire_on_commit=False, # 会话对象如果不过期,则不重新查询数据库 ) # 创建依赖项 async def get_database(): async with AsyncSessionLocal() as session: try: yield session # 返回数据库会话给路由处理函数 await session.commit() # 提交事务 except Exception as e: await session.rollback() # 遇到异常,回滚事务 raise e finally: await session.close() # 关闭会话 @app.get("/book/books") async def get_book_list(author: str = Query(None, description="作者名称,可选参数"),db: AsyncSession = Depends(get_database)): """ 查询所有书籍信息 :param db: :return: """ query = select(Book) # 如果提供了作者参数,则添加查询条件 if author: query = query.where(Book.author == author) # 执行查询 result = await db.execute(query) # 获取查询结果, scalars()将每行数据(Row 对象)转换为具体的实体对象(这里是 Book 对象),all 获取所有查询结果并返回为 Python 列表 books = result.scalars().all() return books
- 不指定作者,则是查询所有信息

- 查询指定作者的书籍信息
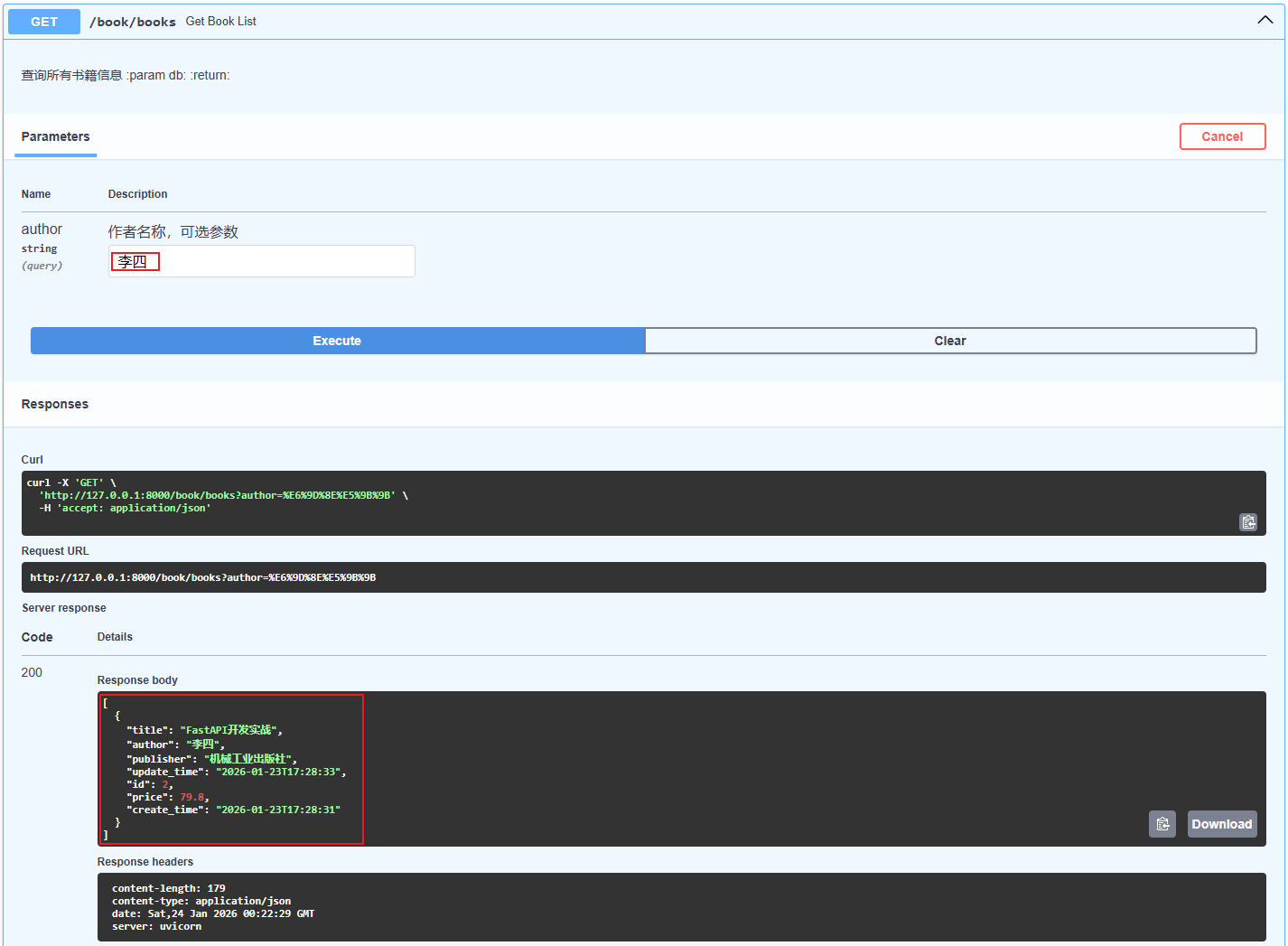
3.5.数据库操作
数据库查询操作:
select()
核心语句:await db.execute(select(模型类)),返回一个 ORM 对象
1.获取所有数据
- scalars().all()
2.获取单条数据
- scalars().first()
- get(模型类, 主键值)
3.5.1.数据库操作-查询条件
语法:
select(Book).where(条件, 条件2, .)
条件:
- 比较判断:==、> 、<、>=、<= 等
- 模糊查询:like()
- 与非查询:&、|、 ~
- 包含查询:in_()
3.5.2.查询条件-比较判断
比较判断:==、> 、<、>=、<= 等
scalars() 方法
- 作用: 将查询结果转换为标量结果集,返回 ScalarResult 对象
- 功能: 将每一行数据(Row 对象)转换为具体的实体对象
- 返回类型: ScalarResult 对象,可继续调用其他方法获取数据
scalar_one() 方法
- 作用: 获取单个标量值,如果结果不唯一或没有结果则抛出异常
- 行为:
- 如果查询返回零个结果 → 抛出 NoResultFound 异常
- 如果查询返回多个结果 → 抛出 MultipleResultsFound 异常
- 如果查询返回一个结果 → 返回该结果的标量值
- 适用场景: 确定期望只有一个结果的情况
scalar_one_or_none() 方法
- 作用: 获取单个标量值,如果没有结果则返回 None
- 行为:
- 如果查询返回零个结果 → 返回 None
- 如果查询返回多个结果 → 抛出 MultipleResultsFound 异常
- 如果查询返回一个结果 → 返回该结果的标量值
- 适用场景: 可能有一个或零个结果的情况
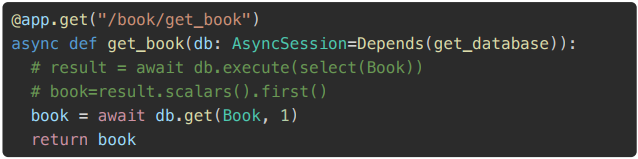
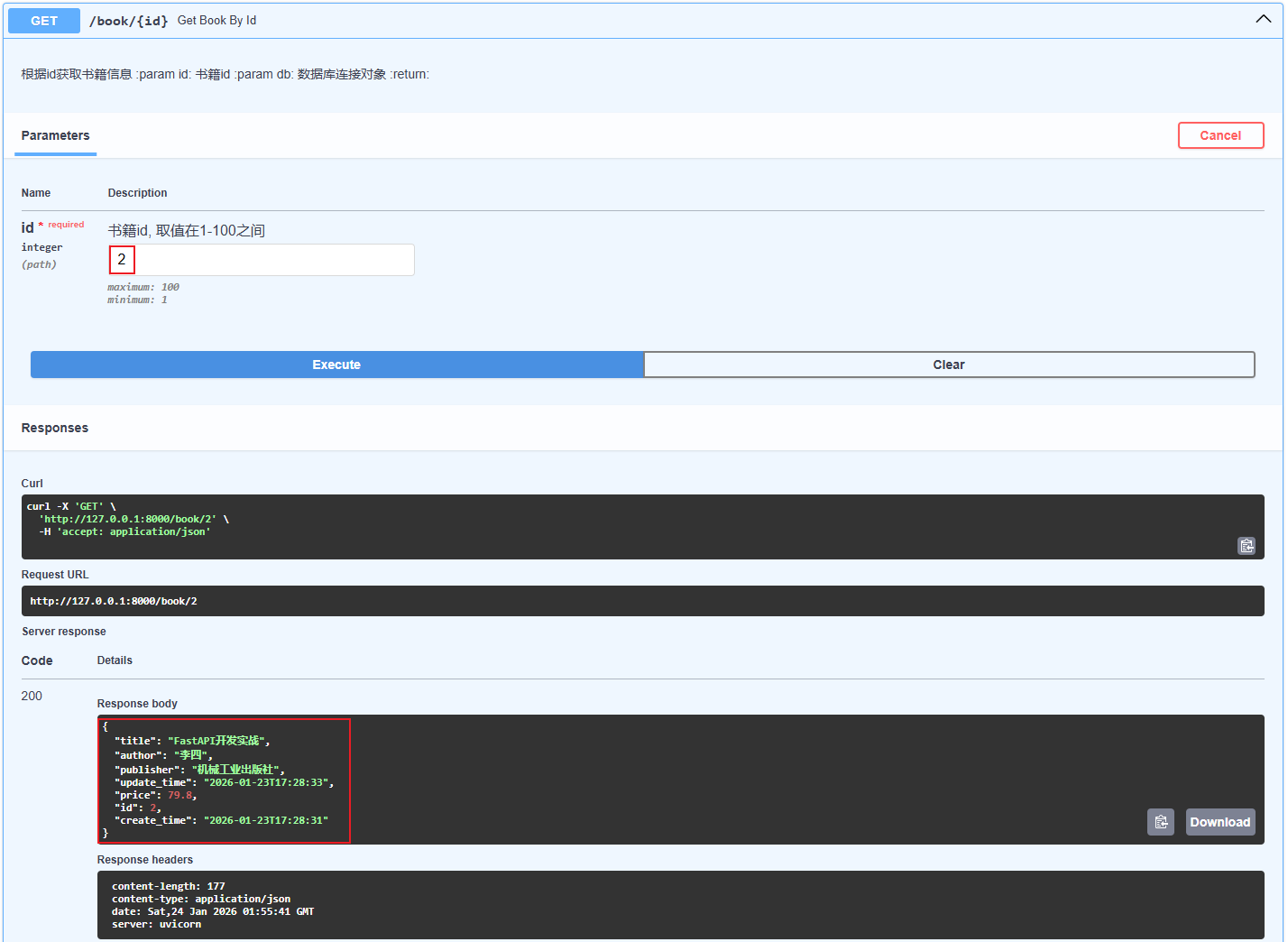
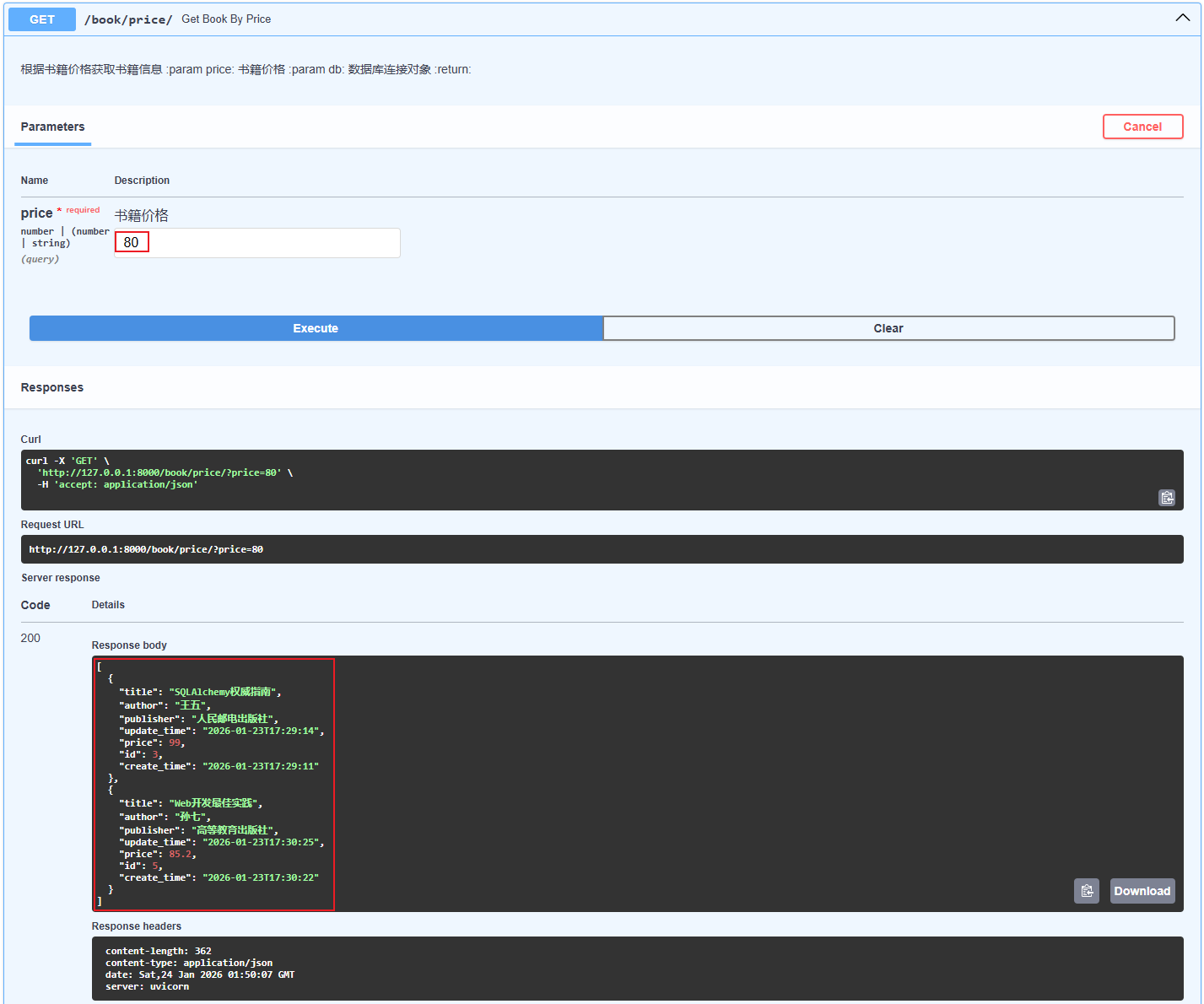
案例:添加根据id查询接口和根据书籍价格获取书籍信息
# 根据id获取书籍信息 @app.get("/book/{id}") async def get_book_by_id( id: int = Path(..., ge=1, le=100, description="书籍id, 取值在1-100之间"), db: AsyncSession = Depends(get_database)): """ 根据id获取书籍信息 :param id: 书籍id :param db: 数据库连接对象 :return: """ # db.get() 适合根据主键直接查询单个实体 # book = await db.get(Book, id) # 获取单条数据,通过id查询 # db.execute() 适合复杂查询条件,多字段筛选关联查询,需要聚合函数的查询, 返回查询结果对象,还需要进一步处理才能获取实体 result = await db.execute(select(Book).where(Book.id == id)) book = result.scalar_one_or_none() # 获取单条数据, scalar_one_or_none()表示获取单条数据,如果结果为空则返回None return book # 根据书籍价格获取书籍信息 @app.get("/book/price/") async def get_book_by_price( price: Decimal = Query(..., description="书籍价格"), db: AsyncSession = Depends(get_database) ): """ 根据书籍价格获取书籍信息 :param price: 书籍价格 :param db: 数据库连接对象 :return: """ # 根据书籍价格查询 result = await db.execute(select(Book).where(Book.price >= price)) # 获取查询结果, scalars()将每行数据(Row 对象)转换为具体的实体对象(这里是 Book 对象),all 获取所有查询结果并返回为 Python 列表 books = result.scalars().all() return books
执行
- 根据id查询
- 根据价格查询
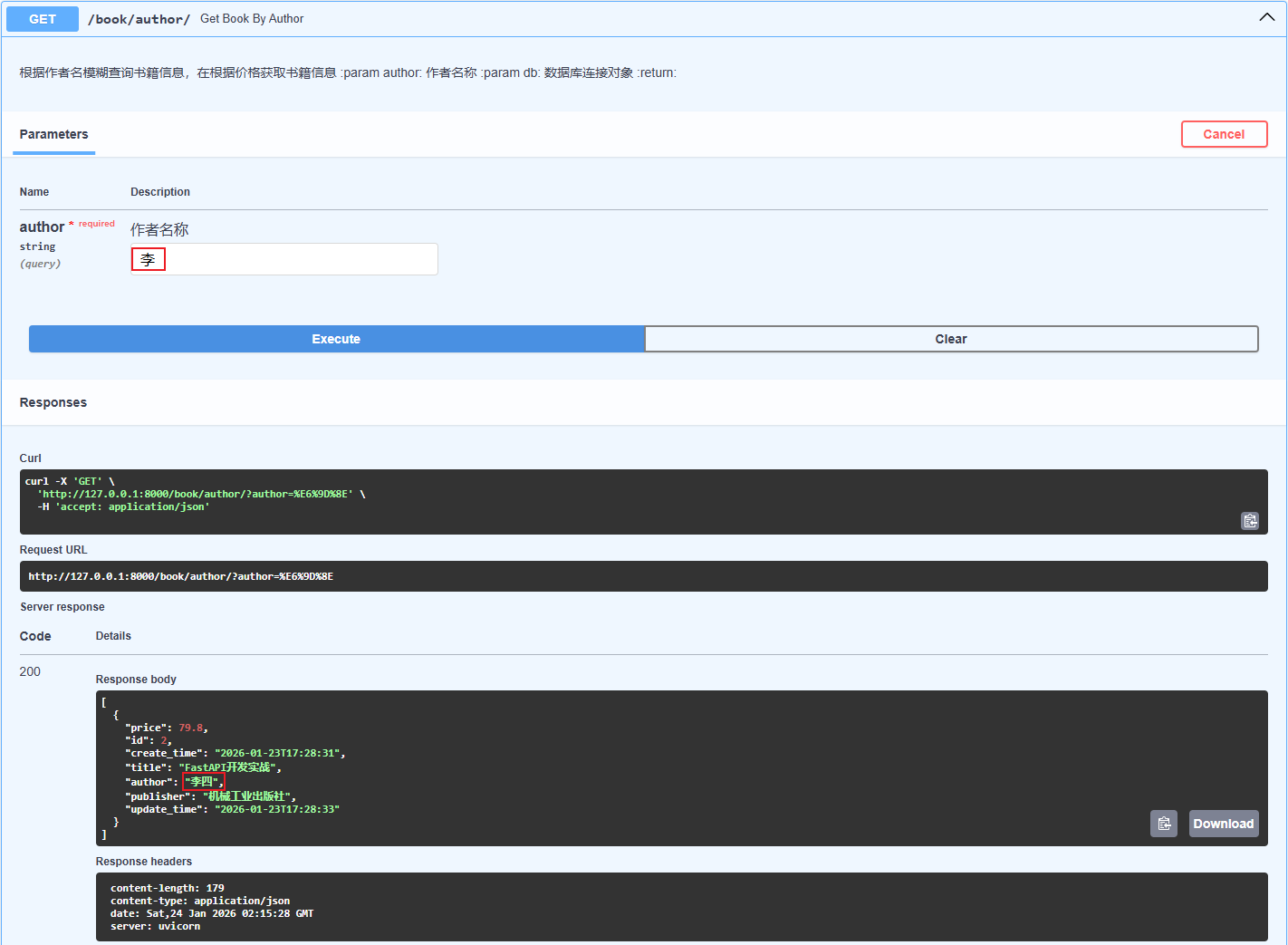
3.5.2.查询条件-模糊查询
模糊查询:like()
- %:零个、一个或多个字符
- _:一个单个字符
案例:
# 根据作者名模糊查询书籍信息 @app.get("/book/author/") async def get_book_by_author( author: str = Query(..., description="作者名称"), db: AsyncSession = Depends(get_database) ): """ 根据作者名模糊查询书籍信息,在根据价格获取书籍信息 :param author: 作者名称 :param db: 数据库连接对象 :return: """ # 根据作者名模糊查询 # 模糊查询使用 like() 方法: % 表示任意字符,_ 表示任意单个字符 result = await db.execute(select(Book).where(Book.author.like(f"%{author}%"))) # 获取查询结果, scalars()将每行数据(Row 对象)转换为具体的实体对象(这里是 Book 对象),all 获取所有查询结果并返回为 Python 列表 books = result.scalars().all()return books
- 查询作者名字包含李字的书籍信息
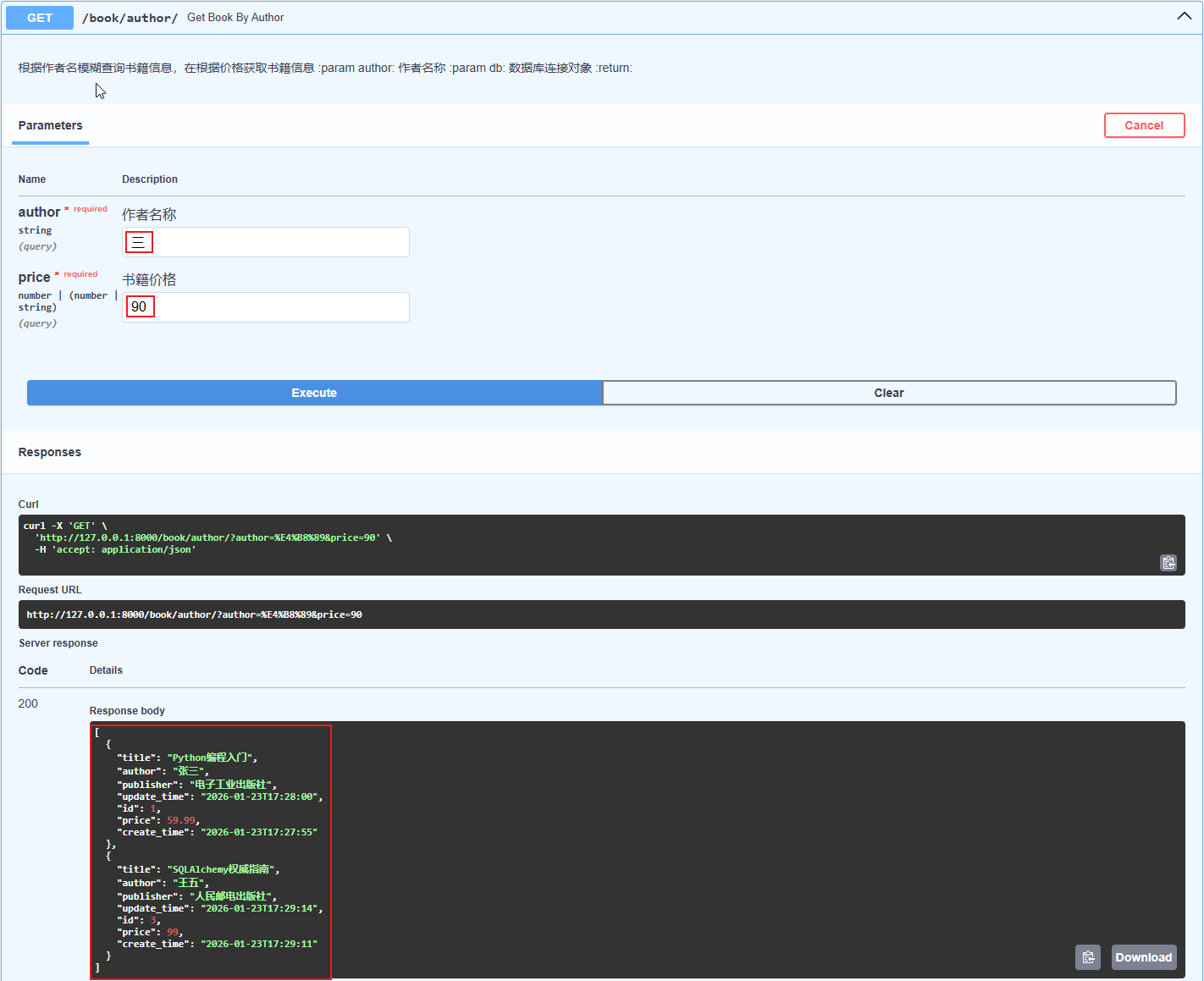
3.5.3.查询条件-与非查询
说明:
- &:与,& 表示 AND 运算符
- |:或,| 表示 OR 运算符
- ~:非 , ~ 表示 NOT 运算符
# 根据作者名模糊查询书籍信息,或者根据价格获取书籍信息 @app.get("/book/author/") async def get_book_by_author( author: str = Query(..., description="作者名称"), price: Decimal = Query(..., description="书籍价格"), db: AsyncSession = Depends(get_database) ): """ 根据作者名模糊查询书籍信息,在根据价格获取书籍信息 :param author: 作者名称 :param db: 数据库连接对象 :return: """ # 根据作者名模糊查询 # 模糊查询使用 like() 方法: % 表示任意字符,_ 表示任意单个字符 #result = await db.execute(select(Book).where(Book.author.like(f"%{author}%"))) # 获取查询结果, scalars()将每行数据(Row 对象)转换为具体的实体对象(这里是 Book 对象),all 获取所有查询结果并返回为 Python 列表 # books = result.scalars().all() # 运算符: & 表示 AND 运算符, | 表示 OR 运算符, ~ 表示 NOT 运算符 result = await db.execute(select(Book).where((Book.author.like(f"%{author}%")) | (Book.price >= price))) books = result.scalars().all()return books
- 查询书籍作者包含“三”,或者价格大于90的书籍
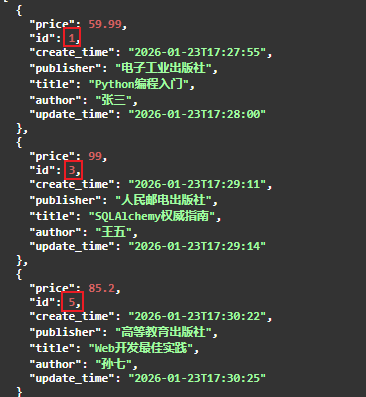
3.5.4.查询条件-包含查询
包含查询:
- in_() 表示 IN 运算符
- not_in() 表示 NOT IN 运算符
# 根据作者名模糊查询书籍信息,在根据价格获取书籍信息 @app.get("/book/author/") async def get_book_by_author(db: AsyncSession = Depends(get_database)): """ :param db: 数据库连接对象 :return: """ # 运算符: in_() 表示 IN 运算符, not_in() 表示 NOT IN 运算符 ids = [1, 3, 5, 7] result = await db.execute(select(Book).where(Book.id.in_(ids))) # books = result.scalars().all() return books
3.5.5.数据库操作-聚合查询
聚合计算:func.方法(模型类.属性)
- count:统计行数量
- avg:求平均值
- max:求最大值
- min:求最小值
- sum:求和
方法说明:
result.scalar_one_or_none()
- 返回值类型: 返回单个标量值(非元组)
- 适用场景: 当查询只返回单个值时使用
result.one()
- 返回值类型: 返回单行结果,结果是一个元组
- 适用场景: 当查询返回多个列(聚合函数组合)时使用
# 计算书籍的总价格、平均价格、最高价格、最低价格,统计书籍数量 @app.get("/book/statistics/") async def get_book_statistics(db: AsyncSession = Depends(get_database)): """ :param db: 数据库连接对象 :return: """ result = await db.execute(select( func.count(Book.id), func.coalesce(func.sum(Book.price), 0), # coalesce() 函数用于处理 NULL 值,如果第一个参数为 NULL,则返回第二个参数的值 func.coalesce(func.avg(Book.price), 0), # avg() 函数用于计算平均值, 如果第一个参数为 NULL,则返回0 func.coalesce(func.max(Book.price), 0), # max() 函数用于返回最大值, 如果第一个参数为 NULL,则返回0 func.coalesce(func.min(Book.price), 0) # min() 函数用于返回最小值, 如果第一个参数为 NULL,则返回0 )) # result.scalar_one_or_none() statistics = result.one() if statistics is None: return {"count": 0, "sum": 0, "avg": 0, "max": 0, "min": 0} # 返回统计结果,构造成json, 将Decimal转换为字float, Decimal类型不能被json序列化 return { "count": statistics[0], "sum": float(statistics[1]) if statistics[1] else 0, # Decimal类型转换为float, "avg": float(statistics[2]) if statistics[1] else 0, "max": float(statistics[3]) if statistics[1] else 0, "min": float(statistics[4]) if statistics[1] else 0 }
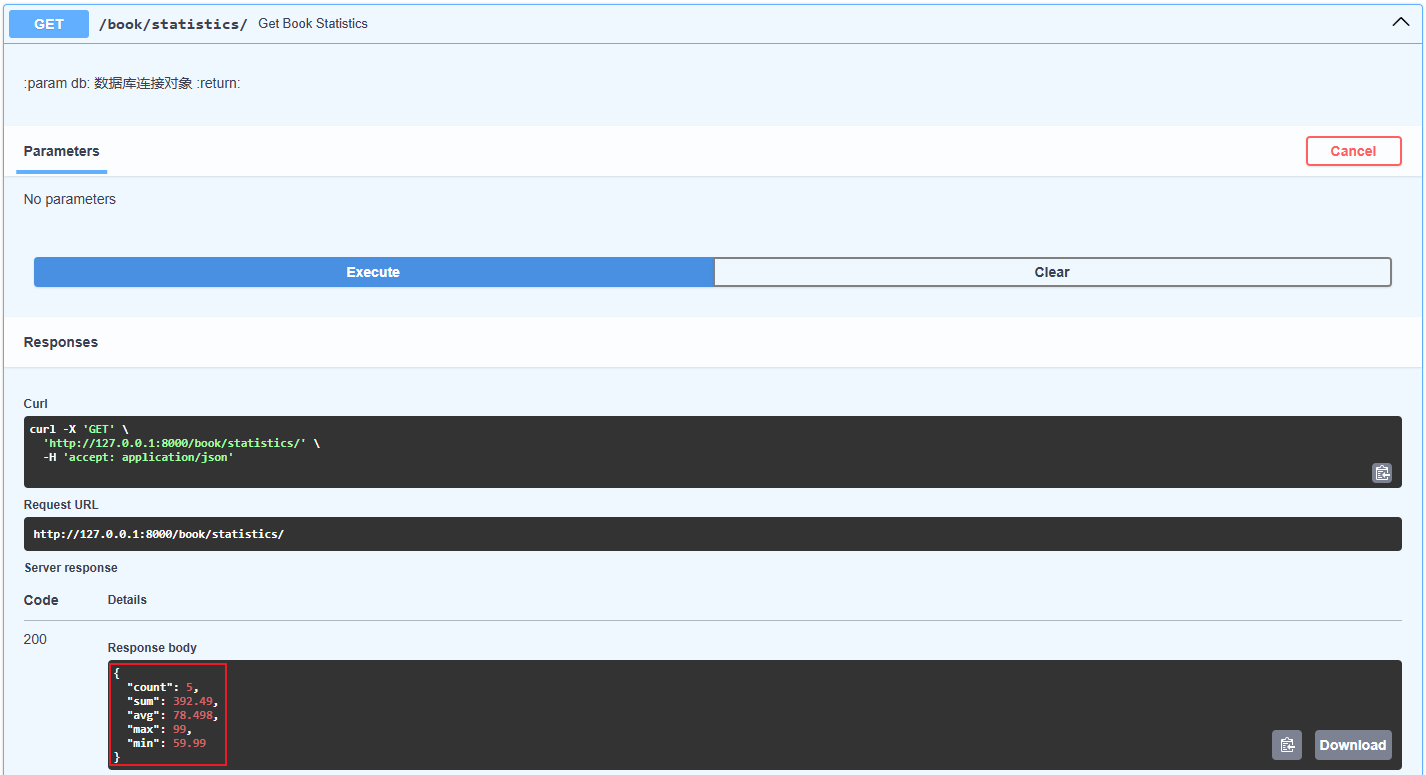
3.5.6.数据库操作-分页查询
分页查询:select().offset().limit()
- offset:跳过的记录数
- limit:返回的记录数
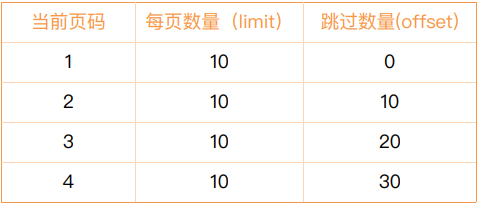
计算公式:
offset值 = (当前页码-1)* 每页数量 limit
案例代码:
# 分页查询:获取书籍列表 @app.get("/book/page/list") async def get_book_page_list( page_num: int = Query(1, ge=1, description="页码,大于等于1的整数"), page_size: int = Query(10, ge=1, le=100, description="每页显示的记录数,范围1-100"), # 分页查询,每页显示的记录数,le=100表示最大值100 db: AsyncSession = Depends(get_database)): """ 分页查询:获取书籍列表 :param page_num: 页码,大于等于1的整数 :param limit: 每页显示的记录数 :param db: 数据库连接对象 :return: """ # 跳过的记录数,也就是offset: offset值 = (当前页码-1)* 每页数量 limit skip = (page_num - 1) * page_size # offset() 函数用于指定跳过的记录数, limit() 每页的记录数 sql = select(Book).offset(skip).limit(page_size) result = await db.execute(sql) # 执行查询 # 获取查询结果, scalars()将每行数据(Row 对象)转换为具体的实体对象(这里是 Book 对象),all 获取所有查询结果并返回为 Python 列表 books = result.scalars().all() return books
执行:
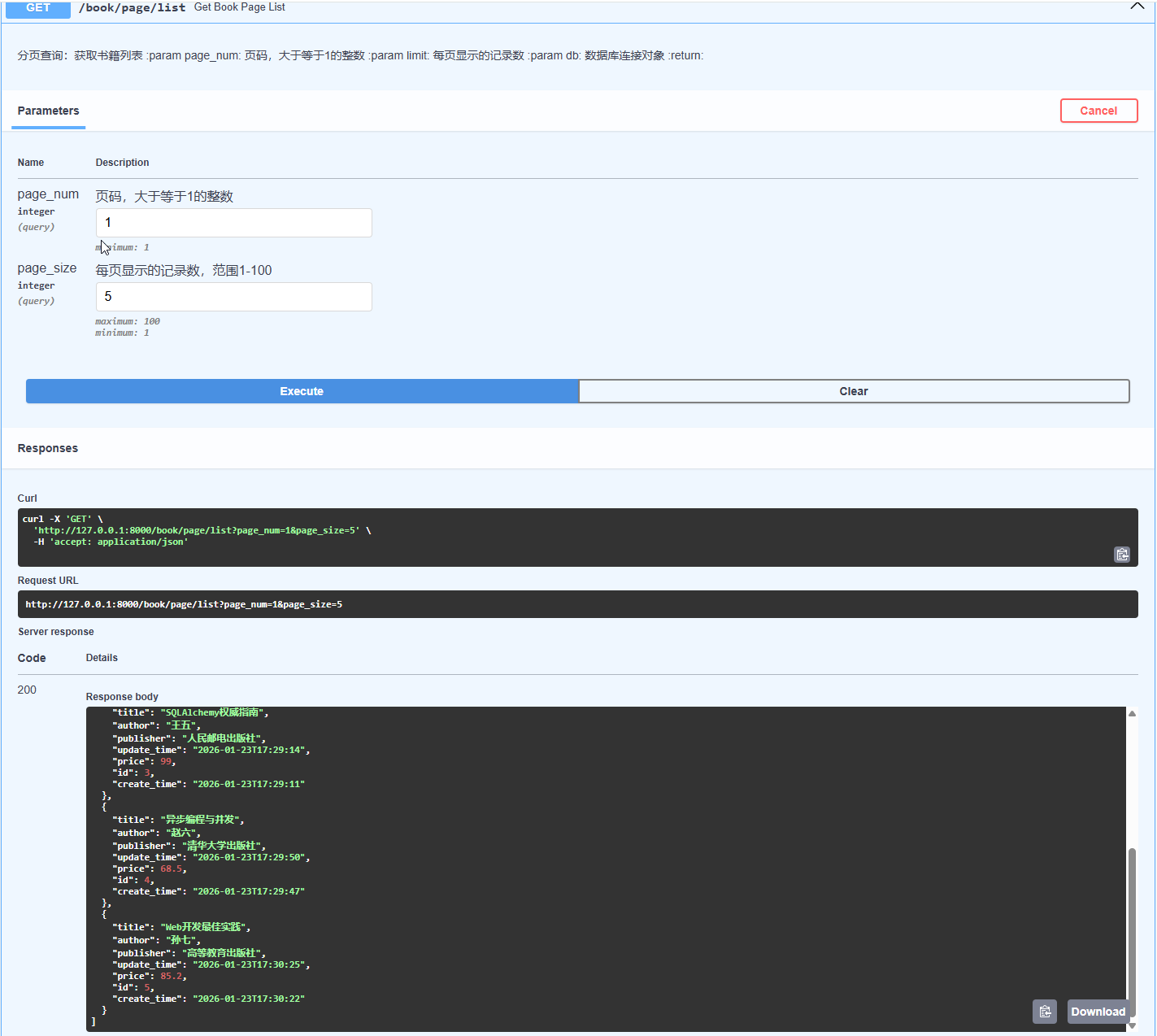
3.6.数据库操作-新增
核心步骤:定义 ORM 对象 → 添加对象到事务:add(对象) → commit 提交到数据库
@app.post("/book/add/book") async def add_book(book: BookBase, db: AsyncSession = Depends(get_database)): """ 添加书籍 :param book: 书籍信息 :param db: 数据库连接对象 :return: """ # 1.ORM对象-> 2.add -> 3.提交事务 # 方法一:使用 dict 更新 book_obj = Book(**book.__dict__) # 不需要转换数据类型可以直接使用 # 方式二:显式字段映射 # book_obj = Book( # title=book.title, # author=book.author, # price=Decimal(book.price), # Decimal类型, 需要转换数据类型 # publisher=book.publisher # ) # 添加书籍 db.add(book_obj) await db.commit() # 提交事务 return {"message": "添加成功", "code": 200, "data": book_obj}
- 执行接口:
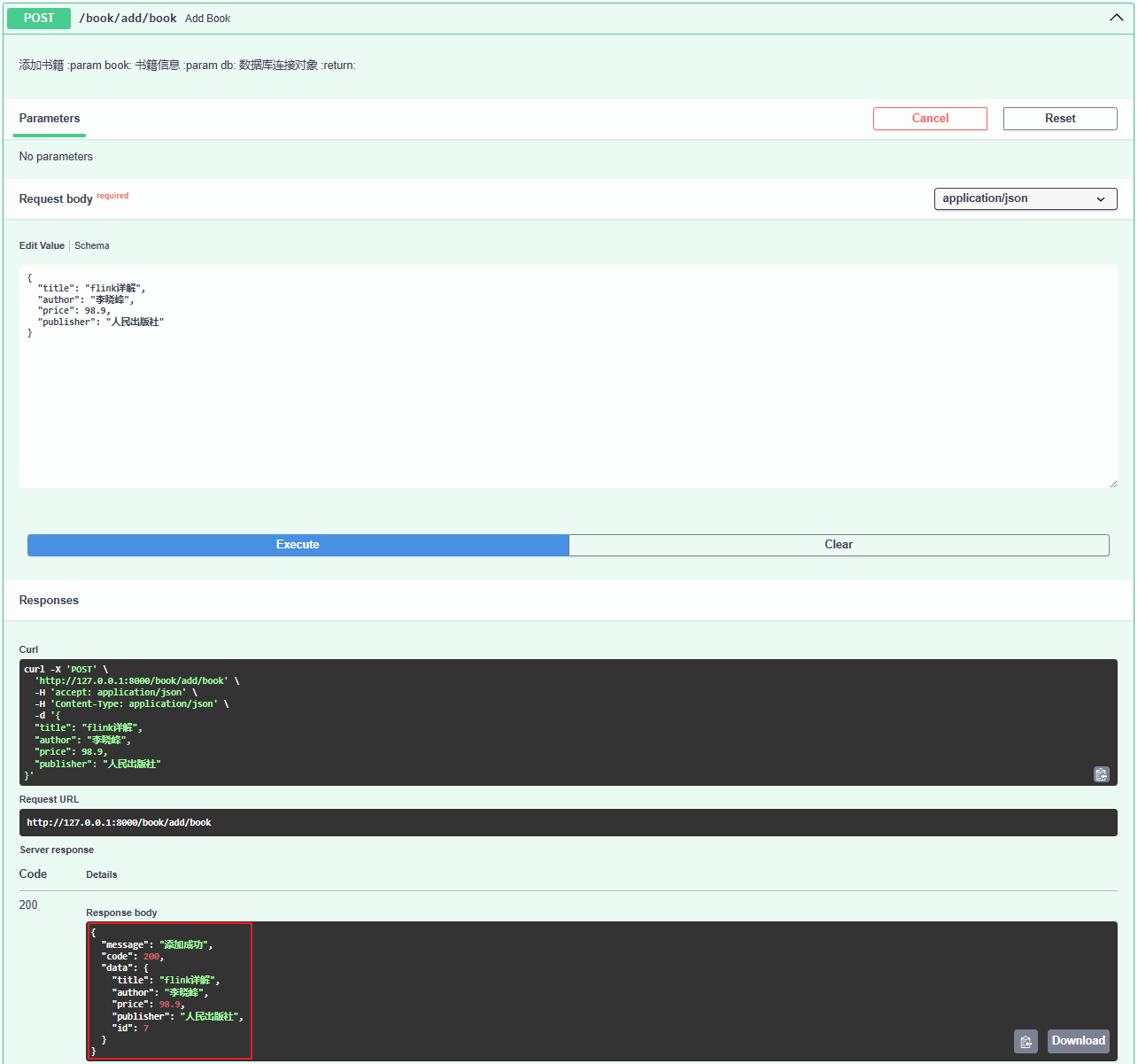
- 查看数据已经插入:
3.7.数据库操作-更新
核心步骤:查询 get → 属性重新赋值 → commit 提交到数据库
class BookBase(BaseModel): """ 书籍信息 BookBase 类 - Pydantic模型 类型:Pydantic 数据验证模型 继承关系:继承自 BaseModel 用途:用于API请求数据验证和序列化 特征: 用于接收前端请求数据 提供数据校验功能 不直接对应数据库表 """ title: str author: str price: float publisher: str @app.put("/book/update_book/{book_id}") async def update_book(book_id: int, data: BookBase, db: AsyncSession = Depends(get_database)): """ 更新书籍 :param book_id: 书籍ID :param book: 书籍信息 :param db: 数据库连接对象 :return: """ # 1.查询书籍 book_obj = await db.get(Book, book_id) # 2.判断书籍是否存在,不存在则抛出异常信息 if book_obj is None: raise HTTPException(status_code=404, detail=f"查询{book_id}的书籍不存在") # 3.更新书籍信息:重新赋值 book_obj.title = data.title book_obj.author = data.author book_obj.price = data.price book_obj.publisher = data.publisher # 4.提交事务 await db.commit() return {"message": "更新成功", "code": 200, "data": book_obj}
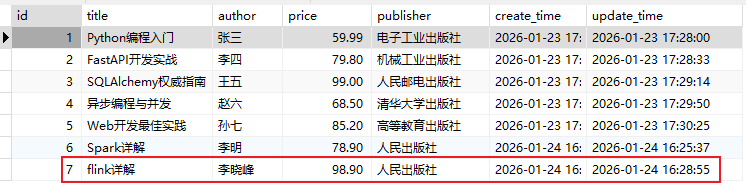
- 修改前数据:

- 执行接口修改id为7的书籍信息:
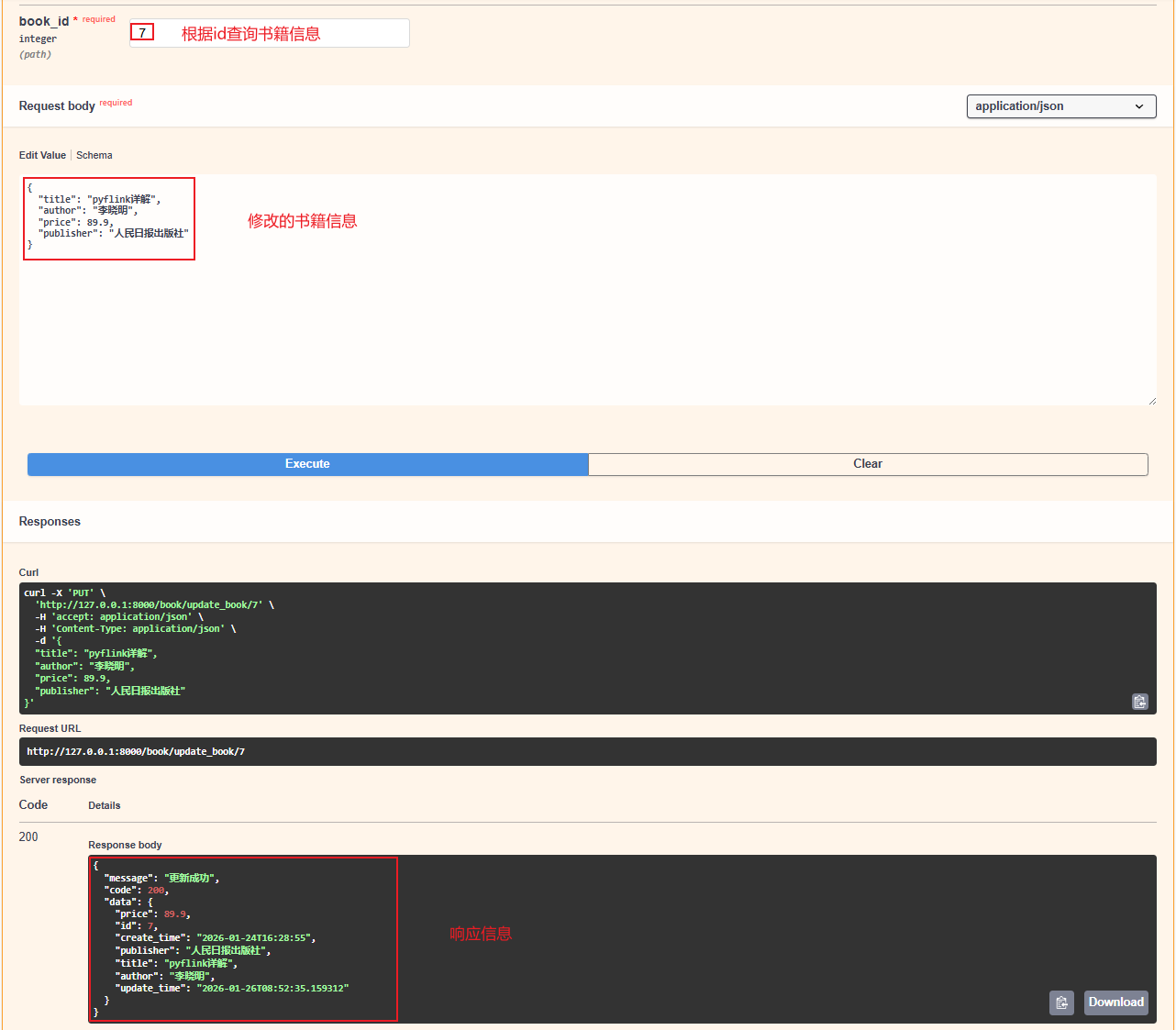
- 修改后信息:

3.8.数据库操作-删除
核心步骤:查询 get → delete 删除 → commit 提交到数据库
@app.delete("/book/delete_book/{book_id}") async def delete_book(book_id: int, db: AsyncSession = Depends(get_database)): """ 删除书籍 :param book_id: 书籍ID :param db: 数据库连接对象 :return: """ # 1.查询书籍 book_obj = await db.get(Book, book_id) # 2.判断书籍是否存在,不存在则抛出异常信息 if book_obj is None: raise HTTPException(status_code=404, detail=f"查询{book_id}的书籍不存在") # 3.删除书籍 await db.delete(book_obj) await db.commit() return {"message": "删除成功", "code": 200, "data": book_obj}
- 执行接口:
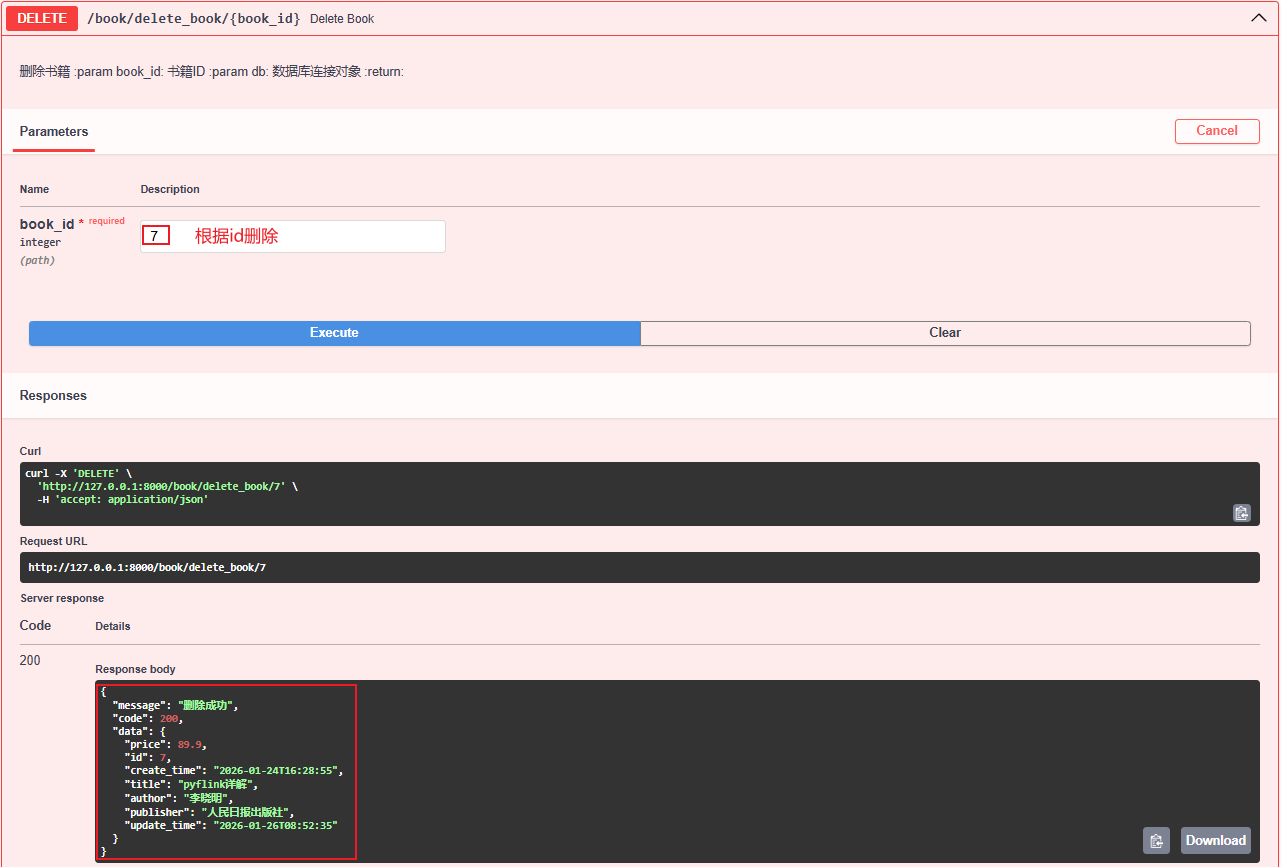
- 查看发现id为7的书籍已经不存在了


 浙公网安备 33010602011771号
浙公网安备 33010602011771号